
Apple HomePod 3 Rumors: Everything We Know About the 7-Inch Display and Apple Intelligence
July 21, 2025
PreSonus Eris E5 XT MkII Review: 5 Reasons This $200 Budget Monitor Refresh Changes Everything
July 22, 2025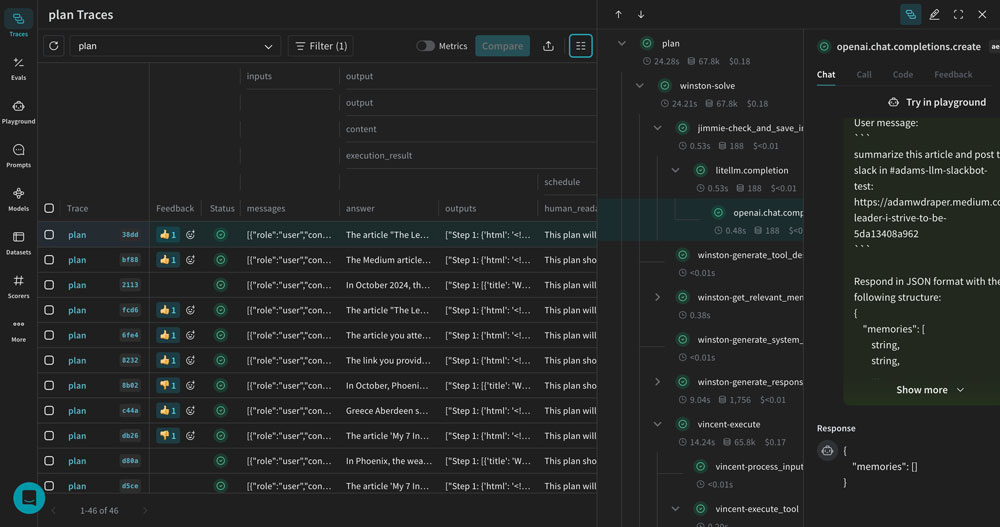
You’ve shipped your LLM app to production. A user complains the answer was wrong. You open the logs and find… nothing useful. Just raw API calls with no context about which prompt version was running, what the retrieval step returned, or why the model hallucinated. Sound familiar? W&B Prompts and Weave exist precisely to eliminate this blind spot—and after spending time with the platform, I can say it’s one of the most comprehensive LLMOps solutions available today.
Weights & Biases secured $50 million in funding at a $1.25 billion valuation in 2025, and they’ve placed W&B Prompts at the center of their strategy. The pitch is ambitious: manage the entire LLM application lifecycle—prompt engineering, debugging, evaluation, and production monitoring—within a single LLMOps platform. Let’s break down what that actually means in practice.
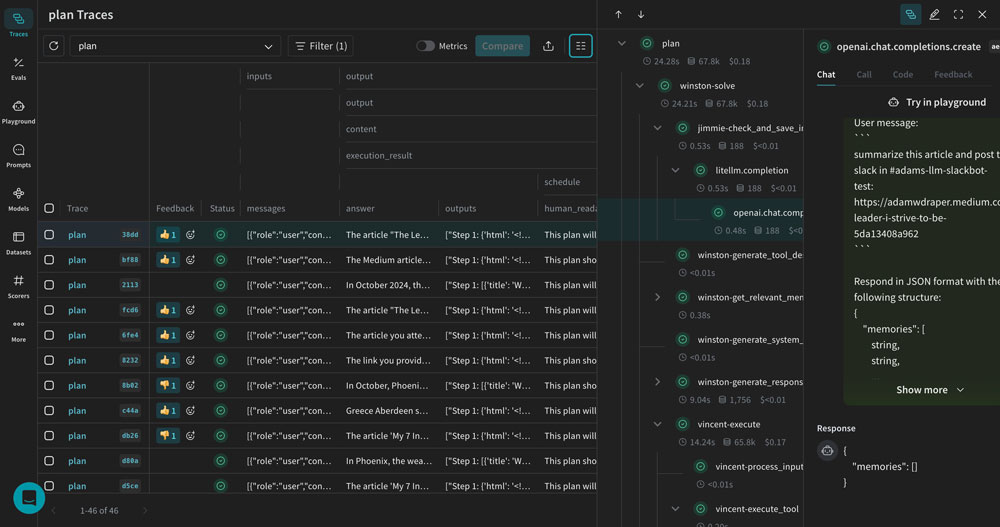
W&B Prompts and Weave: A New Standard for LLM Observability
At the heart of W&B Prompts is Weave, an observability and evaluation platform purpose-built for LLM applications. Unlike traditional ML experiment trackers that focus on training metrics, Weave is designed for the unique challenges of generative AI—where the “model” is often a complex chain of prompts, retrievers, and post-processors.
The killer feature is the @weave.op decorator. Add it to any Python function, and Weave automatically captures inputs, outputs, costs, and latency for every LLM call. No manual logging. No separate telemetry code. Just one decorator and you have full visibility.
import weave
weave.init("my-llm-project")
@weave.op
def generate_response(prompt: str) -> str:
# Works with OpenAI, Anthropic, local models—any LLM
return client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
).choices[0].message.contentGetting started is trivially easy: pip install weave for Python, pnpm install weave for TypeScript. That low barrier to entry matters—you can add observability to an existing LLM app in minutes, not days. And because Weave is framework-agnostic, it works whether you’re using LangChain, LlamaIndex, raw API calls, or your own custom orchestration.
What really sets Weave apart from simpler logging solutions is its understanding of LLM-specific concerns. It doesn’t just record inputs and outputs—it captures token usage, cost calculations per call, model parameters, and timing breakdowns. When you’re running thousands of LLM calls per day and your API bill is climbing, having granular cost attribution per function and per model version isn’t a luxury—it’s a necessity for budget management and optimization decisions.
Debugging Prompt Chains with W&B Traces
Single-prompt LLM apps are the exception in 2025, not the rule. RAG pipelines, multi-agent systems, and tool-calling workflows mean that a single user query can trigger dozens of LLM calls, retrieval operations, and transformations. When something goes wrong, figuring out where it went wrong is the real challenge.
W&B Traces tackles this with visual trace debugging. Every step in your prompt chain—retrieval, context assembly, LLM call, post-processing—is visualized as a tree structure. You can inspect intermediate results at each node, see exact token counts and latencies, and pinpoint exactly where a response went off the rails.
In practice, this is transformative for RAG debugging. Consider a scenario where your retrieval-augmented generation system returns an incorrect answer. Was it because the vector search pulled irrelevant documents? Was the context window stuffing poorly formatted? Did the LLM hallucinate despite having correct context? With W&B Traces, you can answer these questions in seconds rather than hours of print-statement debugging.
The platform also provides secure prompt and chain configuration management. You can version your prompts, track which configuration produced which results, and roll back when needed. For teams where multiple engineers are iterating on prompts simultaneously, this version control is invaluable. Think of it as Git for your prompt configurations—except with full execution traces attached to each version, so you can see not just what changed, but exactly how the change affected real outputs.
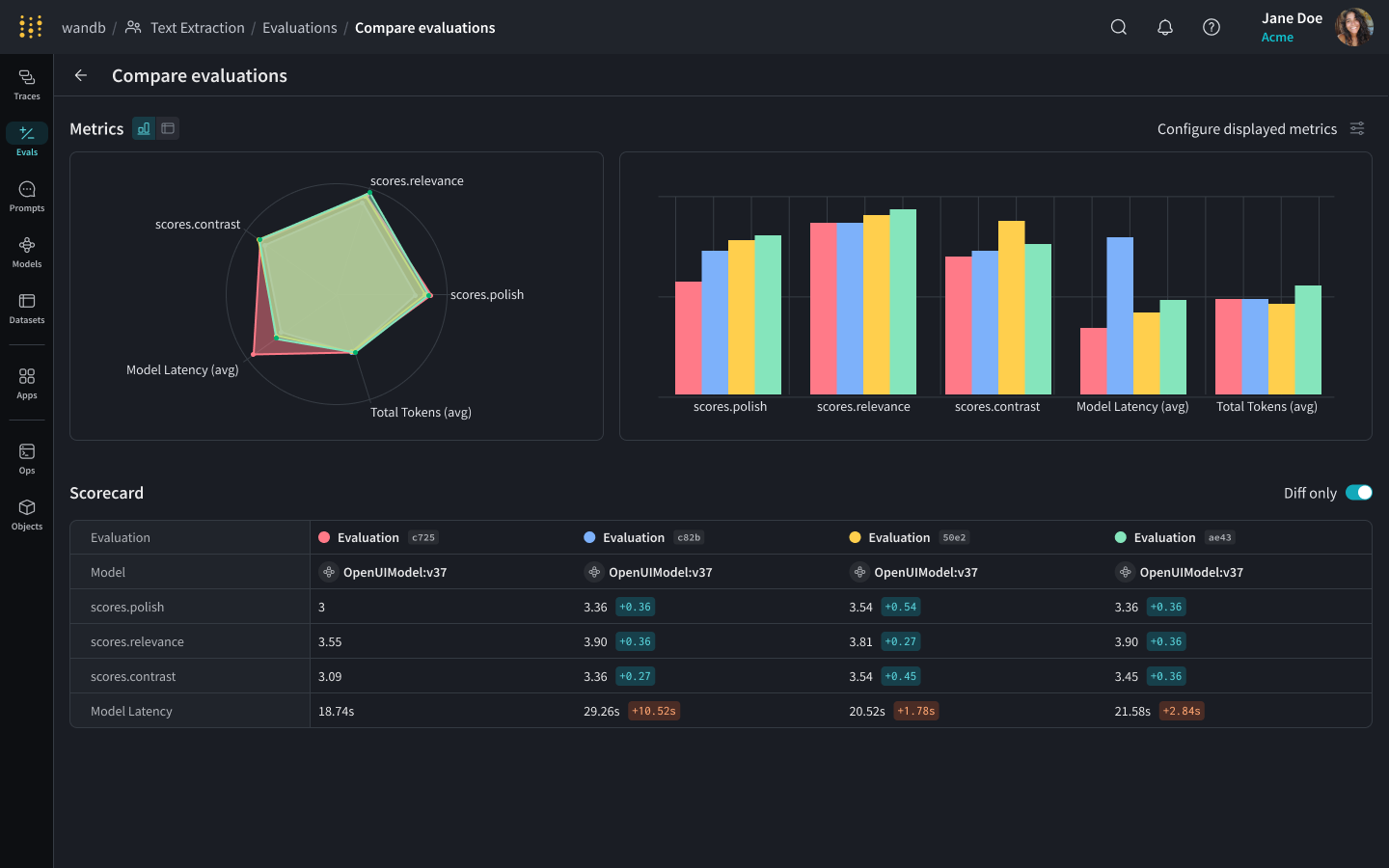
W&B Prompts Evaluation System: LLM Judges, Custom Scorers, and Leaderboards
Here’s the uncomfortable truth about prompt engineering in most organizations: it’s vibes-based. Someone changes a prompt, runs a few test queries, thinks it “looks better,” and ships it. No systematic comparison. No regression testing. W&B Prompts changes this fundamentally with its Evaluations framework.
The evaluation system has three core pillars:
- LLM Judges: Use another LLM to automatically score responses for accuracy, relevance, safety, and coherence. When you have thousands of outputs to evaluate, human review doesn’t scale—but LLM-as-judge approaches do, and W&B makes them easy to configure.
- Custom Scorers: Define evaluation criteria that match your business logic. Response length, keyword inclusion, format compliance, domain-specific accuracy checks—you write the scoring function, W&B runs it at scale across your dataset.
- Leaderboards: Compare models, prompt versions, and parameter combinations side by side. Accuracy, latency, cost—all on a single dashboard that makes it obvious which configuration wins.
The online evaluation feature deserves special attention. This isn’t just offline benchmarking on test sets—W&B can continuously evaluate production responses in real time. You set up scorers that run on live traffic, catch quality degradation early, and trigger alerts before users start complaining. For any team running LLMs in production, this kind of continuous monitoring is no longer optional. Consider the alternative: without online evals, you only discover quality issues when users complain—by which point the damage to trust and retention may already be done. With W&B Prompts’ continuous evaluation, you’re catching regressions proactively, often before any user notices.
OpenTelemetry Integration and Enterprise Scalability
One of the most significant updates to the W&B Prompts ecosystem in 2025 is OpenTelemetry (OTel) integration. Previously, trace collection was limited to the Python and TypeScript SDKs. With OTel support, you can now send trace data to W&B from Go, Java, Rust, or any language with an OTel-compatible library.
This matters enormously for enterprise deployments. Real-world AI systems at scale are polyglot—Python handles ML pipelines, Go or Rust runs the API gateway, Java processes data pipelines. OTel integration means you can observe LLM-related traces across all these components in a unified dashboard, without being locked into a single-language SDK.
The enterprise story gets stronger with the AWS Bedrock AgentCore integration. Organizations running AI agents on Amazon Bedrock can plug W&B Weave in as their observability layer, getting enterprise-grade tracing and evaluation without building custom monitoring infrastructure. For AWS-centric shops, this eliminates a significant operational burden. Instead of cobbling together CloudWatch logs, custom Lambda monitoring, and third-party APM tools, you get a unified observability layer purpose-built for AI workloads.
How W&B Prompts Compares: LangSmith, Arize Phoenix, and the Competitive Landscape
The LLM observability market is heating up fast. Understanding where W&B Prompts fits requires honest comparison with the alternatives.
LangSmith is deeply integrated with the LangChain ecosystem. If your entire stack is built on LangChain, LangSmith offers the smoothest developer experience with near-zero configuration. The trade-off is lock-in—if you move away from LangChain, or if parts of your system don’t use it, LangSmith’s value proposition weakens. W&B Prompts is framework-agnostic, working equally well with vanilla OpenAI calls, LangChain, LlamaIndex, or custom orchestration code.
Arize Phoenix takes the open-source, OTel-native approach. It’s excellent for teams that want full control over their data and infrastructure, and its commitment to open standards is commendable. However, it lacks the integrated evaluation ecosystem—leaderboards, online evals, LLM judges out of the box—that W&B provides, and enterprise support options are more limited.
W&B Prompts’ strongest differentiator is continuity with the existing ML ecosystem. If your team already uses Weights & Biases for model training and experiment tracking, adding Weave for LLM observability means one platform from training to production. No new vendor, no new billing, no context switching between tools. That unified workflow—from fine-tuning experiments to prompt optimization to production monitoring—is something neither LangSmith nor Arize can match today.
Practical Adoption Strategy: Getting W&B Prompts Into Your Team’s Workflow
If you’re convinced W&B Prompts is worth exploring, here’s a realistic adoption path that minimizes disruption.
Phase 1: Instant observability. Add @weave.op decorators to your existing LLM calls. This requires minimal code changes and immediately gives you visibility into every call’s inputs, outputs, costs, and latency. Start here—the ROI is immediate and the risk is near zero.
Phase 2: Build your evaluation framework. Create a golden dataset of representative queries and expected outputs. Set up LLM judges and custom scorers through W&B Evaluations. Now every prompt change can be measured against a consistent baseline instead of gut feeling.
Phase 3: Production monitoring. Enable online evaluations to continuously score production responses. Set up alerts for quality degradation. Use trace data to diagnose issues quickly when they arise.
Phase 4: Team-wide scaling. Leverage leaderboards for collaborative prompt engineering. Use W&B’s official documentation and RAG evaluation tutorials to build advanced evaluation pipelines tailored to your use case.
As LLM applications mature from prototypes to production systems in 2025, managing prompts with data rather than intuition is becoming non-negotiable. W&B Prompts offers one of the most complete platforms for that transition—covering observability, evaluation, and monitoring in a single tool chain. Whether you’re already in the Weights & Biases ecosystem or starting fresh, pip install weave gets you from zero to full LLM observability in minutes. That’s a compelling starting point for any team serious about production-grade AI.
Looking to build or optimize LLM pipelines and AI automation systems? Sean Kim can help.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}