
Garmin Venu 4 Launch: AMOLED Display, ECG, Flashlight, and 12-Day Battery for $549
September 25, 2025
How to EQ Kick and Bass: 7 Frequency Carving Techniques That Actually Clean Up Your Low End
September 26, 2025
Three major open-source model drops in a single month. Alibaba shipped Qwen3-Max, Qwen3-Next, and Qwen3-Omni in rapid succession. DeepSeek quietly published V3.2-Exp with a sparse attention mechanism that slashes inference costs by half. And as of July 2025, China accounts for 1,509 of the world’s roughly 3,755 publicly released LLMs — over 40%. If you’re still thinking of open-source AI as a Western-led movement, September 2025 is the month that narrative officially died.
Qwen3 September Blitz: Three Models in 22 Days
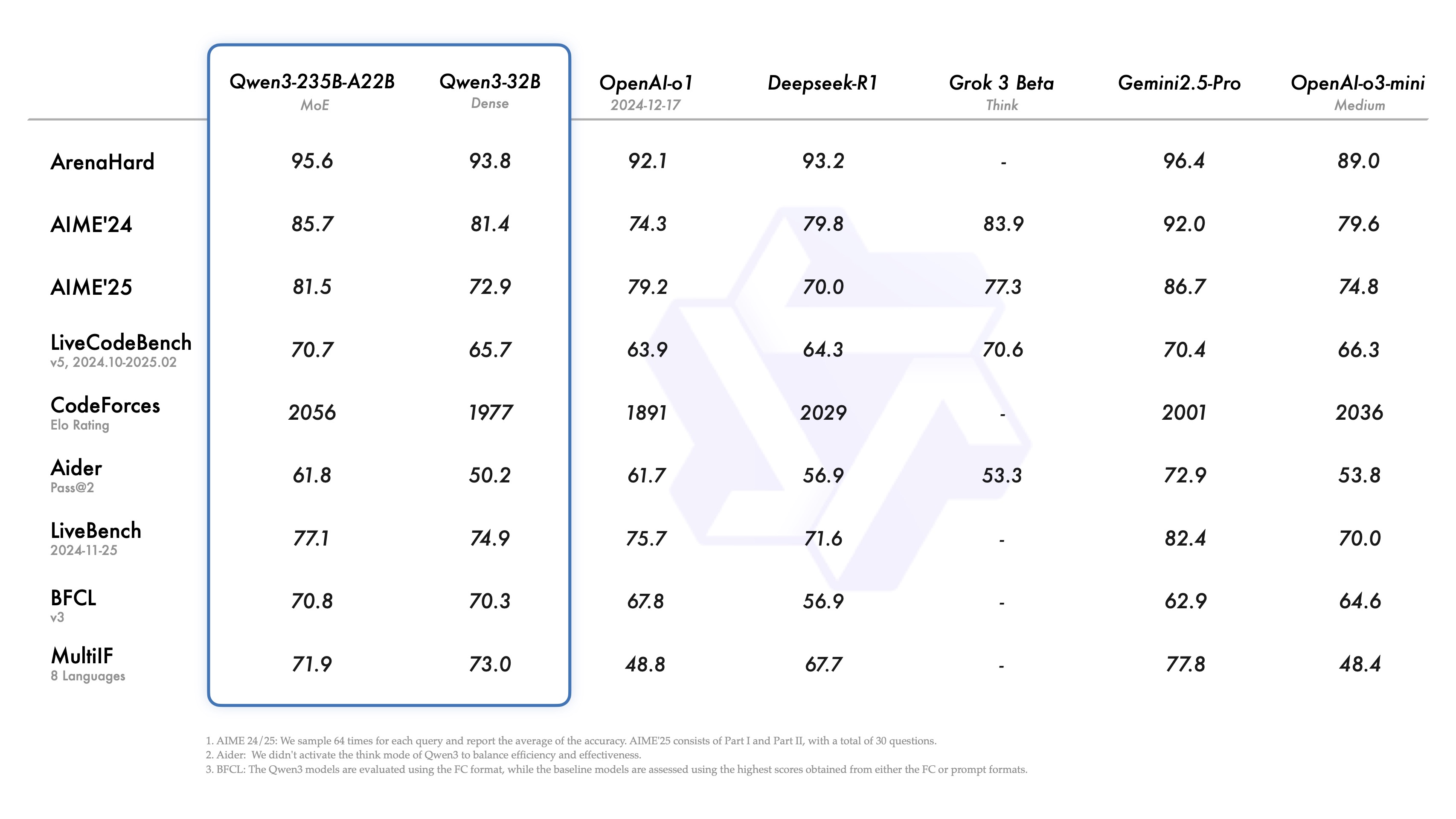
Alibaba’s Qwen team didn’t just release a model in September — they released an entire ecosystem. On September 5, Qwen3-Max launched as a closed-weight, API-only model boasting 1 trillion parameters. It’s their biggest model ever, surpassing the previous 235B Qwen by over 4x in raw parameter count. While you can’t download the weights, the API pricing undercuts GPT-4 significantly.
Five days later, on September 10, Qwen3-Next-80B-A3B dropped under the Apache 2.0 license. This is where things get interesting for developers. The model has 80 billion total parameters but only activates 3 billion during inference — a Mixture-of-Experts (MoE) architecture that delivers GPT-4-class reasoning at a fraction of the compute cost. You can run it on a single A100 GPU.
Then on September 22, Qwen3-Omni arrived — and this one changes the game entirely. It’s a natively end-to-end omni-modal model that processes text, images, audio, and video as inputs, while generating both text and real-time speech as outputs. All under Apache 2.0. No restrictions on commercial use. You can deploy it in production tomorrow.
DeepSeek V3.2-Exp: Sparse Attention That Actually Works
While Alibaba was grabbing headlines, DeepSeek quietly published V3.2-Exp on September 29 — and the technical innovation here deserves more attention than it’s getting. Built on top of V3.1-Terminus, this 671-billion-parameter model introduces DeepSeek Sparse Attention (DSA), a fine-grained sparse attention mechanism that dramatically improves long-context training and inference efficiency.
The numbers tell the story. On MMLU-Pro, V3.2-Exp maintains the same 85.0 score as its predecessor. AIME 2025 Pass@1 actually improved slightly to 89.3. Codeforces rating jumped from 2046 to 2121. In other words, DeepSeek achieved massive efficiency gains without sacrificing any quality — the holy grail of model optimization.
The 128K token context window handles book-length documents and multi-session conversations. And here’s the kicker: DeepSeek simultaneously dropped API prices by over 50%. When a model gets both better and cheaper at the same time, that’s not an incremental update — that’s a paradigm shift in how we think about inference economics.
The Chinese Open Source LLM Dominance: By the Numbers
Let’s step back and look at the bigger picture. According to IntuitionLabs’ September 2025 analysis, China now accounts for roughly 40% of all publicly released LLMs globally. This isn’t just about quantity — it’s about quality and strategic positioning.
The headline models tell the story: Alibaba’s Qwen series (from 0.5B to 1T parameters), DeepSeek’s V3/R1 family, Zhipu AI’s GLM-4.5 (355B), ByteDance’s Kimi K2, Moonshot’s K1.5, and Baidu’s newly open-sourced Ernie. Every single one of these uses Mixture-of-Experts architectures. Every single one supports 128K+ token context windows. And most are released under Apache 2.0 or similarly permissive licenses.

The strategic implications are significant. While U.S. companies like OpenAI and Anthropic keep their frontier models closed, Chinese labs are flooding the open-source ecosystem with competitive alternatives. For developers building AI applications, this means more options, lower costs, and less vendor lock-in. For the AI industry as a whole, it means the center of gravity for open-source AI has permanently shifted eastward.
01.AI’s Strategic Pivot: Yi Team Pauses Pretraining
Not every Chinese AI lab is following the “bigger model” playbook. 01.AI, led by AI pioneer Kai-Fu Lee, made waves this year by announcing they would pause pretraining new foundation models to focus on productizing existing ones. Their latest offering, Yi-Lightning, is a speed-optimized MoE variant that prioritizes inference latency over raw benchmark scores.
Yi-Lightning currently ranks approximately 6th on the LMSYS Chatbot Arena — a respectable position that demonstrates you don’t need a trillion parameters to build a competitive model. The decision to stop the parameter arms race and focus on deployment, enterprise integration, and real-world applications is a bet that the market values reliability and cost-efficiency over benchmark bragging rights.
This pivot is worth watching because it may signal where the broader industry is heading. As foundation models commoditize, the value shifts from training the biggest model to building the best products on top of existing ones.
What This Means for Developers in September 2025
If you’re building AI-powered applications right now, September 2025 just handed you an embarrassment of riches. Here’s the practical takeaway:
- For multimodal applications: Qwen3-Omni under Apache 2.0 is the clear winner. Text, image, audio, video in — text and speech out. No API dependency required.
- For cost-sensitive deployments: Qwen3-Next-80B-A3B gives you frontier-level reasoning with only 3B active parameters. Run it on hardware you already own.
- For long-context workloads: DeepSeek V3.2-Exp’s Sparse Attention mechanism makes 128K context windows actually affordable at scale.
- For enterprise production: Yi-Lightning offers the fastest inference times with competitive quality, ideal for real-time applications.
- For research and experimentation: The Apache 2.0 licensing on Qwen3-Next and Qwen3-Omni means zero restrictions on fine-tuning, distillation, or commercial deployment.
The MoE Architecture Consensus
One trend that’s impossible to ignore: every major open-source LLM released in 2025 uses Mixture-of-Experts. Qwen3-Next (80B total, 3B active), DeepSeek V3.2 (671B total, ~37B active), GLM-4.5 (355B), Yi-Lightning — all MoE. The dense model era is effectively over for frontier-scale open-source AI.
This consensus matters because MoE fundamentally changes the economics of AI deployment. You get trillion-parameter-class knowledge encoded in a model that runs with single-digit-billion active parameters. The training cost is higher, but inference cost — which is what actually matters for production — drops dramatically. For anyone running AI at scale, this is the most important architectural shift since the transformer itself.
September 2025 will be remembered as the month when open-source AI stopped being a compromise. With Qwen3-Omni, DeepSeek V3.2, and dozens of other Chinese-led models, the open-source ecosystem now rivals — and in some cases surpasses — the best closed models from Silicon Valley. The question is no longer whether open-source AI can compete. It’s whether closed-source AI can justify its premium.
Need help building AI pipelines with open-source models, or evaluating which LLM fits your production stack? Let’s talk architecture.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}