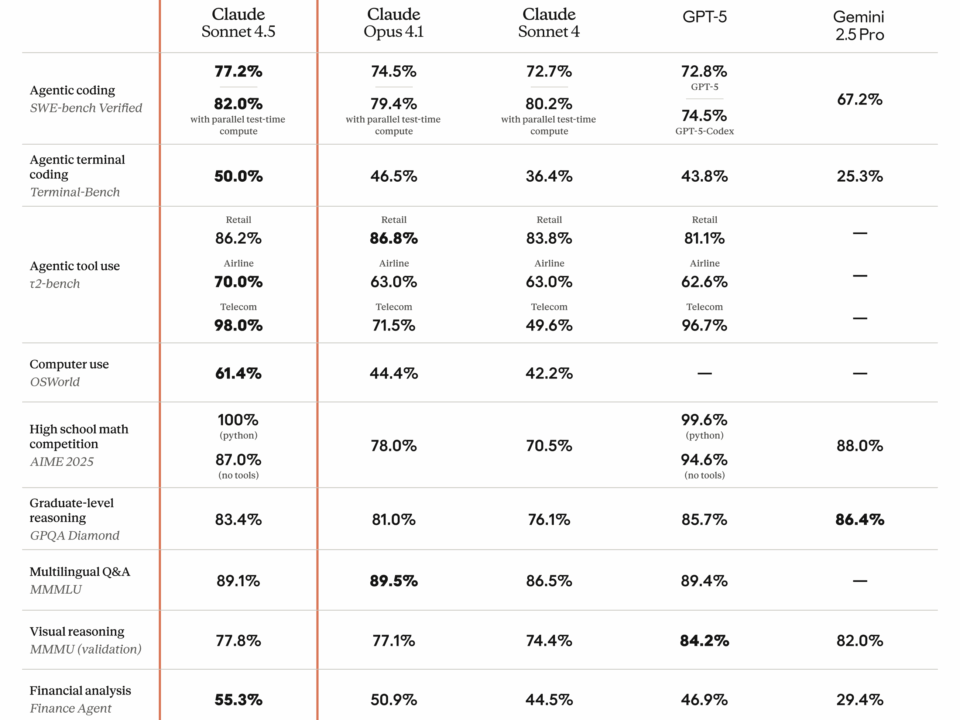
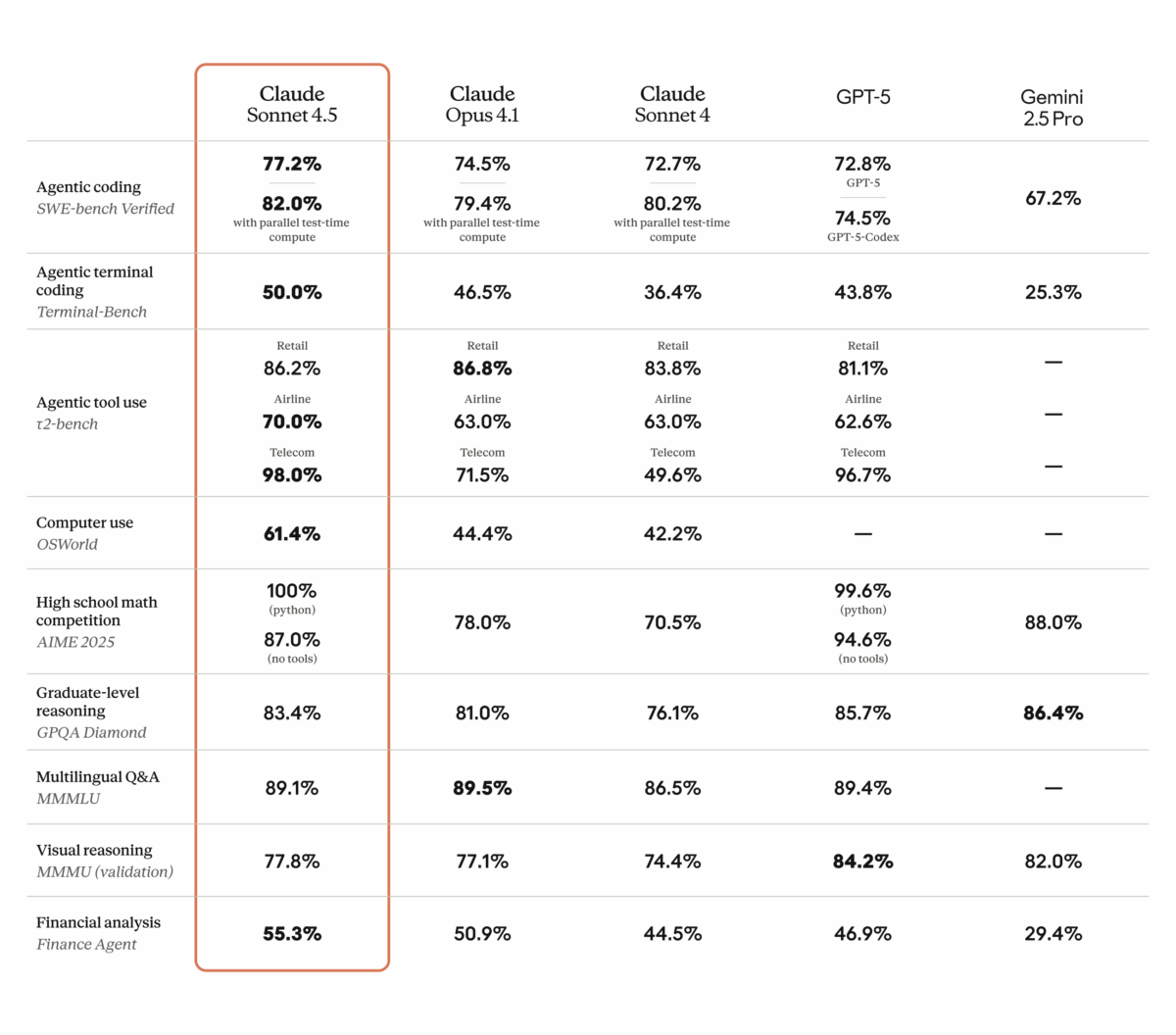
77.2% on SWE-bench Verified. That single number just rewrote the rules of the AI coding model market. Anthropic’s Claude Sonnet 4.5 benchmark results don’t just represent […]
Claude Opus 4.1 just dropped three days ago, and the benchmark numbers are telling a story that every developer building on AI should pay attention to […]

{kind=link}
{kind=link}