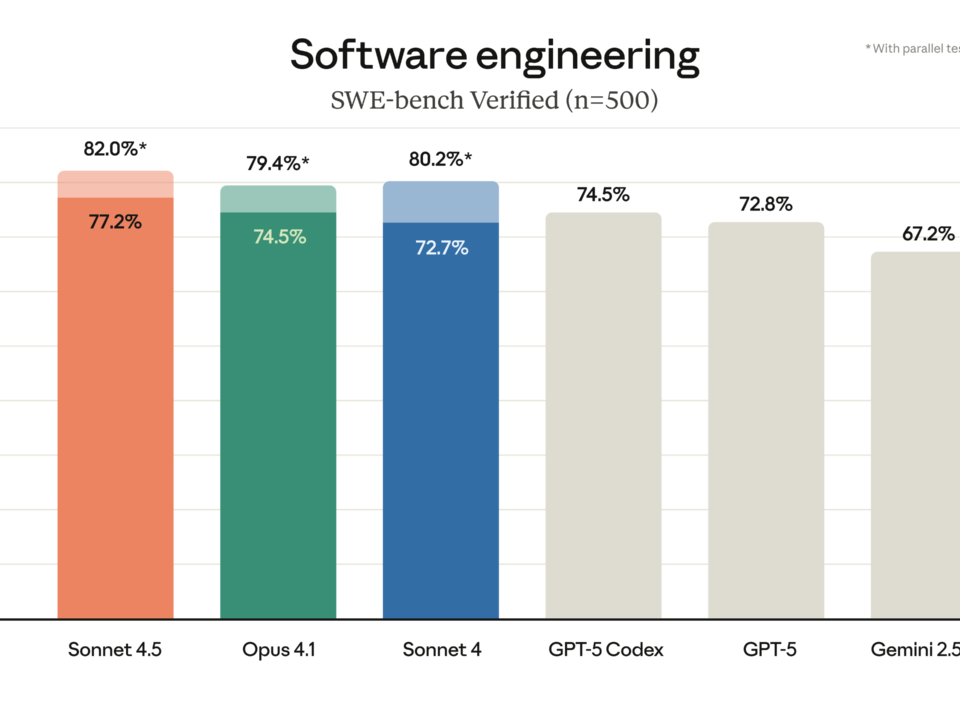
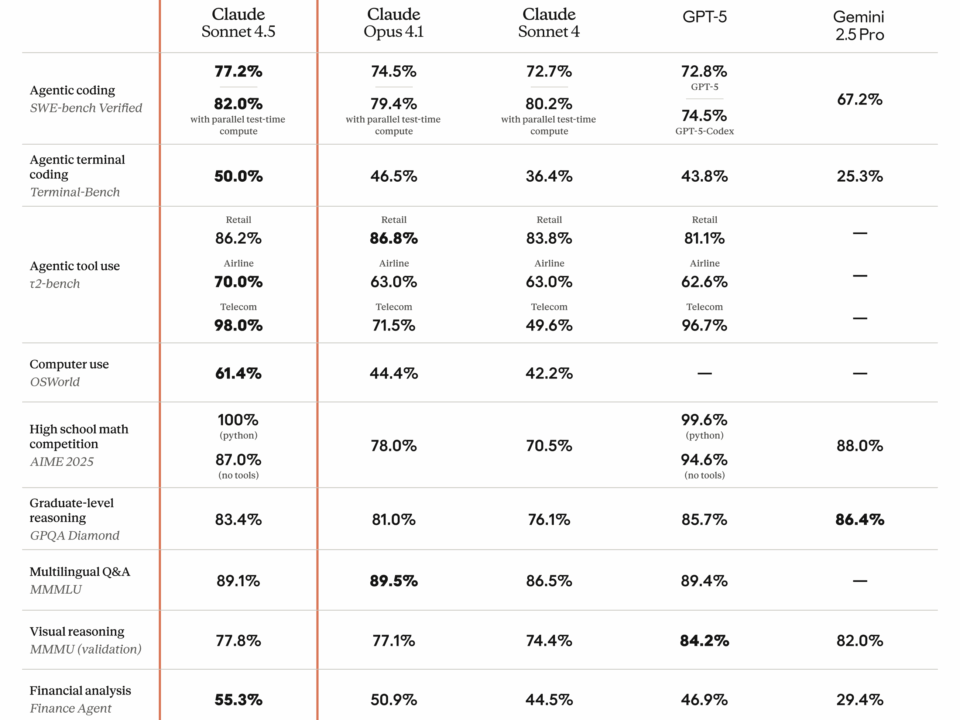
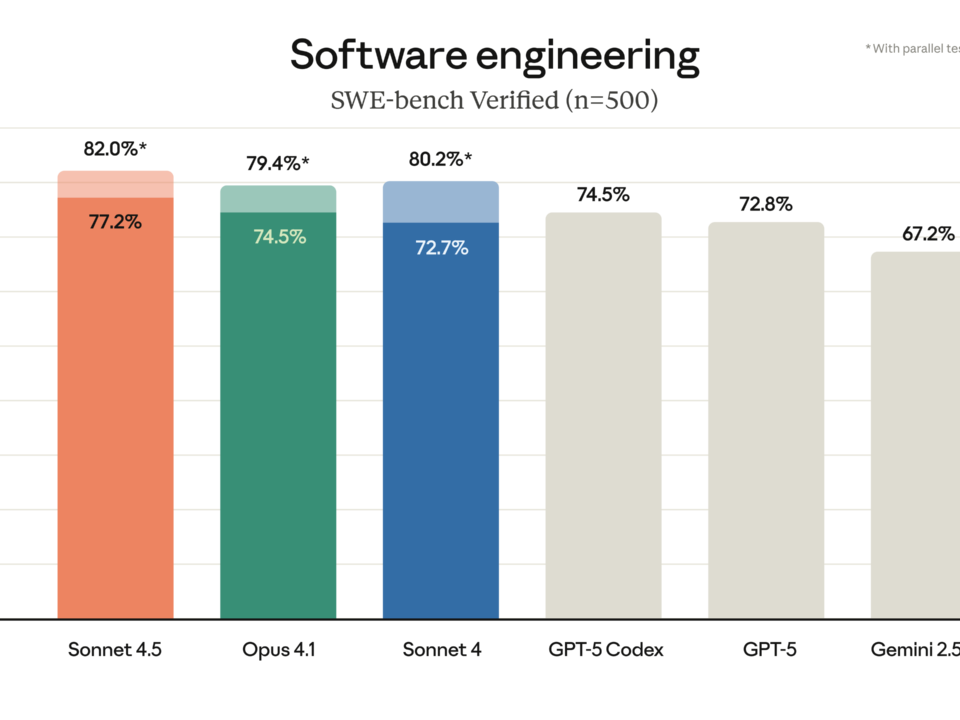
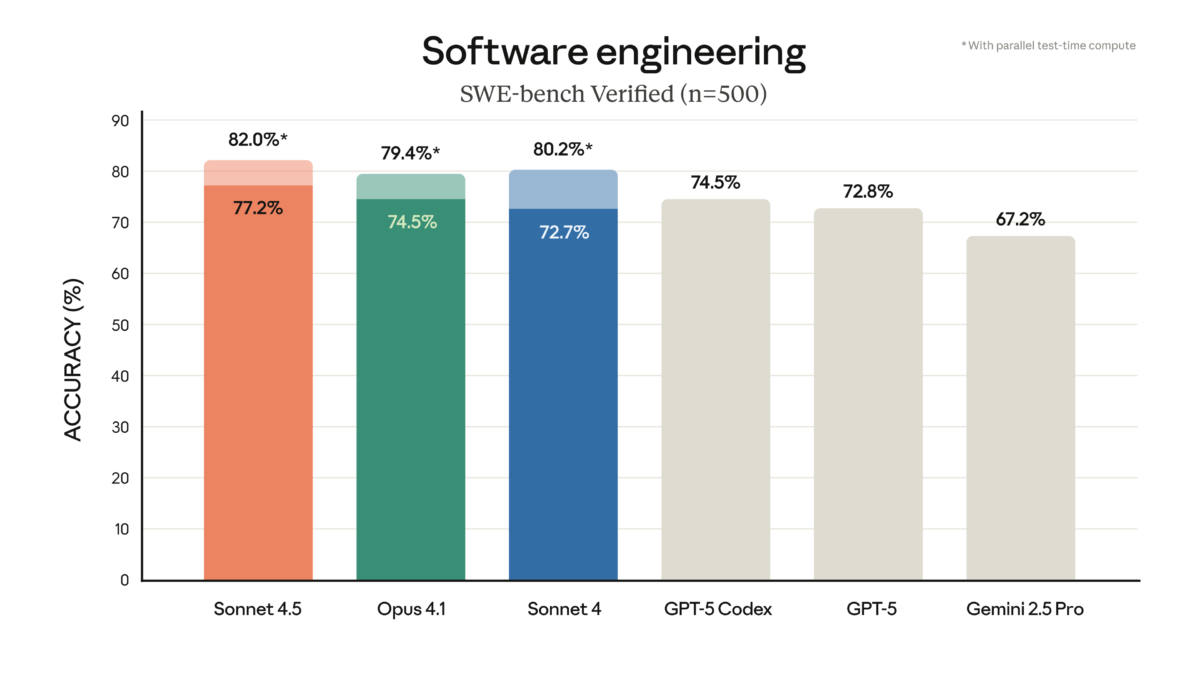
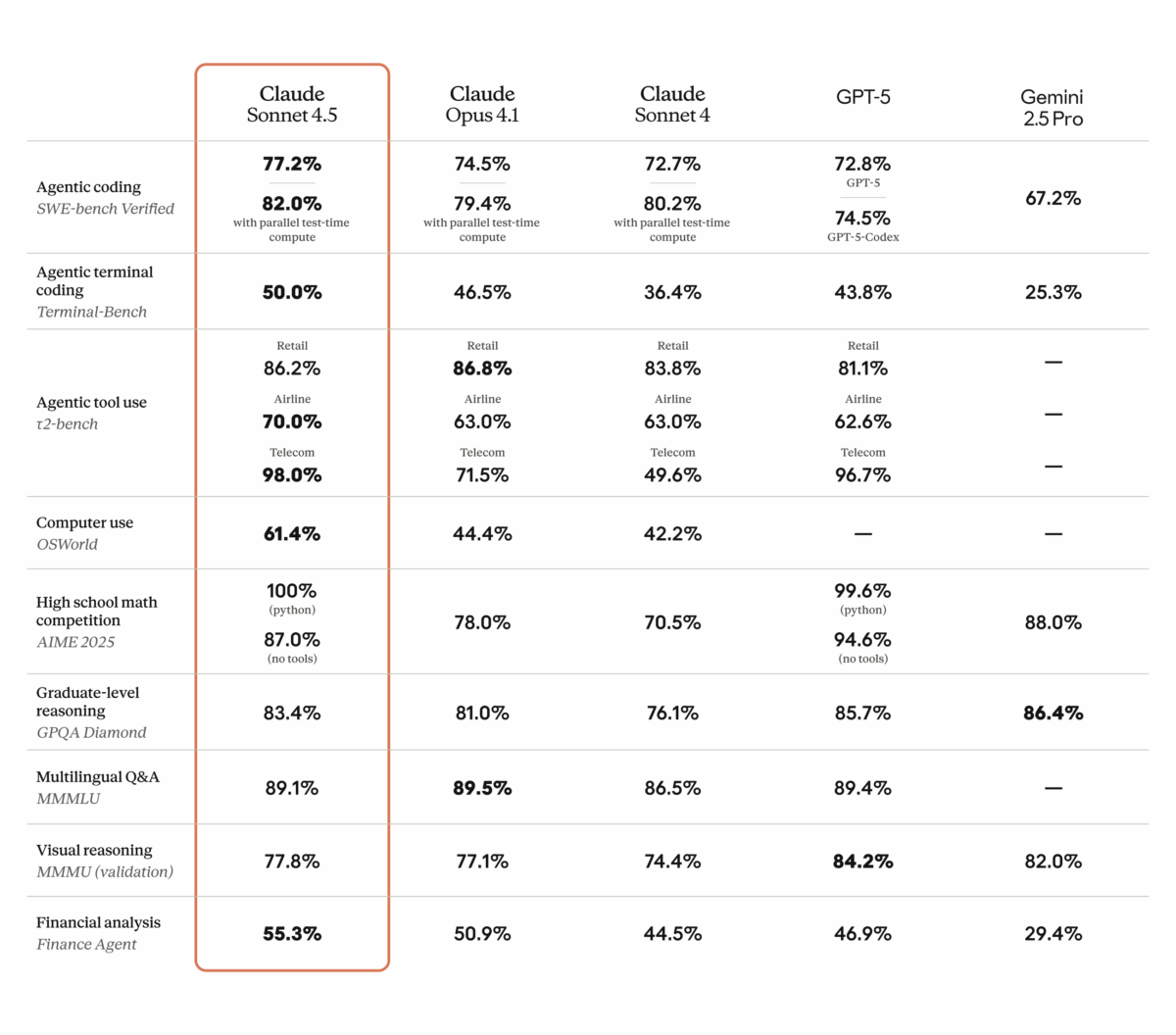
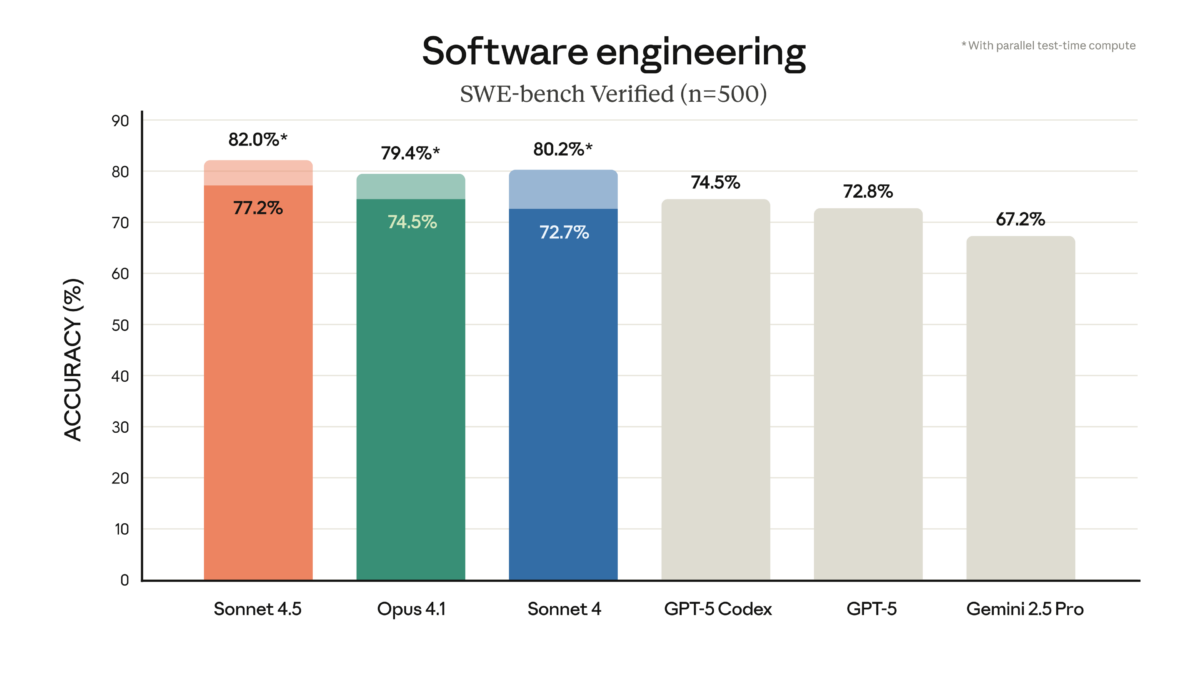
Anthropic just dropped Claude Sonnet 4.5, and the numbers speak for themselves: 77.2% on SWE-bench Verified, 61.4% on OSWorld, and agents that can stay focused for […]
77.2% on SWE-bench Verified. That single number just rewrote the rules of the AI coding model market. Anthropic’s Claude Sonnet 4.5 benchmark results don’t just represent […]
Anthropic just mass-deployed its most dangerous weapon in the AI coding wars — and it costs exactly the same as the model it replaces. Claude Sonnet […]
{kind=link}
{kind=link}
{kind=link}