GPT-5.1 Developer Guide: 5 Things apply_patch and shell Tool Changed — A New Standard for Instruction Following
November 4, 2025
Google Gemini 3 Launch: Multimodal Reasoning Over Text, Code, and Video
November 6, 2025
80% accuracy on SWE-Bench. 24 hours of continuous coding. Zero degradation. GPT-5.1-Codex-Max is OpenAI’s most ambitious agentic coding model to date, launched on November 20, 2025, and it is rewriting the rules of what AI can do in software development. With a 14-percentage-point jump over its predecessor and a revolutionary compaction technology that handles millions of tokens across multiple context windows, this model represents a genuine inflection point for AI-assisted development.
In this deep dive, we will examine the five key breakthroughs that make GPT-5.1-Codex-Max a potential game-changer for developers, engineering teams, and the broader software industry. From benchmark-shattering performance to a completely new approach to context management, here is everything you need to know about OpenAI’s latest and most capable coding model.
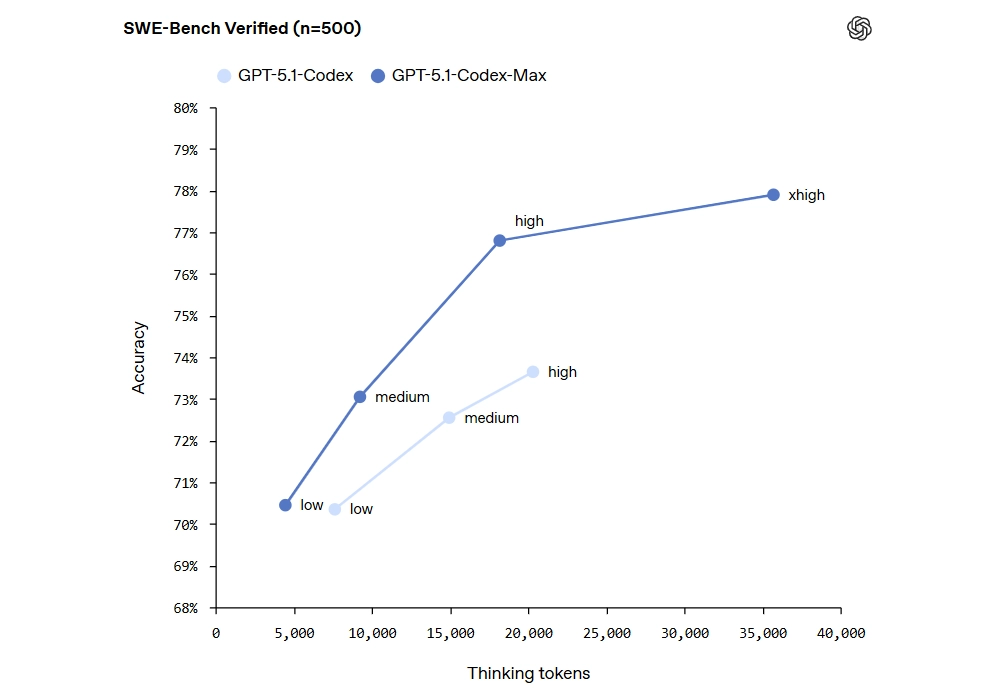
GPT-5.1-Codex-Max Performance: Smashing SWE-Bench With 80% Accuracy
The headline number is impossible to ignore. GPT-5.1-Codex-Max achieved 79.9% accuracy on the SWE-Lancer IC SWE benchmark, a dramatic leap from the previous model’s 66.3%. This is not a cherry-picked metric on a narrow test. SWE-Bench evaluates a model’s ability to understand real-world software engineering tasks, including finding bugs in actual open-source projects, generating patches, and verifying that those patches actually resolve the issues.
What makes this benchmark score particularly significant is the nature of the tasks involved. These are not simple code completion exercises or isolated function generation tests. The model must navigate complex codebases with intricate dependency chains, understand the relationships between files and modules, identify root causes of failures buried deep in the code, and produce working fixes that do not introduce regressions. An 80% success rate on tasks that often challenge experienced human developers signals a meaningful shift in AI coding capabilities.
The improvement did not come from simply scaling up parameters. OpenAI achieved this through fundamental architectural innovations, particularly the compaction system that allows the model to maintain coherent reasoning across massive codebases. The model also generates 30% fewer thinking tokens while producing cleaner output, which means it is not just more accurate but significantly more efficient in how it arrives at solutions. This efficiency gain has direct implications for teams deploying the model at scale, as it translates to lower compute costs per task.
To put the 14-percentage-point improvement in perspective, consider that the gap between 66% and 80% on SWE-Bench is not a linear improvement. The remaining tasks at higher accuracy levels tend to be exponentially harder, involving more complex codebases, subtler bugs, and more intricate fix requirements. Clearing that hurdle required not just incremental tuning but a rethinking of how the model processes and reasons about code.
Compaction Technology: How GPT-5.1-Codex-Max Processes Millions of Tokens
If the SWE-Bench score is the headline, compaction is the story behind it. Previous AI coding models faced a fundamental constraint: the context window. No matter how powerful the model, it could only “see” a limited amount of code at once. For enterprise-scale projects with hundreds of thousands of lines across thousands of files, this was a dealbreaker for autonomous coding tasks. The model might understand a single file perfectly but miss how changes in that file would cascade through the rest of the system.
GPT-5.1-Codex-Max solves this with native multi-context window processing via compaction. Rather than trying to cram everything into a single context window, the model can coherently work across millions of tokens in a single task. It intelligently compresses and prioritizes information, maintaining the semantic relationships between distant parts of a codebase while discarding redundant details that do not contribute to the current task.
Think of it like a senior developer who can keep a mental model of an entire system architecture while diving deep into specific implementation details. The developer does not need to re-read every file to understand how a change will propagate. Similarly, GPT-5.1-Codex-Max does not lose track of how a modification in one file might ripple through dependencies, configurations, and test suites in another. This capability is what enables truly autonomous multi-file project work, something that was previously possible only in narrow, well-constrained scenarios with limited codebases.
For teams working on large monorepos or microservice architectures, compaction means the AI can finally understand the full picture. It can trace a bug from an API endpoint through middleware layers, authentication logic, and business rules, all the way down to a database query, understanding the entire chain without losing context along the way. This is not a theoretical capability. It is the direct enabler of the 80% SWE-Bench performance, because real-world bug fixes rarely involve just a single file.
The practical impact for development teams is substantial. Code review tasks that previously required a human developer to hold the entire system in their head can now be offloaded to the model with confidence that it will catch cross-file issues. Refactoring projects that touch dozens of files can be planned and executed by the model while maintaining consistency across the entire changeset.
24-Hour Continuous Coding Sessions Without Performance Degradation
One of the most persistent problems with AI coding assistants has been session degradation. The longer a session runs, the more the model tends to drift, lose context, or produce increasingly inconsistent output. Developers learned to work around this by breaking tasks into smaller chunks and starting fresh sessions, but this approach was cumbersome and lost accumulated context. GPT-5.1-Codex-Max eliminates this problem entirely with 24-hour continuous coding sessions that maintain consistent quality from the first minute to the last.
This is not just a technical achievement. It fundamentally changes how teams can deploy AI coding assistance in their daily operations. Consider the implications for continuous integration pipelines that run overnight, automated code reviews on large pull requests, or comprehensive refactoring projects that span hundreds of files. A model that can work reliably for 24 hours straight means you can assign substantial, time-intensive tasks at the end of a workday and have results ready for review the next morning, with full confidence that the output quality at hour 23 is identical to hour 1.
The efficiency gains extend well beyond just session duration. GPT-5.1-Codex-Max uses 30% fewer thinking tokens than its predecessor while generating cleaner, more maintainable code. This translates directly to lower API costs for teams running the model at scale, making it economically viable for a wider range of use cases. When you combine reduced token usage with the extended session capability, the cost-per-task equation shifts dramatically in favor of AI-assisted development. A task that might have required multiple expensive sessions can now be completed in a single, more efficient run.
The model is accessible through CLI tools, IDE extensions like VS Code and JetBrains integrations, and cloud platforms, making it straightforward to adopt regardless of your team’s preferred development environment or toolchain. This flexibility in deployment options means teams can start small with individual developer usage and scale up to team-wide automated workflows as they build confidence in the model’s capabilities.

Native Windows Support and Enhanced Agentic Autonomy
GPT-5.1-Codex-Max is the first OpenAI coding model to offer native Windows environment support. While this might seem like a minor feature compared to the performance benchmarks, it addresses a significant and long-standing gap in the market. A huge portion of enterprise development still happens on Windows, particularly in industries like finance, healthcare, and government contracting where Windows-based development environments are standard. Previous AI coding tools optimized primarily for Linux environments left these Windows-centric developers as second-class citizens, unable to fully leverage AI coding assistance in their native development environments.
With native Windows support, GPT-5.1-Codex-Max can interact directly with Windows-specific toolchains, build systems, and testing frameworks. This means .NET developers, PowerShell script maintainers, and teams working with Windows-specific APIs can now benefit from the same level of AI assistance that was previously available mainly to developers on Linux and macOS. The model understands Windows-specific path conventions, file system behaviors, and platform-specific APIs, reducing the friction that previously existed when using AI tools in Windows environments.
More importantly, the model’s agentic autonomy has taken a major step forward. GPT-5.1-Codex-Max can independently perform end-to-end software development tasks without constant human guidance. This includes writing code from high-level specifications, generating comprehensive test suites, running those tests, debugging any failures that emerge, conducting thorough code reviews, and creating well-documented pull requests. The model does not just suggest code snippets and wait for approval. It executes complete development workflows with minimal human oversight, only escalating when it encounters genuine ambiguity or design decisions that require human judgment.
The internal adoption numbers at OpenAI are perhaps the most telling validation. With 95% of OpenAI’s own engineers using Codex weekly and experiencing a 70% increase in PR submissions, this is a tool that has already proven its value in one of the most demanding and high-stakes engineering environments in the industry. When the people building AI models choose to use their own AI coding assistant as a daily driver, that is the strongest possible signal about the tool’s practical utility and reliability. These are not engineers who would tolerate a tool that slows them down or produces mediocre results.
What GPT-5.1-Codex-Max Means for the Future of Software Development
The release of GPT-5.1-Codex-Max is not just another model announcement in an increasingly crowded AI landscape. It represents a tangible, measurable milestone in the trajectory of AI software development automation. An 80% accuracy rate on real-world software engineering benchmarks means AI can now reliably handle tasks that previously required dedicated junior developer time, and it can do so around the clock without breaks, context loss, or declining quality.
- Independent code review and debugging across multi-file projects with full codebase awareness
- Compaction technology enabling comprehensive codebase comprehension at enterprise scale
- 24-hour continuous operation for uninterrupted development cycles and overnight automation
- 30% fewer thinking tokens for cost-effective, cleaner, and more maintainable code generation
- Multiple access points via CLI, IDE extensions, and cloud platforms for flexible integration
- Native Windows environment support bringing parity to Windows-centric development teams
To be clear, GPT-5.1-Codex-Max does not replace human developers. Architecture decisions, creative problem-solving, nuanced business logic, and the kind of holistic product thinking that drives great software still require human judgment, experience, and intuition. But the model shifts the balance of developer time decisively. Instead of spending hours on routine bug fixes, tedious code reviews, boilerplate implementation, and repetitive debugging sessions, engineers can focus on the high-leverage work that actually requires human creativity, domain expertise, and strategic thinking.
The combination of compaction, sustained performance over extended sessions, and genuine agentic autonomy creates something qualitatively different from previous AI coding tools. This is not an incremental improvement or a slightly better autocomplete. It is a new category of developer tool altogether, one that can serve as a reliable, tireless coding partner for complex, long-running software engineering tasks that previously demanded human attention from start to finish.
The question for development teams is no longer whether to adopt AI coding assistance. The evidence from OpenAI’s own engineering team, with their 95% adoption rate and 70% productivity boost, makes that question almost rhetorical. The real question is how quickly teams can integrate GPT-5.1-Codex-Max into their existing workflows, establish appropriate review processes for AI-generated code, and restructure their development practices to take full advantage of a coding partner that literally never needs to sleep.
Need help building AI-powered development pipelines or tech consulting? Sean Kim brings 28+ years of experience.
Get weekly AI, music, and tech trends delivered to your inbox.