On March 14, OpenAI shipped Codex subagents to general availability — and the implications for how we write software are massive. OpenAI Codex subagents let a […]
I’ve been using ChatGPT daily for over two years now — and until recently, every single conversation started from scratch. No context, no memory of the […]
“Create a presentation about last quarter’s results” — and it actually builds one. Complete with charts, brand-compliant slides, and data pulled from your emails. Microsoft’s February […]
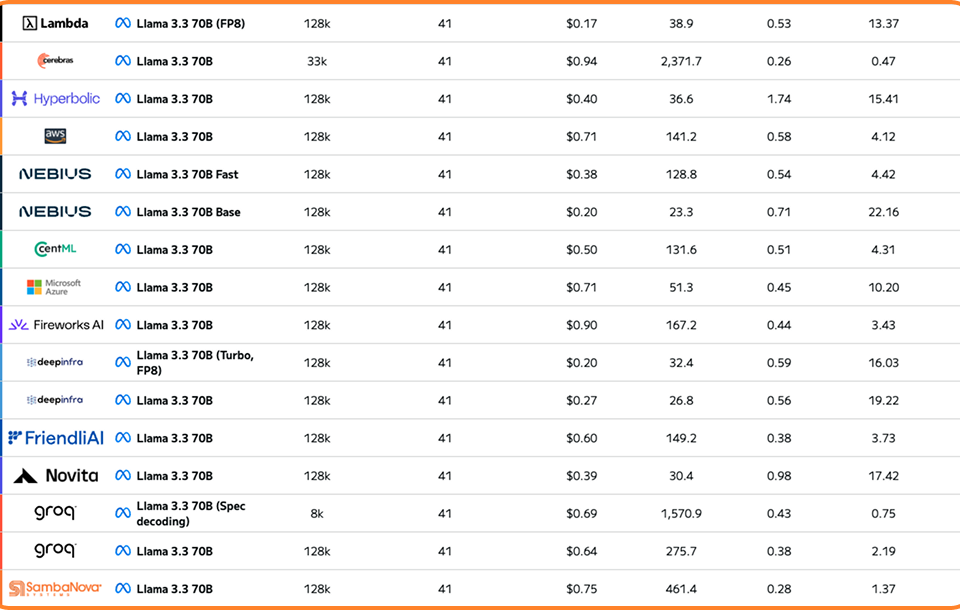
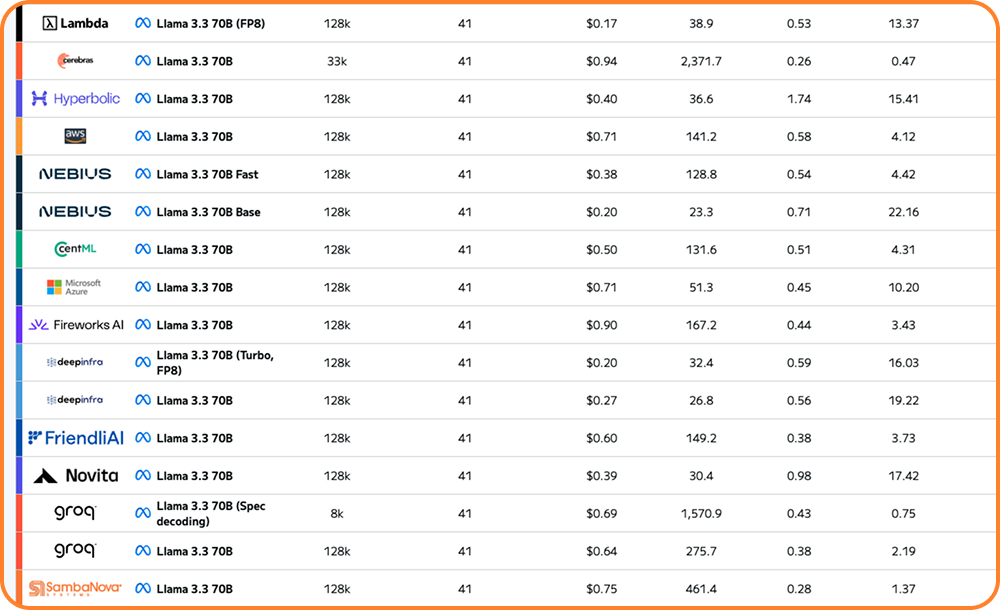
AI API pricing December 2025 has never been this wild. In just five weeks between mid-November and late December, OpenAI dropped GPT-5.2, Anthropic launched Claude Opus […]
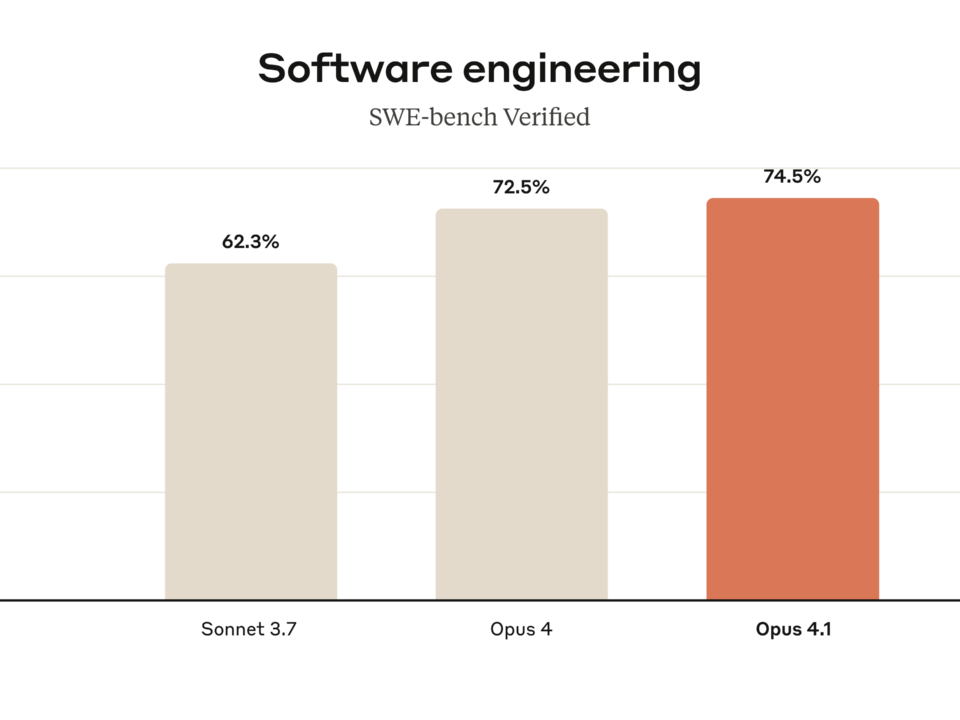
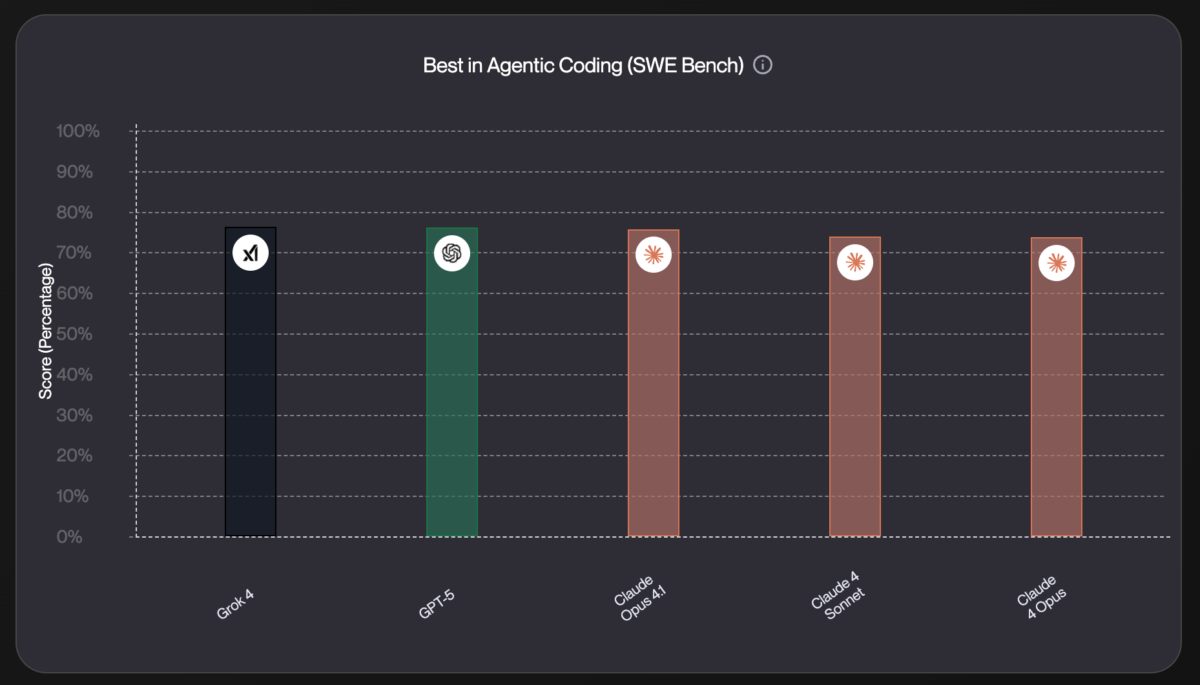
GPT-5 developer workflows looked destined for a revolution: SWE-bench 74.9%, Aider Polyglot 88%, hallucinations down 80%. Four months after launch, those numbers still impress on paper. […]
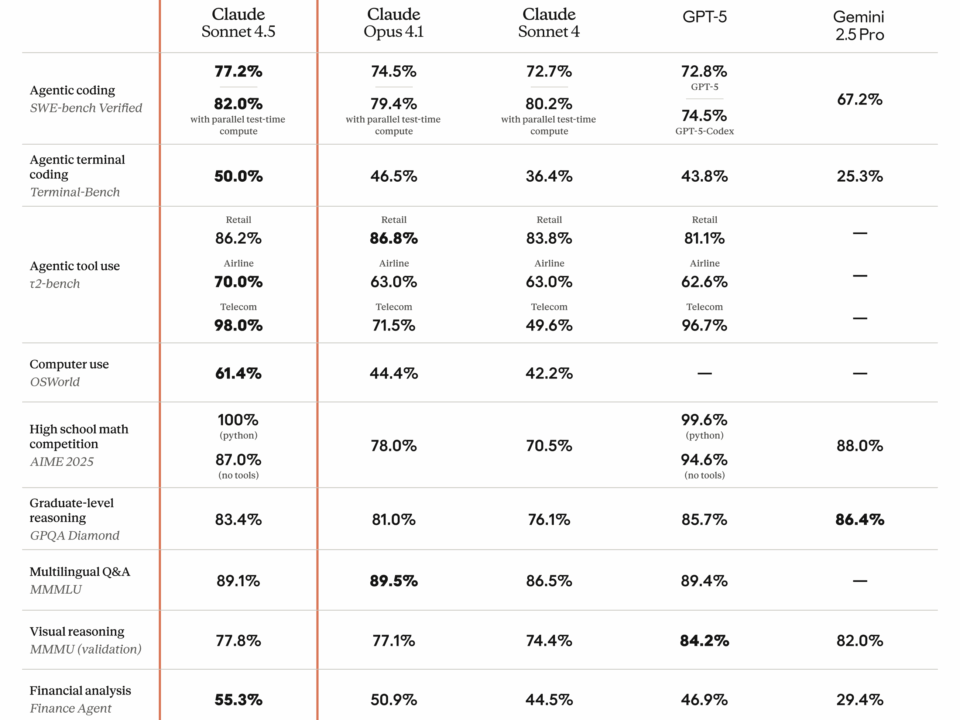
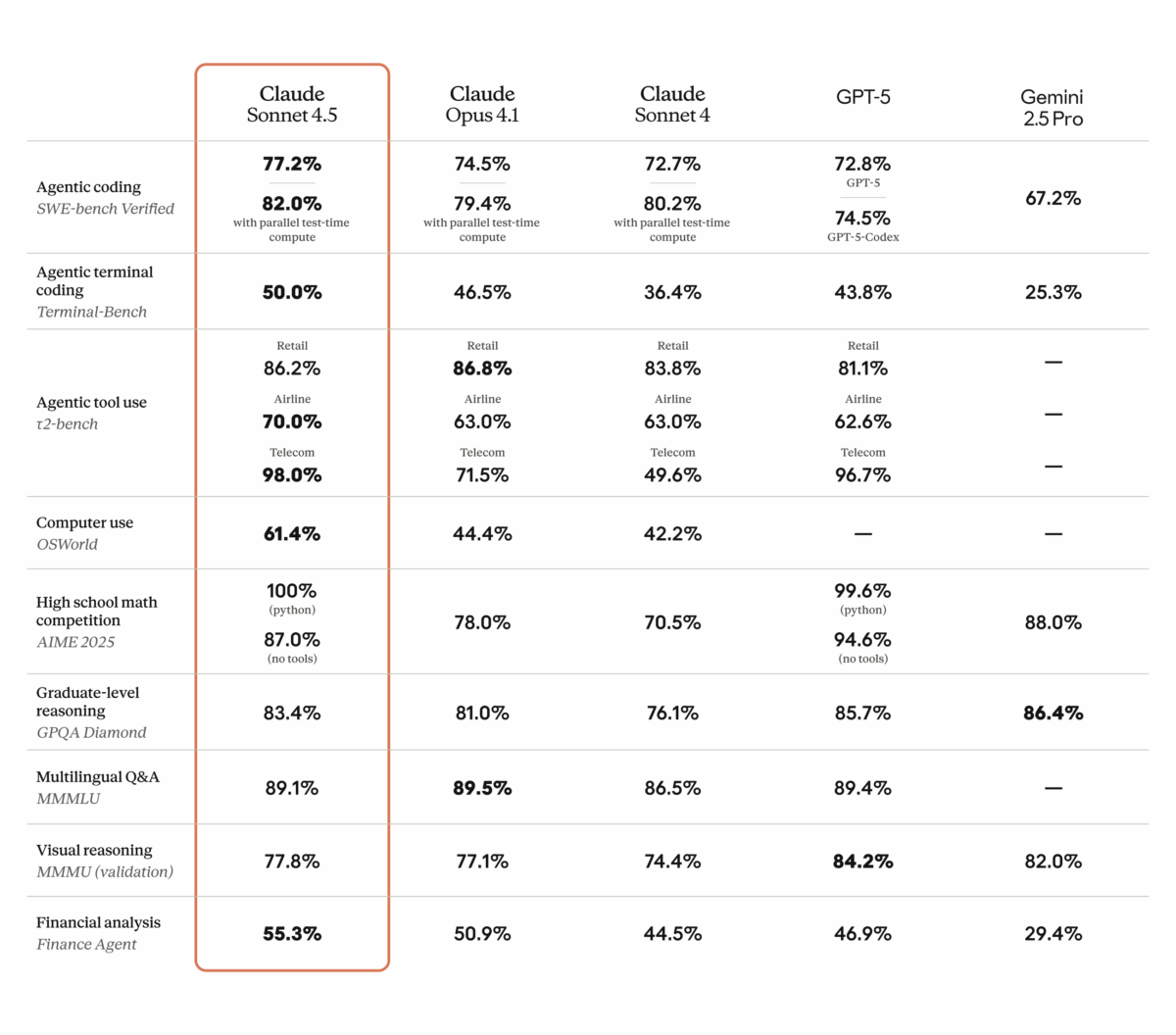
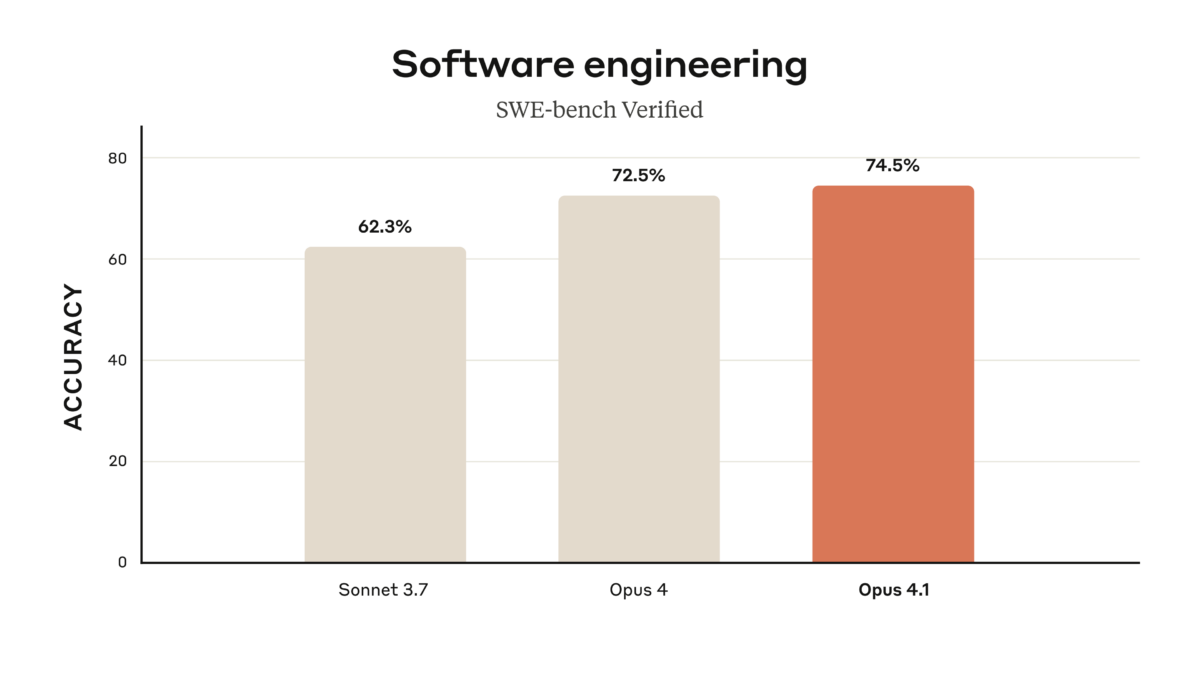
77.2% on SWE-bench Verified. That single number just rewrote the rules of the AI coding model market. Anthropic’s Claude Sonnet 4.5 benchmark results don’t just represent […]
94.6% on AIME 2025 math. 45% fewer factual errors than GPT-4o. 80% fewer than o3 in thinking mode. GPT-5’s benchmark numbers are staggering — but the […]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}