Gemini 3 vs GPT-5.1 vs Claude Sonnet 4.5: The Ultimate November 2025 AI Model Showdown
November 7, 2025
Meta SAM 3D Launch — Single-Image 3D Reconstruction Changes Everything About Spatial AI
November 11, 2025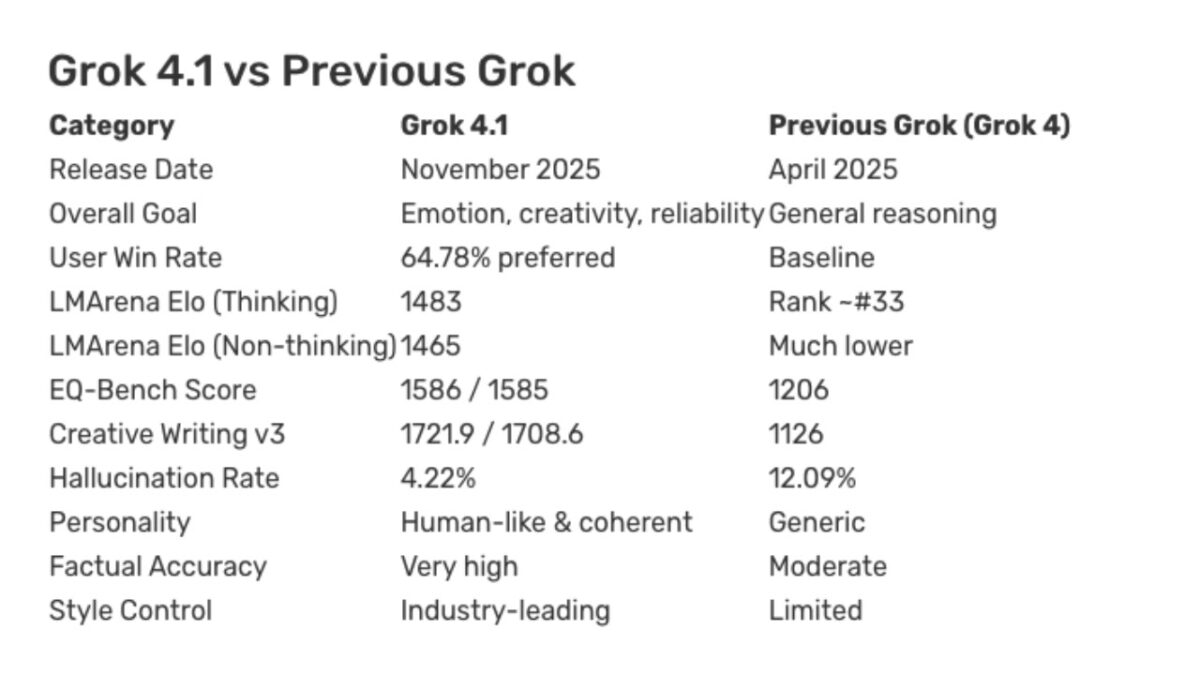
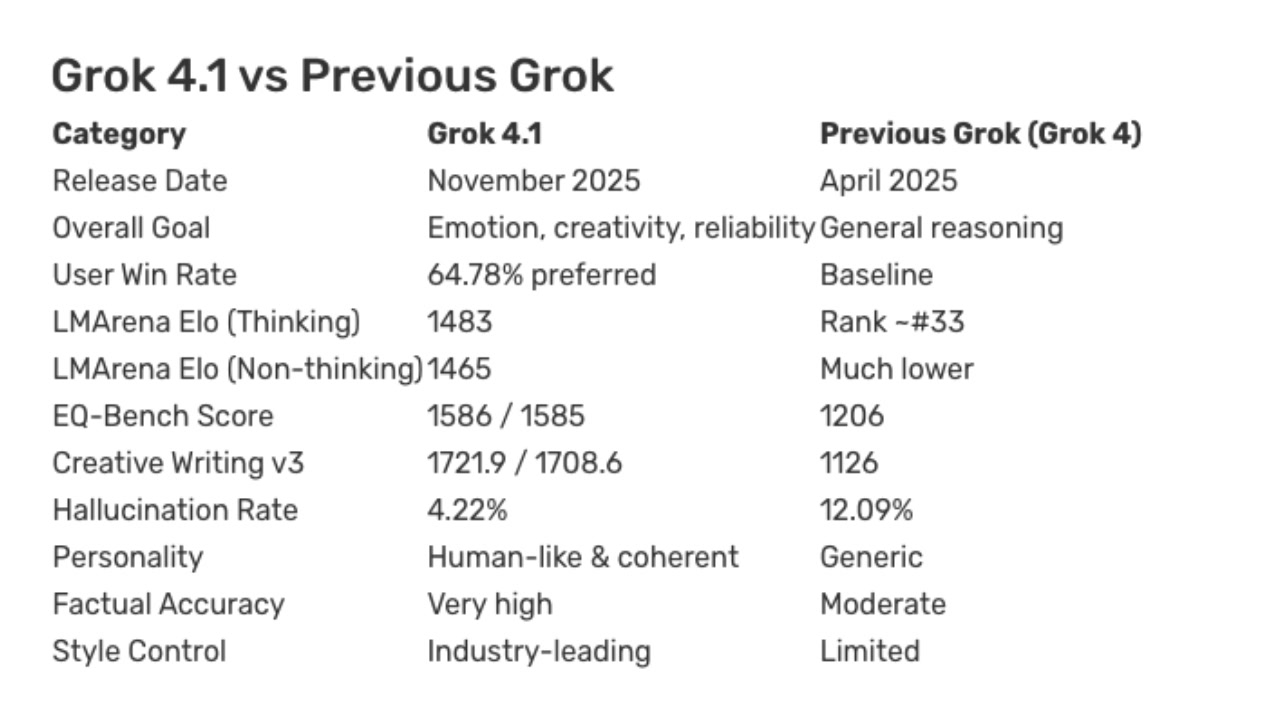
From 12% hallucination rate down to 4.22%. That single number tells you more about where AI is heading than any marketing deck ever could. On November 17, 2025, xAI shipped Grok 4.1 — and it didn’t just tweak a few parameters. It set a new bar for what “reliable AI” should actually look like, backed by two weeks of real-world A/B testing and benchmark results that put it at the top of multiple leaderboards.
What Changed in xAI Grok 4.1
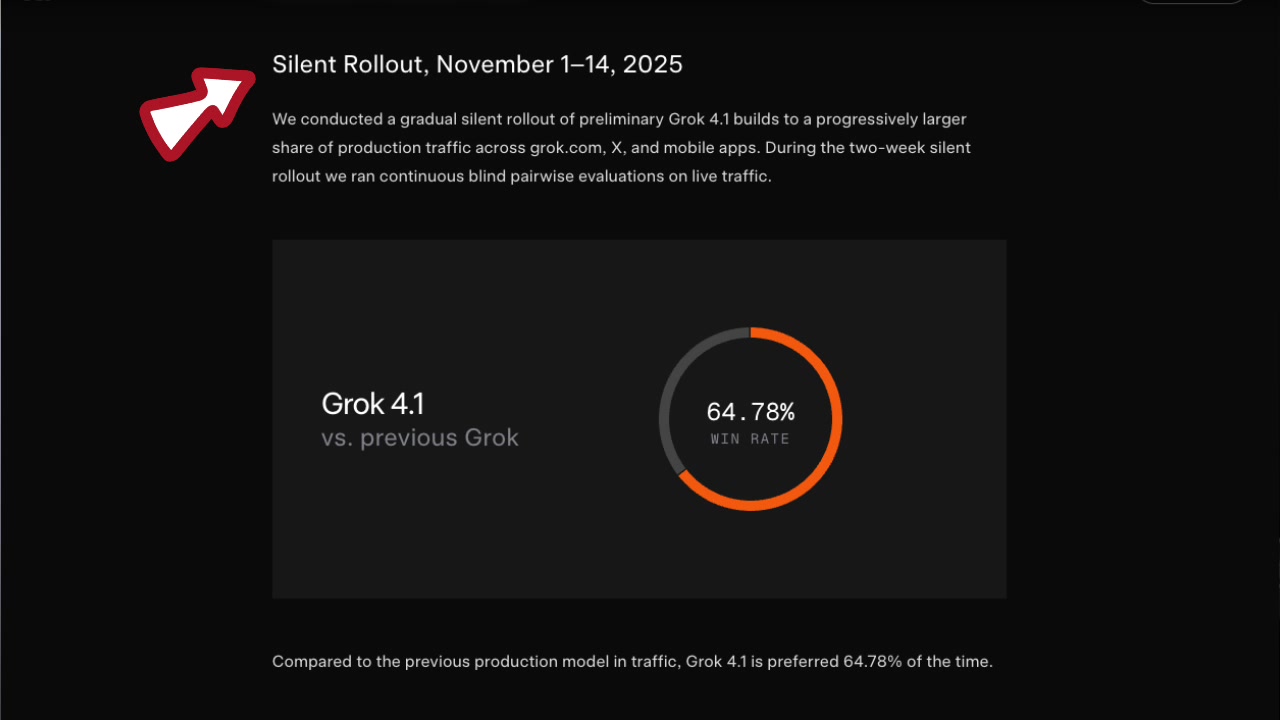
Let me cut straight to what matters. xAI ran A/B testing from November 1 through 14, collecting real user feedback before the public release. This wasn’t a lab-tuned model dropped on the world — it was refined against actual usage patterns over a focused two-week period. The resulting improvements aren’t theoretical; they come from observing where the previous model fell short in real conversations with real users.
The headline number is a 65% reduction in hallucination rate — from roughly 12% on Grok 4 down to 4.22% on Grok 4.1. If you’ve ever had an AI confidently cite a paper that doesn’t exist, fabricate statistics in a report, or invent API endpoints that were never implemented, you understand why this matters. Hallucinations aren’t just errors — they’re lies wearing the mask of confidence. The AI doesn’t say “I’m not sure” — it presents fabricated information with the same authority as verified facts. Getting that rate below 5% puts xAI Grok 4.1 in genuinely elite territory among current LLMs, and it represents a meaningful step toward AI outputs you can trust without verifying every single claim.
The context window expanded to 2 million tokens. To put that in perspective, 2 million tokens is roughly equivalent to 10 full-length novels, or an entire enterprise codebase with documentation. That’s enough to process complete legal contracts, lengthy research papers, or multi-file software projects in a single session. But raw context size is only half the story. What really matters is whether the model can actually use that context effectively — and here, Grok 4.1 delivers impressively.
Context recall accuracy sits at 91%, meaning details mentioned at conversation turn 3 are accurately recalled at turn 14. If you’ve ever watched a chatbot lose track of what you discussed five minutes ago — forcing you to re-explain your requirements or re-paste code you already shared — you know how significant this improvement is. The combination of large context and high recall accuracy creates a fundamentally different user experience: you can have extended, complex conversations without the model losing the thread.
xAI Grok 4.1 Benchmarks: The Numbers That Matter
According to xAI’s official announcement, Grok 4.1 claimed the #1 spot on LM Arena with an Elo rating of 1483. For context, LM Arena (formerly known as Chatbot Arena) uses blind head-to-head comparisons where real users pick the better response without knowing which model generated it. It’s the closest thing we have to a benchmark that reflects actual user experience rather than academic test performance. The Elo system — borrowed from competitive chess — means that a 1483 rating represents consistent superiority across thousands of matchups against every other major model on the platform.
On the emotional intelligence front, Grok 4.1 scored 1586 on EQ-Bench — the highest of any model (in thinking mode). This benchmark doesn’t just test whether an AI can identify basic emotions. It evaluates understanding of complex emotional scenarios: detecting sarcasm, reading between the lines, understanding social dynamics, and interpreting contradictory emotional signals. In practical terms, this means Grok 4.1 is better at understanding what you actually mean, even when you don’t say it perfectly. For applications in customer service, content creation, therapy support tools, and education, this kind of emotional comprehension is the difference between a useful tool and a frustrating one.
The Creative Writing v3 benchmark saw roughly a 600-point improvement over Grok 4. This is noteworthy because creative writing has historically been a weak spot for models that optimize primarily for factual accuracy. It suggests xAI found a way to improve reliability without sacrificing expressiveness — a balance that’s harder to achieve than it sounds. And in direct user preference testing, 64% of users preferred Grok 4.1’s responses over Grok 4. That’s not a marginal edge — it’s a clear, statistically significant preference that suggests users can feel the difference in daily use.
Two Modes: Fast-Response and Multi-Step Thinking
Grok 4.1 ships with two distinct response modes, each designed for different use cases. Fast-Response mode handles everyday queries with minimal latency — quick lookups, translations, summaries, and straightforward Q&A. It strips away unnecessary reasoning overhead to deliver answers as quickly as possible. Multi-Step Thinking mode kicks in for complex reasoning tasks: mathematical proofs, multi-step code debugging, strategic analysis, or any scenario where the model benefits from “thinking out loud” before committing to an answer.
The EQ-Bench top score came from thinking mode, which makes intuitive sense — understanding complex emotional scenarios requires the kind of deliberate reasoning that fast mode is designed to skip. This dual-mode approach is pragmatic engineering, not a marketing gimmick. Running deep chain-of-thought reasoning on every “What’s the weather?” query wastes compute and adds unnecessary latency. Conversely, giving a quick one-shot answer to a nuanced coding problem or architectural decision leads to shallow, error-prone responses.
For developers building on the API, this creates a practical optimization opportunity. You can architect your applications with intelligent routing: fast mode for high-volume, low-complexity requests where speed matters most, and thinking mode for tasks where accuracy is non-negotiable and users expect a considered response. The cost implications are significant too — fast mode consumes fewer tokens and costs less per request, so matching the right mode to the right task directly impacts your API bill.
Grok 4.1 Fast and the Agent Tools API
Two days after Grok 4.1’s launch, xAI released Grok 4.1 Fast on November 19. This model halves the hallucination rate compared to Grok 4 Fast while maintaining comparable response speeds. For developers building latency-sensitive applications — real-time chatbots, autocomplete systems, interactive tools — it significantly narrows the accuracy-speed tradeoff that has plagued API-based AI services. In production environments where millions of requests flow through daily, cutting the per-response error rate in half has a compounding effect on overall system reliability.
But the more strategically interesting move is the Agent Tools API. It provides three native capabilities: web_search for real-time internet queries, x_search for querying X (formerly Twitter) data, and code_execution for running code in a sandboxed environment. This lets AI agents perform actions in the real world — searching for current information, analyzing social media trends, and executing and testing code — all natively within the Grok ecosystem, without needing third-party tool integrations.
The pricing is deliberately aggressive: up to 50% off existing rates, with a hard cap of $5 per 1,000 tool calls. That cap is particularly important. When AI agents autonomously decide when and how to use tools, unpredictable cost spikes are a real operational risk. By setting a ceiling, xAI is making it feasible for developers to build agents that use tools liberally without fear of runaway bills. It’s the kind of developer-friendly pricing decision that wins ecosystems.
The strategic intent behind all of this is transparent. xAI is going after the developer ecosystem that OpenAI and Anthropic currently dominate. Their weapons? Price competitiveness combined with exclusive data access. The x_search tool is particularly noteworthy — no other LLM provider offers native access to real-time social media data from a major platform. If you’re building agents that need pulse-of-the-moment social data — trend monitoring, real-time sentiment analysis, social listening tools, crisis detection systems — this is currently a capability you simply cannot replicate with other providers. It’s a genuine competitive moat, at least for now.
What xAI Grok 4.1 Means for the AI Landscape
From a practitioner’s perspective, the most consequential improvements in Grok 4.1 are the hallucination reduction and context retention working together. When you’re building automation pipelines — whether for content generation, data analysis, code review, or customer support — the biggest operational risk is an AI that’s “confidently wrong.” A 4.22% hallucination rate isn’t zero, but dropping from 12% represents a meaningful shift in how much you can trust the output. In practical terms, you go from expecting roughly 12 errors per 100 outputs to expecting about 4. That’s the difference between needing to verify everything and being able to spot-check.
The 2-million-token context window paired with 91% recall accuracy addresses another pain point that anyone who works with LLMs daily has experienced. Working with long documents, complex multi-file codebases, or extended project conversations, the moment an LLM forgets what you discussed earlier, your productivity advantage evaporates. You end up re-explaining context, re-pasting code, and re-establishing requirements — which defeats the entire purpose of having a large context window. Grok 4.1 appears to have made genuine progress here, and for workflows that involve sustained, complex interactions, this could be its most practically important improvement.
The broader LLM landscape is getting increasingly competitive, and that’s unambiguously good for users and developers. With OpenAI, Anthropic, Google, Meta, and now xAI all fielding top-tier models, we’re past the era of one model dominating every use case. The ability to evaluate each model’s strengths and match them to specific tasks is becoming a core competency for any team building AI-powered products. Grok 4.1 makes a strong case for itself on accuracy, instruction following, emotional intelligence, and developer-friendly pricing. The Agent Tools API and exclusive X platform data access give it a differentiated position that goes beyond just benchmark numbers.
Whether you’re evaluating LLMs for your next project, building AI agents that need reliable and cost-effective tooling, or just trying to keep up with how fast this space moves — Grok 4.1 deserves serious consideration. The competition is pushing every provider to get better, faster, and more affordable. And ultimately, that acceleration benefits everyone building with AI.
Interested in building AI agents or LLM-powered automation pipelines? Let’s find the right solution for your use case.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}