February 3, 2026

Claude Opus 4.6 vs GPT-5.1 vs Gemini 3.5: The February 2026 Benchmark Battle That Changes Everything
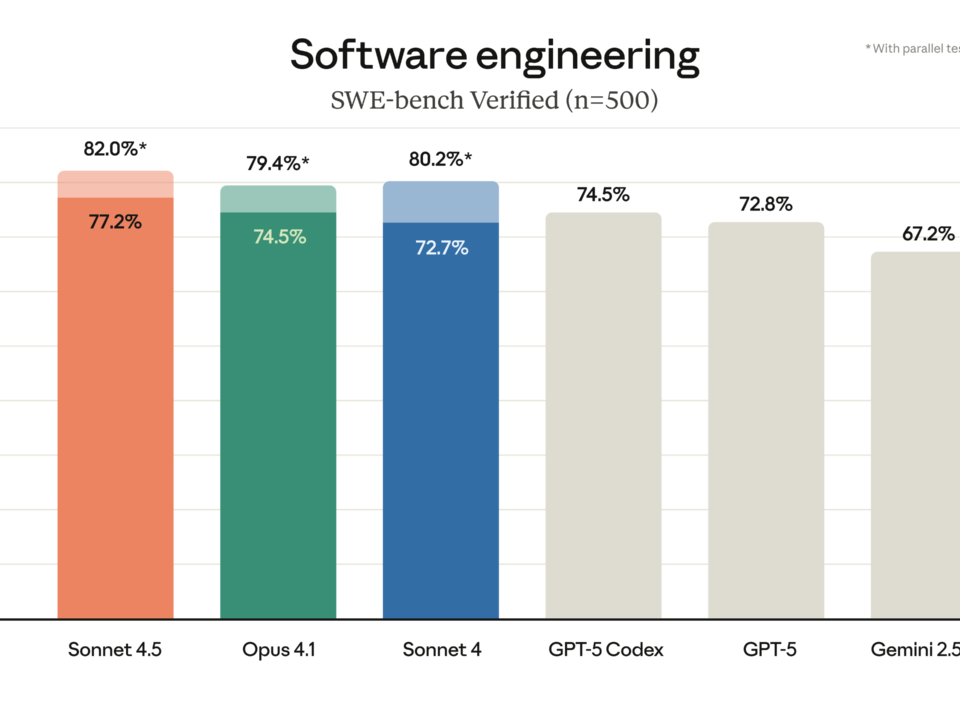
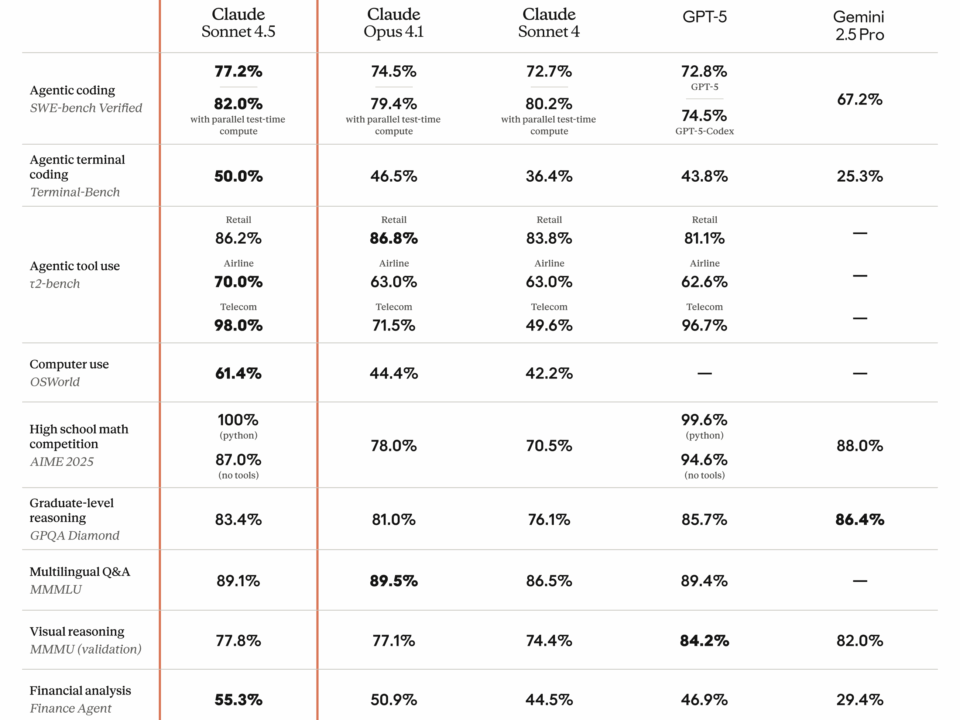
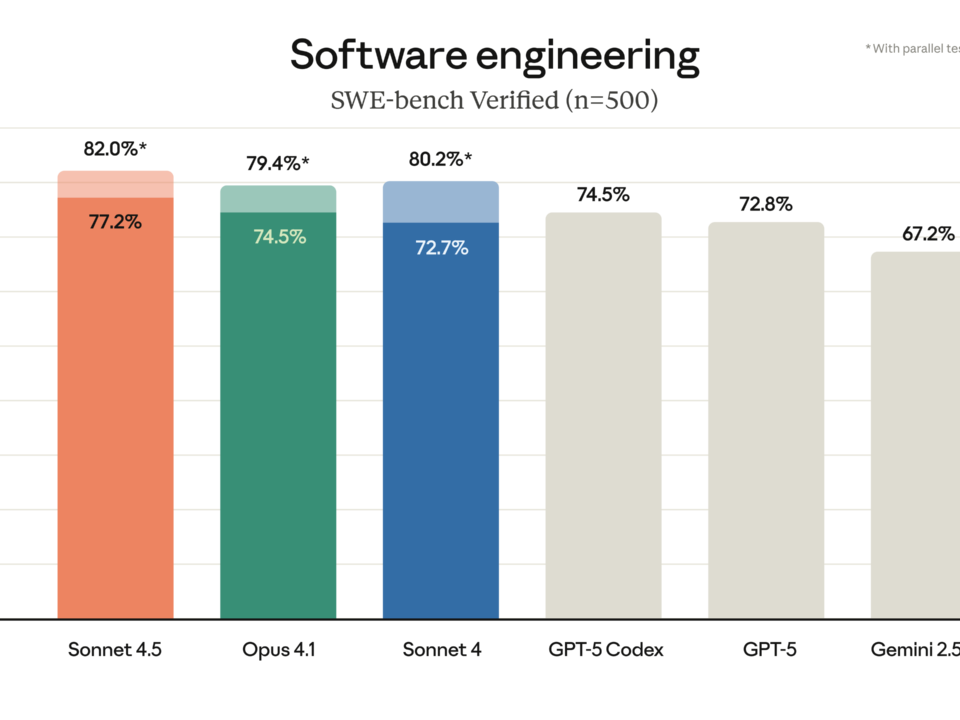
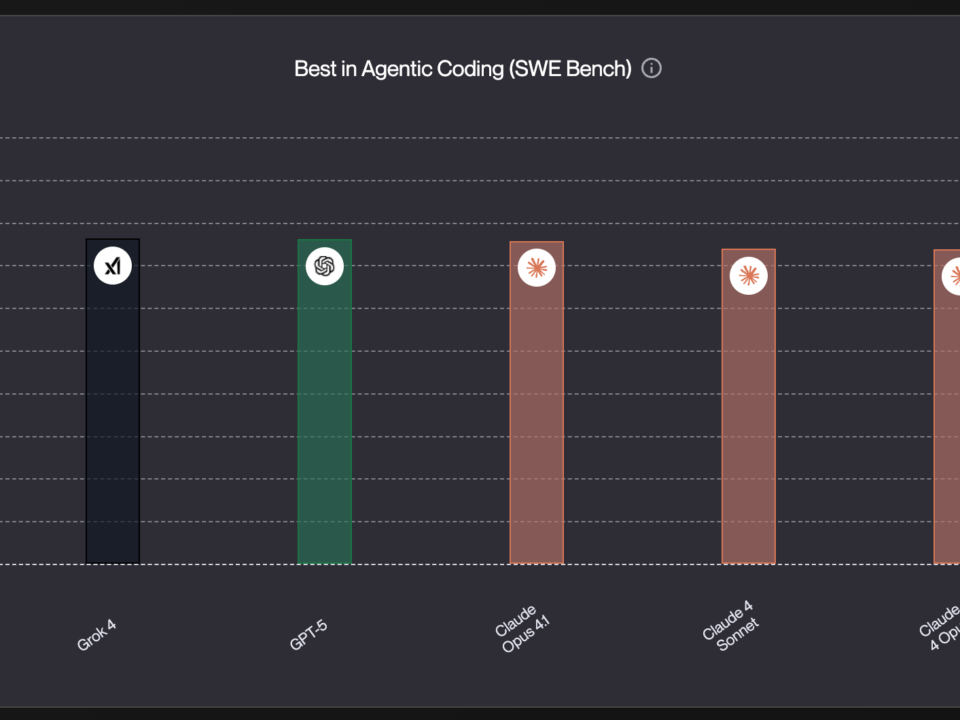
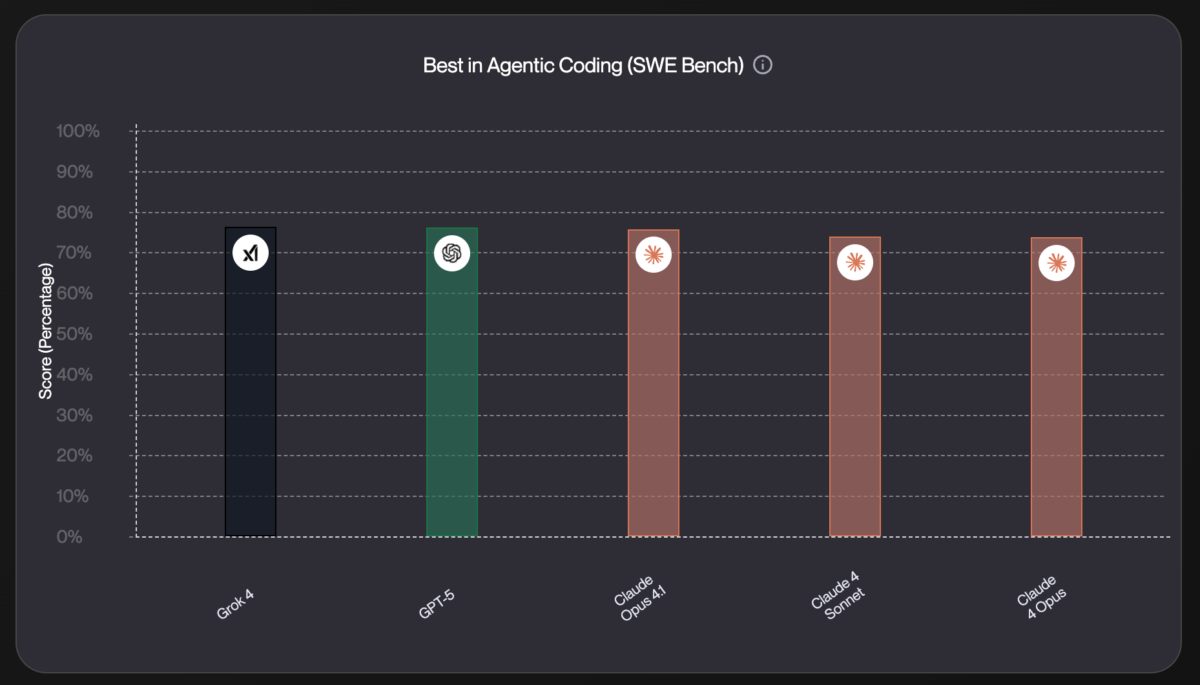
Seven major model releases in a single month. That’s what February 2026 just delivered — and the AI landscape has never looked this competitive. Claude Opus […]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}