One trillion parameters. 37 billion active per token. A million-token context window. $0.42 per million output tokens. And not a single NVIDIA chip was used to […]
$0.07 per million tokens — DeepSeek cloud pricing has shattered every benchmark in the AI industry. At 140 times cheaper than GPT-4 Turbo’s $10 per million, […]
What if a 500-billion-parameter model could match frontier performance while only activating 50 billion parameters at inference time? That is not a hypothetical — it is […]
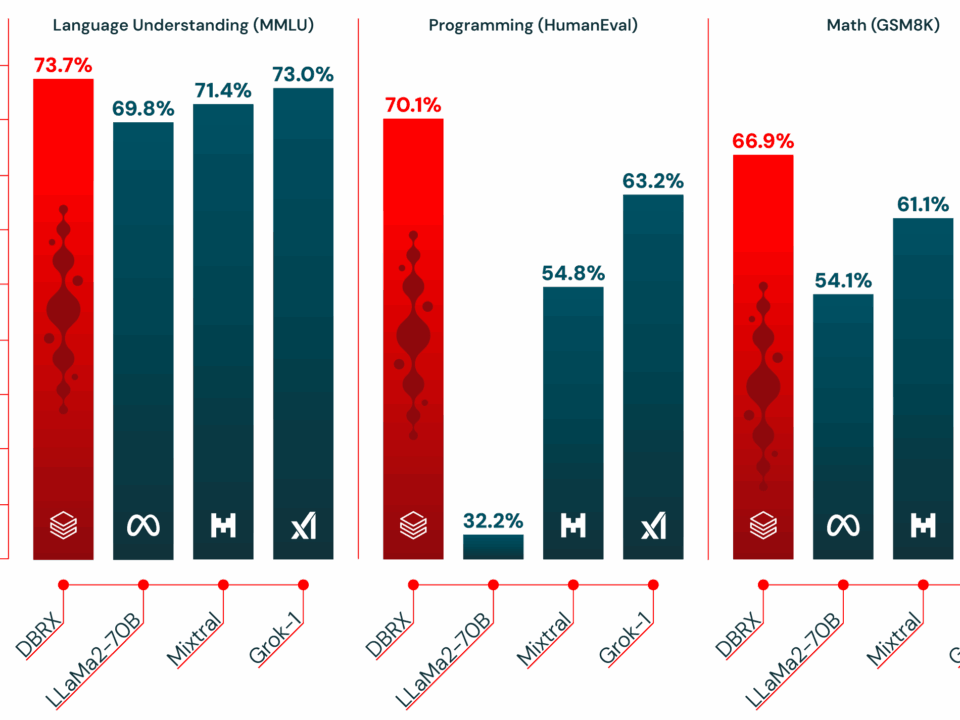
Finally — an open model family that doesn’t force you to choose between accuracy and throughput. NVIDIA Nemotron 3 just dropped with a hybrid Mamba-Transformer MoE […]
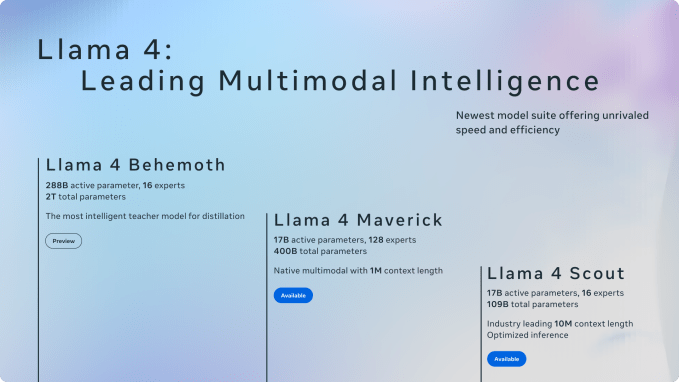
A 109-billion-parameter multimodal AI model that fits on a single GPU — Meta actually pulled it off. Llama 4 Scout, unveiled at Meta Connect 2025, runs […]
Three major open-source model drops in a single month. Alibaba shipped Qwen3-Max, Qwen3-Next, and Qwen3-Omni in rapid succession. DeepSeek quietly published V3.2-Exp with a sparse attention […]
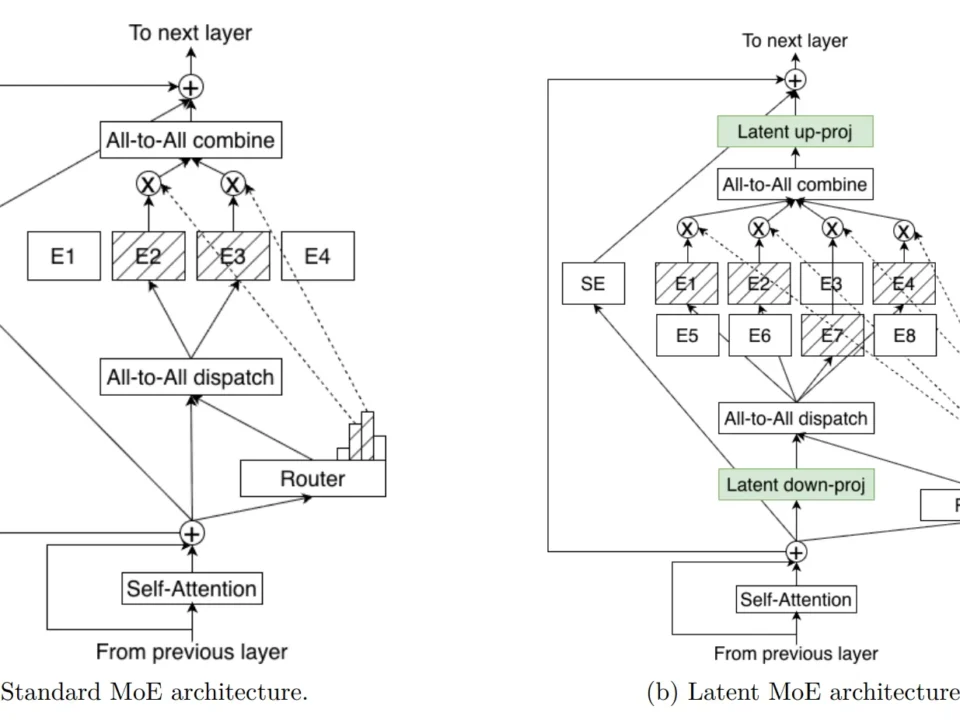
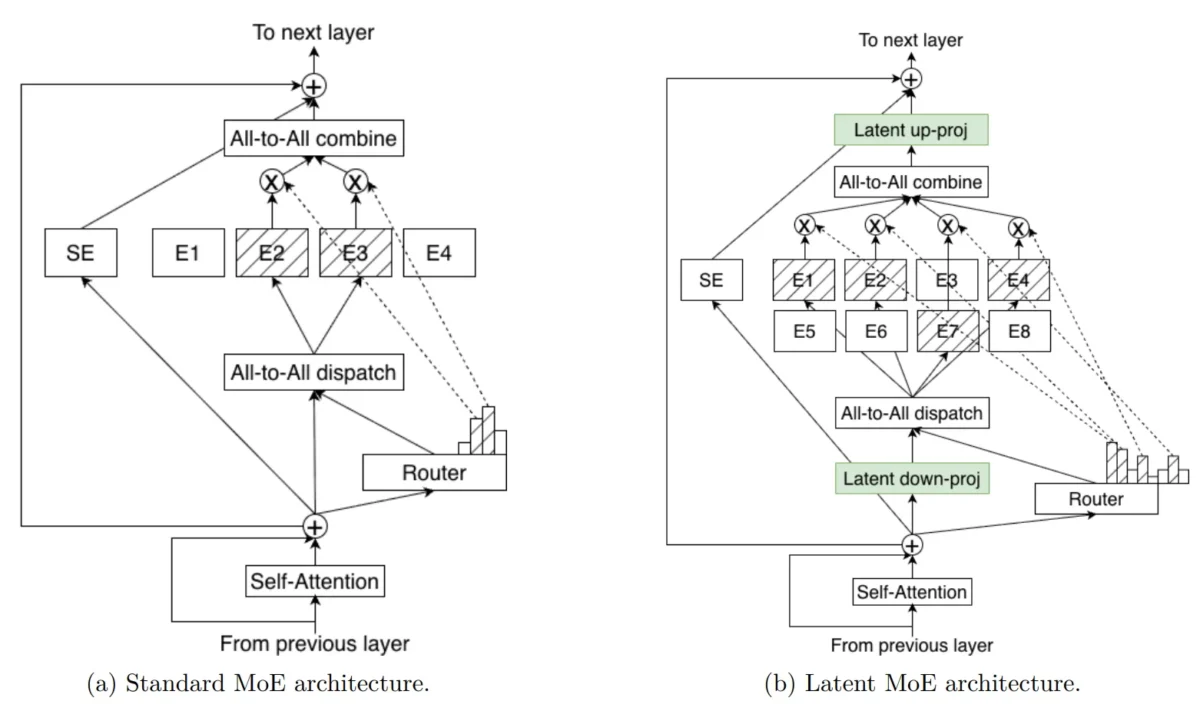
A 132B parameter model activates just 36B parameters at inference — and still outperforms models nearly twice its active size. That is not a theoretical claim. […]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}