
Framework Laptop 16 AMD Radeon Edition: Modular Gaming Laptop Review
June 25, 2025
Summer Production Challenge: How to Make a Full Track in One Hour — Templates, Workflow Hacks, and the 60-Minute Rule
June 26, 2025
Stop paying $200 a month for AI APIs. By June 2025, open source LLM self-hosting 2025 has reached a tipping point: seven models now deliver GPT-4-class intelligence on hardware you can buy today. Meta’s Llama 4 Scout fits on a single GPU with a 10-million-token context window. DeepSeek R1 matches OpenAI o1 reasoning under an MIT license. And Microsoft’s 14B Phi-4 outperforms models five times its size. The era of renting intelligence is officially optional.
This isn’t just about saving money. Self-hosting means your data never leaves your servers. Your prompts aren’t training someone else’s model. Your latency drops to milliseconds instead of waiting in API queues. And with tools like Ollama and vLLM maturing rapidly, spinning up a production-grade LLM takes minutes, not months.
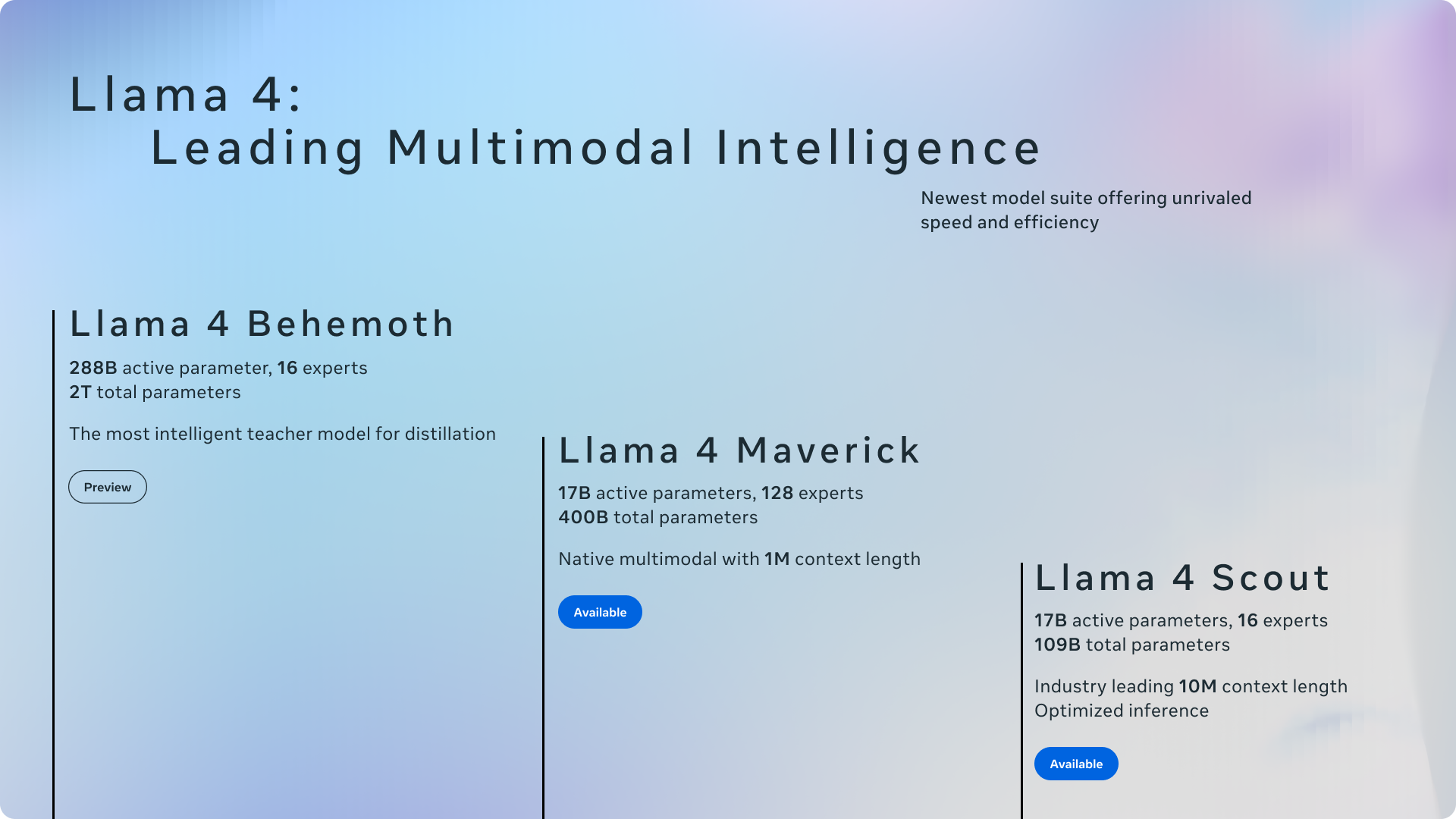
Here are the seven best open-source models for self-hosting in June 2025, ranked by capability, accessibility, and real-world deployment readiness.
1. Meta Llama 4 Scout — The Industry-Leading MoE Powerhouse
Llama 4 Scout arrived in April 2025 and immediately redefined what an open-weight model can do. With 109 billion total parameters distributed across 16 mixture-of-experts (MoE) modules, only 17 billion parameters activate per inference call. The result: GPT-4o-class performance that fits on a single H100 GPU.
The headline feature is a 10-million-token context window — the longest of any open-weight model available today. For self-hosting, this means you can process entire codebases, lengthy legal documents, or months of conversation history in a single pass. According to Meta AI, Scout beats both Gemma 3 and Gemini 2.0 Flash-Lite on multiple benchmarks while maintaining native multimodal capabilities for text and image processing.
- Parameters: 109B total (17B active), 16-expert MoE
- Context Window: 10M tokens
- License: Llama Community License
- VRAM Required: 80GB (single H100 or A100)
- Best For: Teams needing frontier-model performance with massive context on dedicated hardware
2. DeepSeek R1 — MIT-Licensed Reasoning That Rivals o1
DeepSeek R1 triggered what the industry calls the “DeepSeek moment” when it launched in January 2025. This 671B MoE model (37B active parameters) matches OpenAI’s o1 on mathematical reasoning and complex coding tasks — at roughly 95% lower cost when self-hosted. And it ships under an MIT license, meaning no restrictions on commercial use whatsoever.
For organizations that need chain-of-thought reasoning, advanced math capabilities, or code generation that actually works, DeepSeek R1 is the strongest open-source option available. The model is available through Ollama in multiple quantized variants, making it accessible even on multi-GPU consumer setups.
- Parameters: 671B total (37B active), MoE architecture
- Context Window: 32K tokens (128K extended)
- License: MIT (fully permissive)
- VRAM Required: 48-80GB for quantized versions, multi-GPU for full precision
- Best For: Research teams, coding assistants, and math-heavy applications requiring reasoning depth
3. Qwen 2.5 72B — The Dense Model Sweet Spot
If MoE models feel too complex for your infrastructure, Qwen 2.5 72B is the best dense model you can self-host today. Released by Alibaba under Apache 2.0 — the most permissive license in the lineup — it supports 29 languages and has built the largest fine-tuning community outside of Llama.
The 128K context window handles enterprise-grade document processing, and quantized versions (Q4) run on 48GB VRAM cards like the NVIDIA A6000. As one benchmarking analysis noted, Qwen 2.5 72B consistently outperforms Llama 3.1 70B on multilingual tasks while maintaining competitive English performance. The extensive Hugging Face ecosystem means you’ll find fine-tuned variants for virtually every vertical.
- Parameters: 72B dense
- Context Window: 128K tokens
- License: Apache 2.0 (fully permissive)
- VRAM Required: 48GB (Q4 quantized), 80GB+ (full precision)
- Best For: Multilingual enterprise deployments, RAG pipelines, and teams wanting maximum fine-tuning flexibility
4. Google Gemma 3 27B — Consumer GPU Champion
Gemma 3 is Google’s open-source play, and the 27B variant is arguably the best model you can run on a single consumer GPU. Released in March 2025, it fits on a 24GB RTX 4090 in quantized form and punches well above its weight class on the LMArena leaderboard.
Built on Gemini 2.0 research, Gemma 3 supports 140+ languages natively and includes multimodal capabilities for both text and image understanding. For developers building local AI assistants or running inference on gaming hardware they already own, Gemma 3 27B offers the best performance-per-dollar ratio in the current landscape.
- Parameters: 27B dense
- Context Window: 128K tokens
- License: Gemma License (permissive, commercial use allowed)
- VRAM Required: 24GB (Q4 quantized on RTX 4090/3090)
- Best For: Developers on consumer hardware, local AI assistants, and multilingual applications

5. Microsoft Phi-4 Reasoning — Small Model, Big Brain
Phi-4 Reasoning proves that parameter count isn’t everything. At just 14 billion parameters, this MIT-licensed model from Microsoft beats DeepSeek-R1-Distill-70B — a model five times its size — on reasoning benchmarks. The secret: distillation from OpenAI’s o3-mini, which bakes chain-of-thought reasoning directly into the model weights.
For self-hosting, the implications are massive. Phi-4 runs on 16GB VRAM — that’s an RTX 4080 or even an M2 Pro MacBook. You get genuine reasoning capabilities on hardware that costs under $1,000. If you need a smart, fast, lightweight model for edge deployment or development workflows, Phi-4 is the clear winner in its class.
- Parameters: 14B dense
- Context Window: 16K tokens
- License: MIT (fully permissive)
- VRAM Required: 16GB (runs on RTX 4080, M2 Pro)
- Best For: Edge deployment, developer tools, reasoning tasks on budget hardware
6. Mistral Small 3 (24B) — The Production Workhorse
Mistral has carved out a reputation for building models that just work in production, and Mistral Small 3 continues that tradition. At 24B parameters under Apache 2.0, it’s designed for low-latency inference on edge devices and production servers where every millisecond of response time matters.
Where Mistral Small 3 shines is in instruction following and code generation. It handles structured output reliably, follows complex multi-step instructions without hallucinating, and integrates seamlessly with existing OpenAI-compatible APIs. For teams deploying customer-facing AI features that need consistent, predictable behavior, this is the model to benchmark against.
- Parameters: 24B dense
- Context Window: 32K tokens
- License: Apache 2.0 (fully permissive)
- VRAM Required: 24GB (Q4 quantized)
- Best For: Production APIs, customer-facing applications, and low-latency inference
7. Cohere Command R+ (104B) — The RAG Specialist
Command R+ fills a niche that no other open model addresses as well: retrieval-augmented generation. At 104B total parameters (16B active via MoE), it’s specifically optimized for grounded generation — answers backed by your documents, not hallucinated facts. If you’re building enterprise search, knowledge bases, or document Q&A systems, Command R+ is purpose-built for exactly that.
The model supports 10+ languages natively and includes built-in tool-use capabilities, meaning it can call external APIs, search databases, and chain actions together without prompt engineering gymnastics. The CC-BY-NC license means it’s free for research and internal use, though commercial deployments require a separate agreement with Cohere.
- Parameters: 104B total (16B active), MoE
- Context Window: 128K tokens
- License: CC-BY-NC 4.0 (non-commercial free, commercial requires license)
- VRAM Required: 48-80GB
- Best For: Enterprise RAG, document search, and grounded Q&A systems
Open Source LLM Self-Hosting 2025: Essential Deployment Tools
Having a great model is only half the equation. You need the right infrastructure to serve it. Here are the four tools that matter in June 2025:
Ollama — The Docker of LLMs
Ollama remains the fastest way to get a model running locally. One command — ollama run llama4-scout — and you have an OpenAI-compatible API endpoint serving on localhost. It bundles llama.cpp under the hood, handles automatic quantization, and supports macOS, Linux, and Windows. Best for: development, personal use, and quick prototyping.
vLLM — Production-Grade Inference
When Ollama isn’t enough, vLLM is the answer. Its PagedAttention algorithm delivers up to 19x higher throughput than naive inference, with continuous batching and speculative decoding that keeps GPU utilization above 90%. If you’re serving multiple concurrent users or building an internal API that needs to handle real traffic, vLLM is the production standard.
llama.cpp — Universal Foundation
The C/C++ inference engine that started the local LLM revolution. Zero dependencies, runs on everything from data center GPUs to smartphones. Ollama builds on top of llama.cpp, but using it directly gives you maximum control over quantization formats, memory management, and hardware-specific optimizations.
Hugging Face TGI — Enterprise Integration
Text Generation Inference from Hugging Face integrates directly with the HF model hub, making it the easiest option for organizations already embedded in the Hugging Face ecosystem. Solid enterprise option with good monitoring and scaling capabilities.
GPU VRAM Guide: What You Actually Need
The most common question in self-hosting is “what GPU do I need?” Here’s the real breakdown for June 2025:
- 8GB VRAM (RTX 4060, M1 MacBook): 7B models in Q4 quantization — Phi-4-mini, Gemma 3 1B. Good for experimentation, not production.
- 16GB VRAM (RTX 4080, M2 Pro): 13-14B models in Q4-Q8 — Phi-4 Reasoning, Qwen 2.5 14B. The sweet spot for personal productivity.
- 24GB VRAM (RTX 4090, RTX 3090): 27-30B models in Q4 — Gemma 3 27B, Mistral Small 3. Serious local AI capability.
- 48GB VRAM (A6000, dual-GPU setups): 70B+ models quantized — Qwen 2.5 72B in Q4. Enterprise-grade on workstation hardware.
- 80GB VRAM (H100, A100): Full-precision 70B+ models, Llama 4 Scout on a single card. Data center territory.
A practical tip: if you’re starting out, grab an RTX 4090 (24GB) and run Gemma 3 27B or Mistral Small 3 through Ollama. You’ll have a local AI assistant that rivals cloud APIs for most tasks, with zero ongoing costs after the hardware investment.
The Bottom Line
June 2025 marks the point where self-hosting an LLM stops being a hobby project and becomes a genuine business strategy. The models are good enough, the tools are mature enough, and the hardware is accessible enough. Whether you’re a solo developer with a gaming GPU or an enterprise team with dedicated infrastructure, there’s an open-source model on this list that fits your needs.
The smartest approach is to start small: install Ollama, pull Phi-4 or Gemma 3, and test it against your actual use cases. Once you’ve validated the quality meets your bar, scale up to vLLM and a larger model. That’s the path from API dependency to AI independence — and it’s never been shorter than it is right now.
Need help building an AI pipeline, deploying self-hosted LLMs, or automating your infrastructure? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}