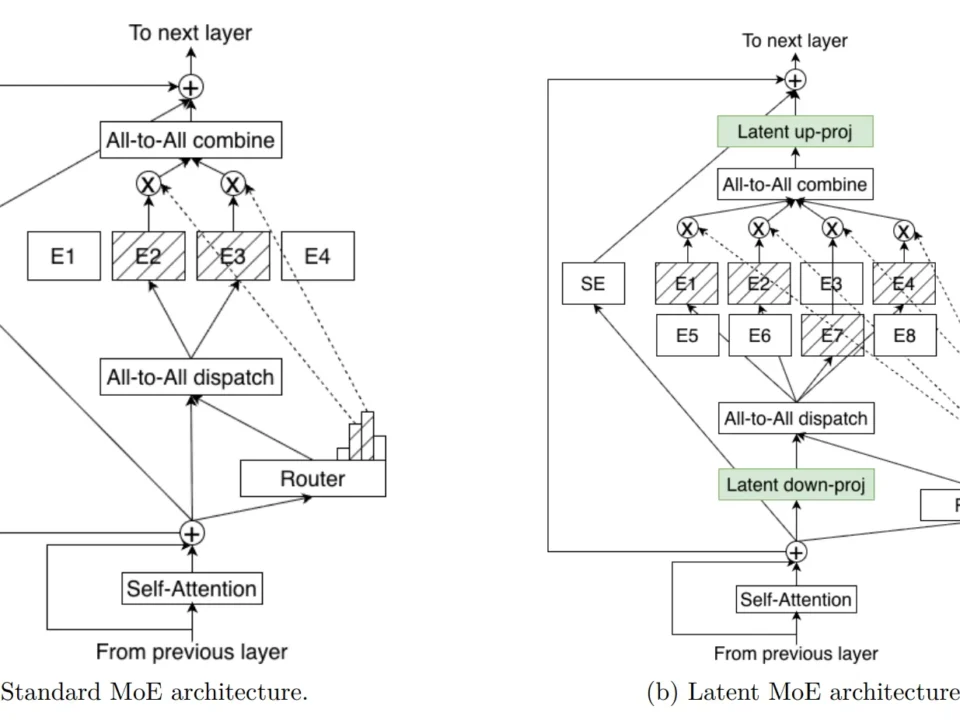
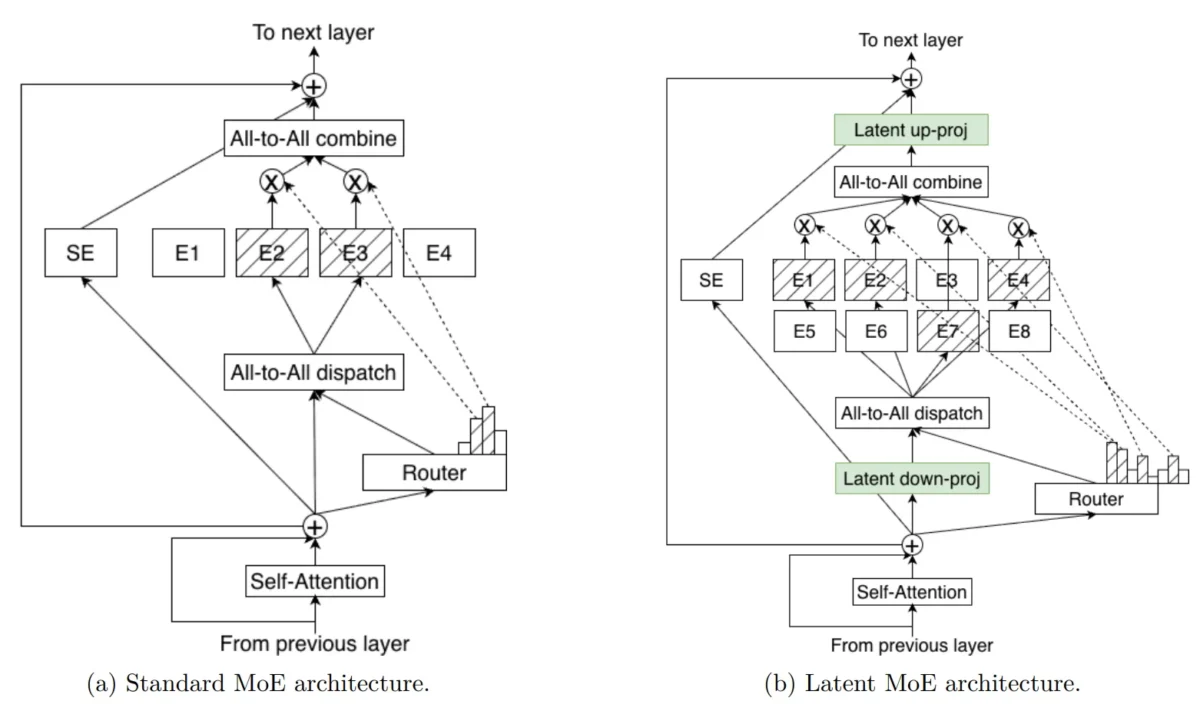
What if a 500-billion-parameter model could match frontier performance while only activating 50 billion parameters at inference time? That is not a hypothetical — it is […]
Finally — an open model family that doesn’t force you to choose between accuracy and throughput. NVIDIA Nemotron 3 just dropped with a hybrid Mamba-Transformer MoE […]

{kind=link}