Geekbench 6 single-core: 4,195. Multi-core: 17,276. From a fanless ultrabook. The MacBook Air M5 landed on March 11, 2026, and those numbers alone are enough to […]
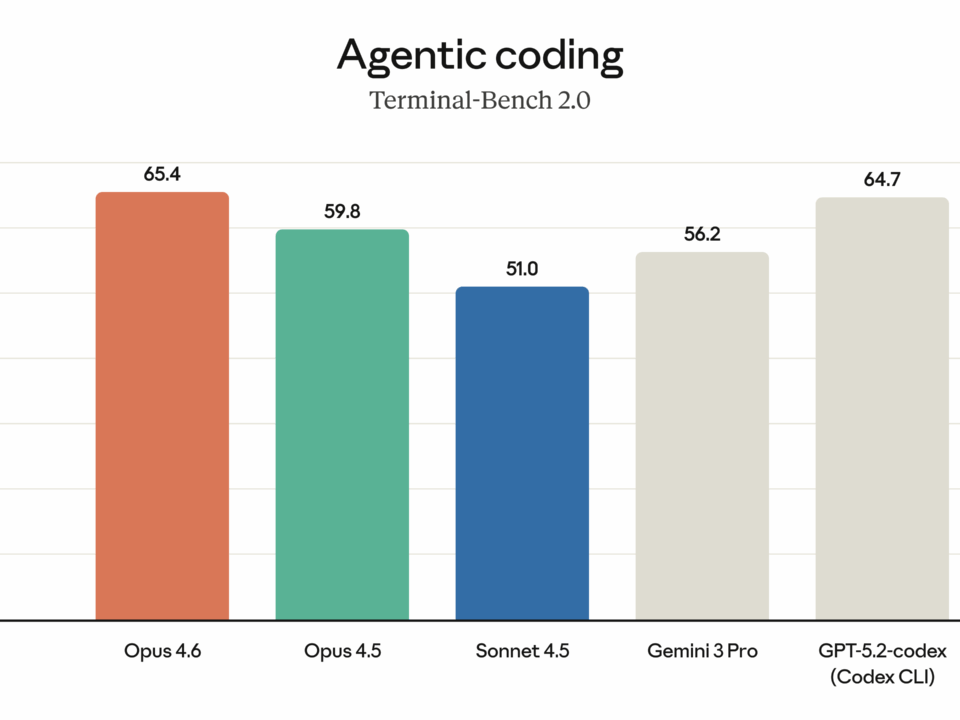
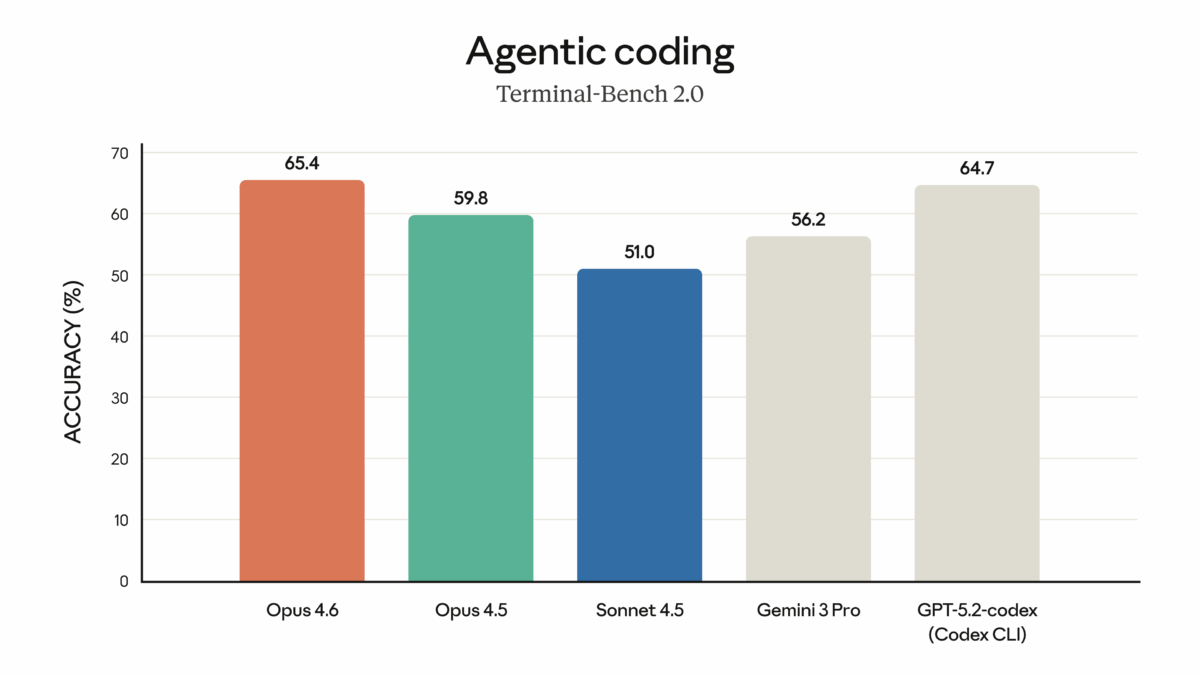
Finally — the model we’ve been waiting for. On February 5, 2026, Anthropic dropped Claude Opus 4.6, and after spending the past few days pushing it […]
On December 20, 2024, OpenAI o3 scored 87.5% on the ARC-AGI benchmark. The previous best? 55.5%. That wasn’t an improvement—it was a category rupture. Now, in […]
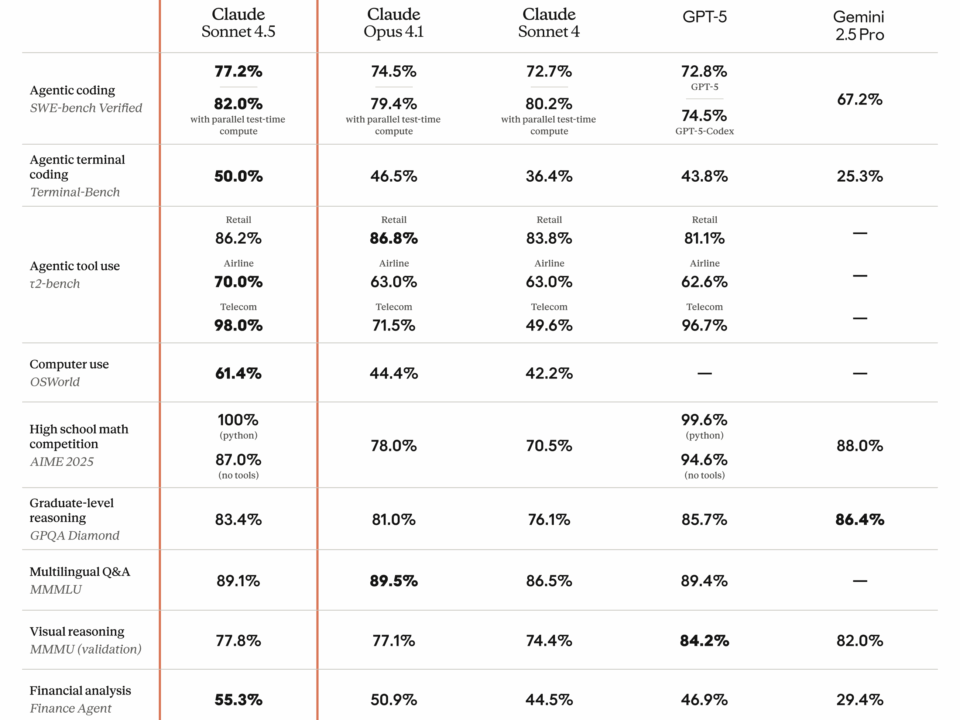
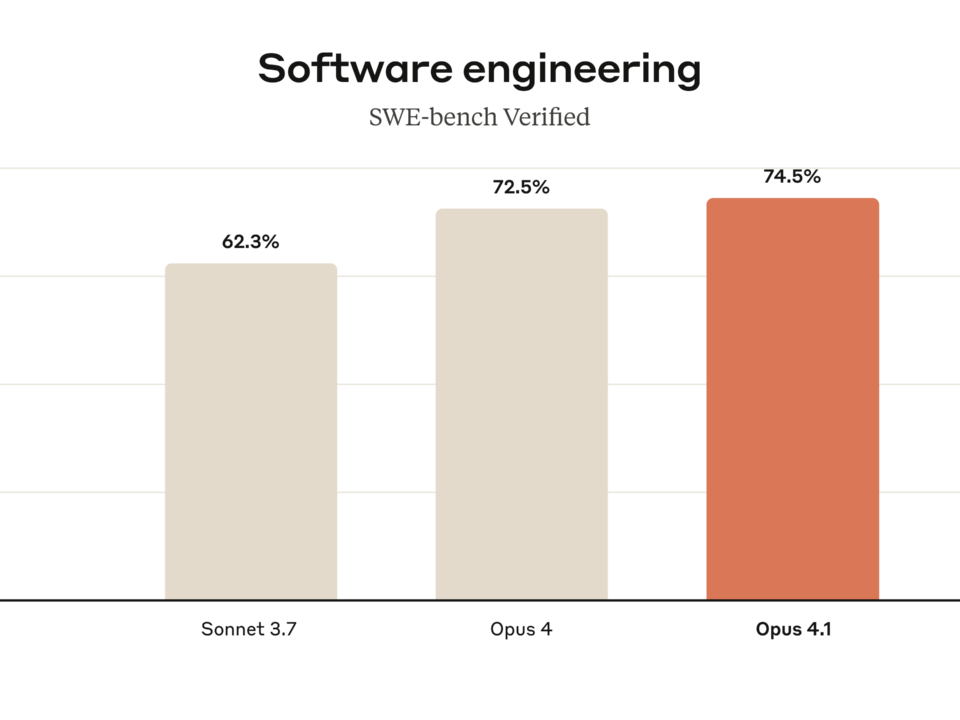
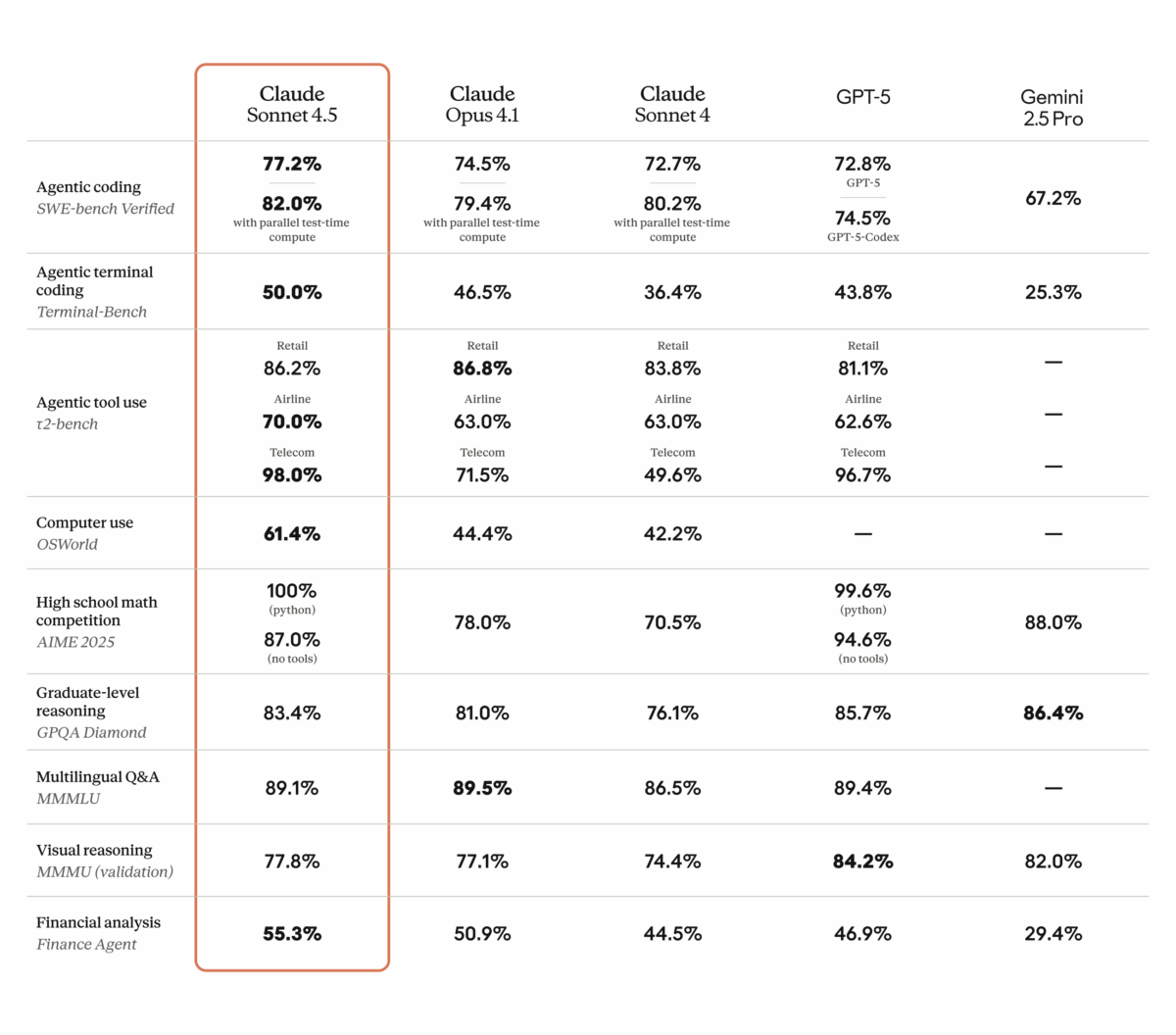
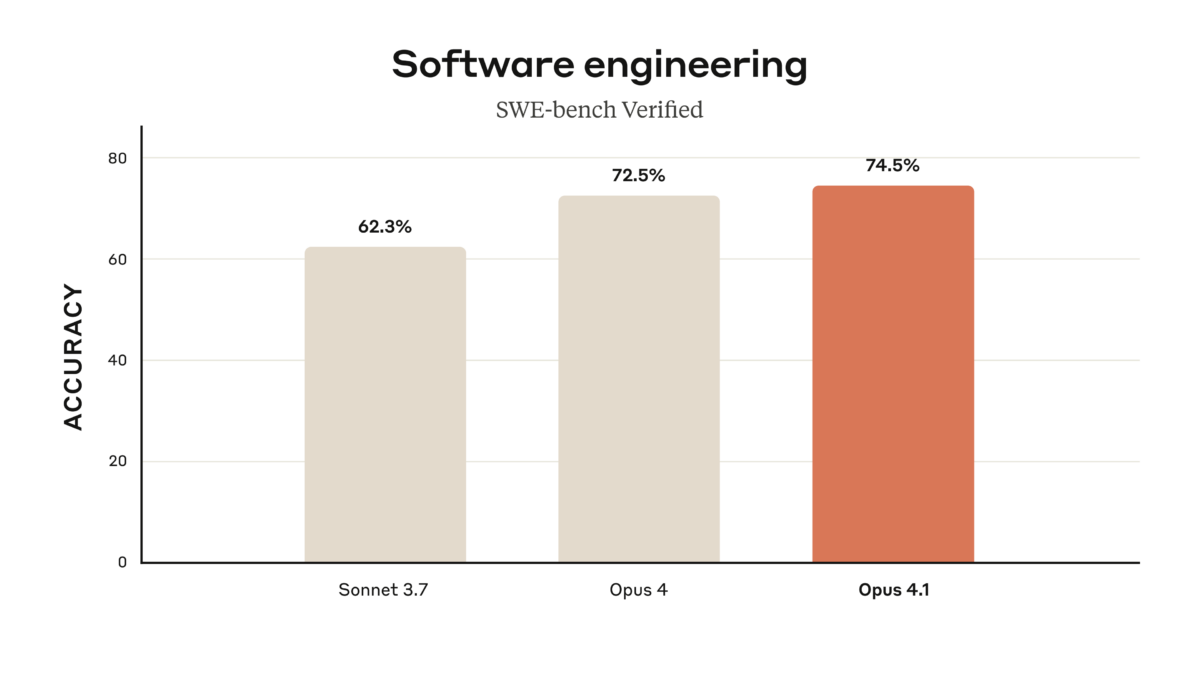
77.2% on SWE-bench Verified. That single number just rewrote the rules of the AI coding model market. Anthropic’s Claude Sonnet 4.5 benchmark results don’t just represent […]
Your AI chatbot just got a safety report card — and some models barely passed. The MLCommons AILuminate AI safety benchmark v1.0 has tested major language […]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}