
NAMM 2026 Audio Interfaces Preview: Best New Picks Under $500
January 8, 2026
NAMM 2026 Guitar and Bass Gear Preview: 7 Confirmed Highlights from Fender, Gibson, PRS
January 9, 2026
On December 20, 2024, OpenAI o3 scored 87.5% on the ARC-AGI benchmark. The previous best? 55.5%. That wasn’t an improvement—it was a category rupture. Now, in January 2026, we have a full year of hindsight to assess whether that moment was truly the inflection point it appeared to be. Spoiler: it was, and the ripple effects are still expanding across every corner of the AI industry.
How OpenAI o3 Demolished the ARC-AGI Benchmark
To understand why o3’s ARC-AGI score was such a seismic event, you need to understand what ARC-AGI actually tests. Created by Francois Chollet, the benchmark is specifically designed to evaluate the kind of abstract reasoning that humans handle intuitively but AI models have historically fumbled. We’re talking about visual pattern recognition from minimal examples, novel problem-solving that requires genuine generalization, and the ability to apply learned concepts to completely unseen scenarios. These aren’t the kind of problems you can brute-force with a bigger training dataset.
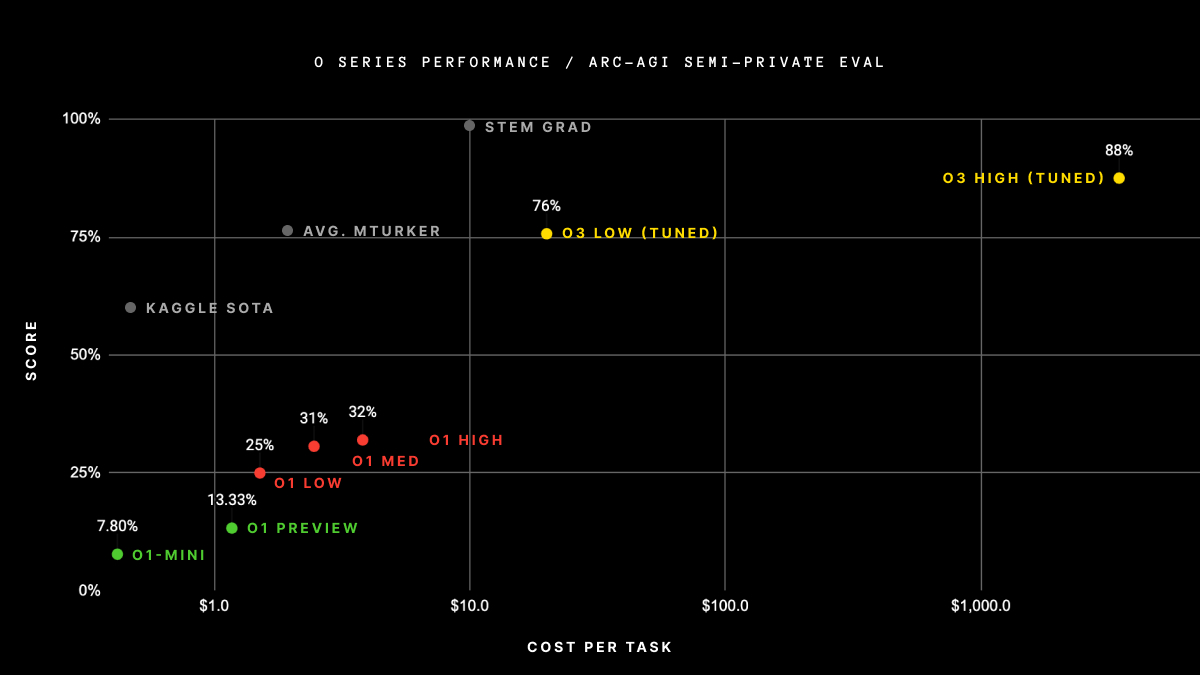
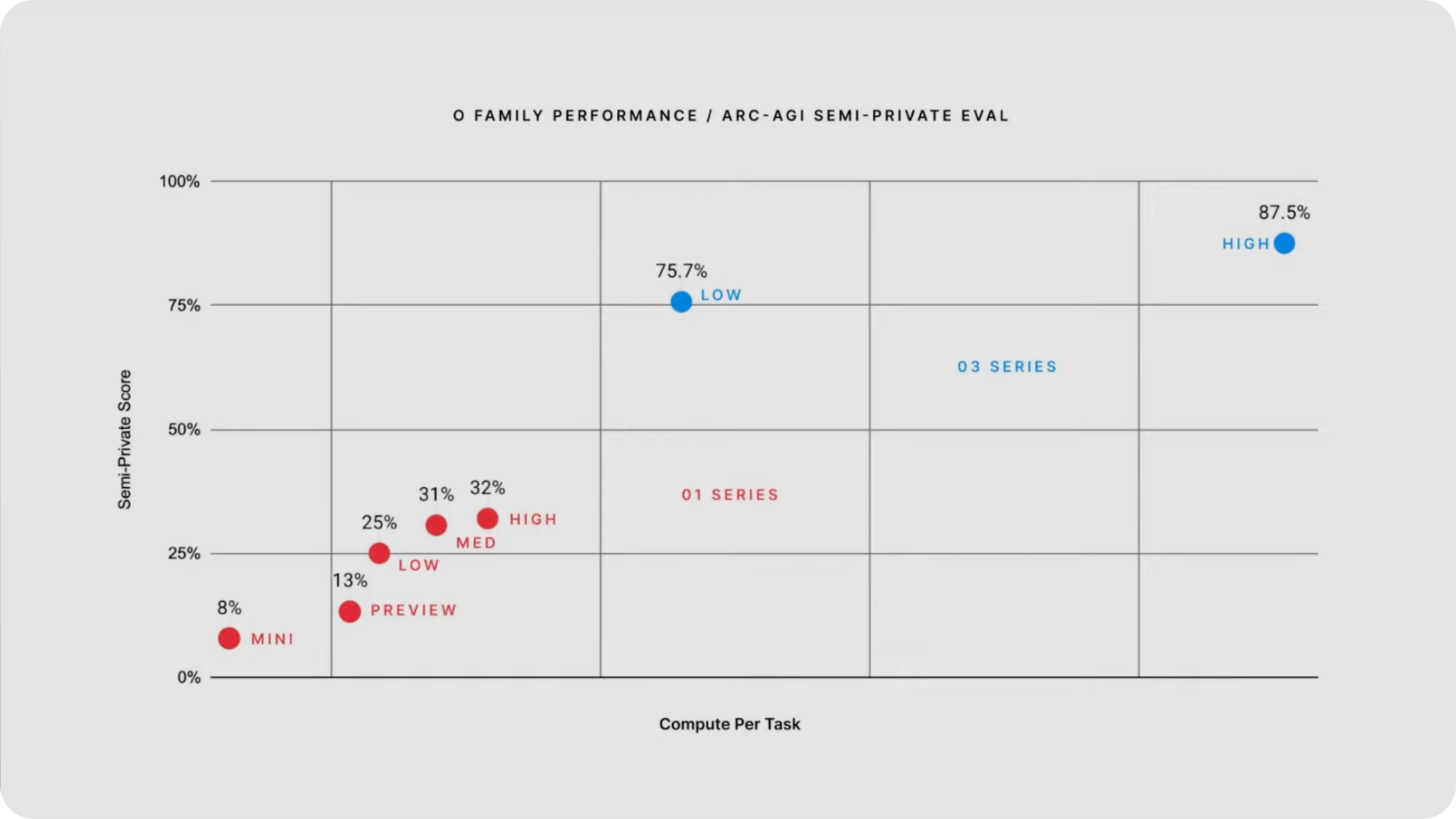
GPT-4 scored below 5% on ARC-AGI. OpenAI’s own o1 managed around 25%. Then o3 arrived and posted 75.7% in low-compute mode and 87.5% in high-compute mode. To put that in perspective: the jump from o1 to o3 on this single benchmark was larger than the cumulative progress of every AI model in the years before it.
According to the ARC Prize Foundation’s analysis, the breakthrough stems from what they call “deep learning-guided program search through natural language reasoning.” In plain English: instead of pattern-matching its way to an answer, o3 essentially writes and tests mental programs using natural language chain-of-thought. It’s closer to how a software engineer debugs a problem—forming hypotheses, writing test cases, iterating on solutions—than how a student memorizes flashcards.
The catch? High-compute mode costs $4,560 per task. That’s not a typo—and it highlights the fundamental tradeoff at the heart of reasoning models. The low-compute mode at $26 per task was far more practical for real-world applications, but even at 75.7%, it still represented a generational leap over anything that came before. The ARC Prize team was quick to note that o3 still fails some tasks that most humans find trivially easy—a fascinating reminder that these models reason in fundamentally different ways than we do, even when they outperform us on aggregate metrics.
The Benchmark Blitz: o3 by the Numbers
ARC-AGI was the headline, but o3’s dominance extended across virtually every major AI benchmark. Helicone’s detailed comparison laid out the numbers starkly:
- AIME (math competition): 96.7% vs. o1’s 83.3%—a 13.4 percentage point jump on problems designed for elite high school mathematicians
- Codeforces (competitive programming): Elo rating of 2727 vs. o1’s 1891—an 836-point leap that placed it among the top 175 human competitors globally
- EpochAI Frontier Math: 25.2% where every other model scored below 2%—this benchmark includes problems that challenge professional mathematicians
- GPQA Diamond (graduate-level science): 87.7% on PhD-level chemistry, physics, and biology questions
- SWE-bench (software engineering): 71.7% on real GitHub issue resolution
The Frontier Math result deserves special attention. This isn’t a benchmark where incremental improvements happen gradually. Every model tested before o3 was essentially guessing randomly—scoring below 2% on problems that challenge professional mathematicians with decades of experience. Then o3 solved a quarter of them. That’s not a better autocomplete—that’s a qualitatively different kind of capability, and it forced the research community to reconsider what “understanding” means in the context of artificial intelligence.
The SWE-bench results are equally telling for anyone in the software industry. At 71.7%, o3 demonstrated the ability to read real GitHub issues, understand the codebase context, and generate working fixes. This isn’t toy code generation—it’s the kind of practical engineering work that companies pay six-figure salaries for. Whether you view that as exciting or terrifying probably says a lot about your relationship with AI tools.
From o3-mini to Full o3: The Rollout Timeline
After the December 2024 announcement, OpenAI took a staged approach to release. o3-mini launched on January 31, 2025, followed by the full o3 on April 16, 2025.
o3-mini was the practical play—the model OpenAI designed for developers who needed reasoning capabilities without burning through their API budget. At $1.10 per million input tokens and $4.40 per million output tokens, it was 63% cheaper than o1-mini while being 24% faster and making 39% fewer major errors. That’s not a minor optimization; it’s the kind of cost-performance improvement that shifts reasoning AI from “interesting experiment” to “production-ready tool.”
The three-tier reasoning effort system—low, medium, and high—was perhaps o3-mini’s most underappreciated innovation. It gave developers a dial they’d never had before: the ability to calibrate cost against cognitive depth for each individual request. Need a quick factual lookup or simple classification? Low effort, fraction of a cent. Debugging a complex distributed system or analyzing a dense legal contract? Crank it to high and let the model think. This granular control over reasoning depth turned out to be exactly what enterprise customers needed to justify deploying reasoning models at scale.
The full o3, arriving in April 2025, delivered on every benchmark promise from the December announcement. It pushed state-of-the-art across coding, math, science, and visual perception simultaneously—a breadth of capability that no single model had achieved before. But the real game-changer was that o3 became the first reasoning model capable of agentically using all ChatGPT tools: web browsing, code execution, file analysis, and image generation, all within a single reasoning chain. This wasn’t just a smarter model sitting in a text box. It was a model that could plan multi-step workflows, execute them, and adapt based on intermediate results—the foundation for what many are now calling “agentic AI.”
Deliberative Alignment: The Innovation Behind the Scores
The benchmark numbers grabbed headlines, but the more consequential innovation might be what Adaline Labs’ technical deep dive calls “deliberative alignment.” Previous models had safety guardrails baked in during training—static rules that couldn’t adapt to novel situations. o3 takes a fundamentally different approach: it evaluates each prompt against safety policies in real-time, as part of its reasoning process.
Think of it this way: older models are like a driver who memorized the rules of the road during training and applies them rigidly regardless of context. o3 is like a driver who actively reasons about whether each action is safe given the current conditions—the weather, the traffic, the pedestrian who just stepped off the curb. As reasoning models grow more powerful and are deployed in higher-stakes environments, this kind of dynamic, context-aware safety evaluation becomes not just helpful but absolutely essential.
Test-Time Compute: The Paradigm Shift Under the Hood
The underlying mechanism powering o3’s reasoning—test-time search, or test-time compute scaling—fundamentally reshaped how the AI industry thinks about performance optimization. For years, the playbook was simple: want a better model? Train it on more data with more parameters. o3 demonstrated a complementary axis of improvement: you can dramatically improve outputs by scaling computation at inference time.
Here’s how it works in practice. When o3 encounters a complex problem, it doesn’t generate a single answer and hope for the best. Instead, it generates multiple candidate reasoning chains—different approaches to the same problem—evaluates their internal consistency, and selects the most promising path. It’s essentially running a search algorithm through the space of possible reasoning strategies, using its own chain-of-thought as the search medium. This paradigm influenced everything from DeepSeek’s R1 architecture to Google’s approach with Gemini’s reasoning capabilities throughout 2025, making test-time compute one of the most actively researched topics in AI.
What o3 Actually Changed: A One-Year Assessment
Looking back from January 2026, o3’s impact crystallizes around three fundamental shifts in the AI landscape.
Inference scaling became a first-class performance lever. Before o3, the recipe for better AI was straightforward: more data, bigger models. o3 proved that how much a model thinks—not just how much it learned—matters enormously. This insight spawned an entire category of “reasoning-aware” applications and architectures. Developers now routinely design systems where the reasoning budget is a tunable parameter, adjusting the depth of thought based on task complexity and cost constraints. A customer service chatbot answering routine questions doesn’t need deep reasoning. A medical diagnostic assistant does. o3 gave us the framework to build both from the same foundation.
The competitive landscape was completely redrawn. Every major AI lab pivoted to reasoning model development in the months following o3’s release. Google accelerated Gemini’s reasoning capabilities with their own chain-of-thought innovations. Anthropic invested heavily in Claude’s reasoning architecture, producing models that could match o3’s depth on many tasks. Perhaps most significantly, the open-source community—led by DeepSeek with their R1 model—proved that reasoning capabilities could be built without OpenAI’s proprietary resources and budget. The result? By January 2026, the “reasoning model” isn’t a novelty—it’s table stakes. If your AI product can’t reason, it’s already obsolete.
New benchmarks emerged because o3 broke the old ones. The ARC Prize Foundation acknowledged o3’s achievement while noting its inconsistencies on problems humans find trivial—a five-year-old could solve certain spatial reasoning puzzles that stumped o3 completely. Their response: ARC-AGI-2, a significantly harder test designed to probe the specific gaps between human and machine reasoning. This cycle—breakthrough, benchmark saturation, harder benchmark—is now the established rhythm of AI progress, and o3 set the tempo.
For businesses, the implications are concrete. Reasoning models aren’t just research curiosities—they’re production tools. Companies are using o3-class models for contract analysis, code review, scientific literature synthesis, and complex decision support. The key insight from the past year is that the ROI of reasoning AI depends heavily on matching the reasoning budget to the task value. Not every problem needs $4,560 worth of computation, but some problems are worth far more than $26.
The deeper lesson from o3’s first year isn’t about any single benchmark score. It’s that AI crossed a threshold from sophisticated pattern matching to something that genuinely resembles reasoning—imperfect, expensive, and occasionally baffling in its blind spots, but fundamentally different from what came before. As CES 2026 showcases AI products built on these reasoning foundations, the question for businesses and developers isn’t whether to adopt reasoning AI, but how to architect systems that leverage inference-time intelligence effectively. The companies that figure this out first won’t just be using AI—they’ll be thinking with it.
Looking to integrate reasoning AI models into your workflow, or need help building intelligent automation pipelines? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}