
Google Nest Cam Outdoor 2025 Leaked: 2K HDR, 6x Zoom, and Gemini AI Transform Home Security
August 27, 2025
Best MIDI Keyboard for Beginners: Top 5 Under $150 in 2025
August 28, 2025
A 14-billion-parameter model just outperformed a 70B model at reasoning tasks. That single fact tells you everything about where open source AI models August 2025 are heading. Mistral declared “Medium is the new Large,” Microsoft’s Phi-4 crushed models five times its size, and Falcon H1 cracked open 256K context windows with a hybrid architecture nobody saw coming. Here is what happened in one of the most consequential months for open source AI.
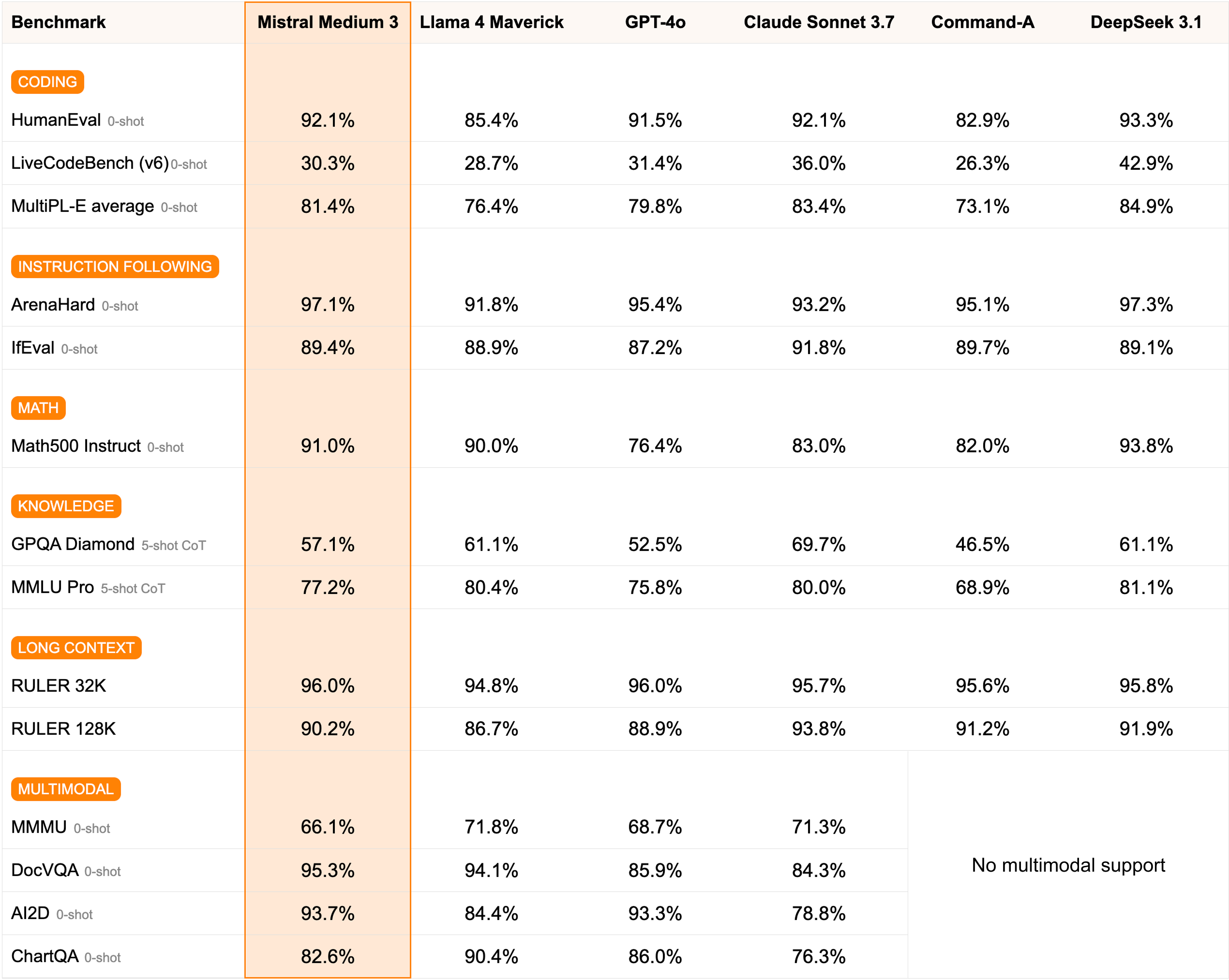
Mistral Medium 3.1: Proving “Medium Is the New Large”
On August 12, 2025, Mistral AI released Medium 3.1, a frontier-class multimodal model featuring a 128K token context window and early-fusion multimodal architecture. It scored 21 on the Artificial Analysis Intelligence Index, placing it above average among non-reasoning models. But the real story is about economics.
At $0.40 per million input tokens and $2.00 per million output tokens, Mistral Medium 3.1 delivers approximately 90% of Claude Sonnet 3.7’s performance at a fraction of the cost. According to Mistral AI’s official announcement, the model achieves an 8X cost reduction compared to competing models while simplifying enterprise deployment. The original Medium 3 launched in May 2025, and the 3.1 update brought improved response tone and overall performance refinements.
What makes this particularly interesting for enterprises is the self-hosting capability. With just four GPUs, you can deploy Medium 3.1 on any cloud environment, including fully on-premises setups. For regulated industries where data sovereignty is non-negotiable, this is a significant advantage. The model supports any cloud deployment, giving organizations full control over their AI infrastructure without sacrificing frontier-class capabilities.
The pricing structure deserves closer examination. At $0.40 per million input tokens, processing a 50,000-word document costs roughly two cents. For teams running thousands of API calls daily, the savings compound dramatically compared to proprietary alternatives. The early-fusion multimodal architecture also means you do not need separate models for text and image understanding, further simplifying production pipelines and reducing total infrastructure costs.
Microsoft Phi-4: When 14B Parameters Beat 70B
Microsoft’s Phi-4 reasoning model is arguably the most impressive story in open source AI models August 2025. Released under the MIT license, this 14B parameter model outperforms DeepSeek-R1’s distilled 70B variant at reasoning benchmarks. That is a fifth of the parameters delivering superior results.
The Phi-4 family includes three variants designed for different use cases. The base Phi-4-reasoning model handles standard reasoning tasks. Phi-4-reasoning-plus uses 1.5x more inference-time tokens for higher accuracy on complex problems. And Phi-4-mini-reasoning offers a lightweight option for resource-constrained environments. Since May 15, 2025, ONNX-optimized versions have been available for Snapdragon Copilot+ PCs, enabling local on-device reasoning without cloud dependency.
Microsoft did not stop there. In July 2025, they released Phi-4-mini-Flash-Reasoning, optimized for efficient long-context reasoning with a compact architecture. This steady expansion of the Phi-4 family throughout summer 2025 signals Microsoft’s commitment to the “small but mighty” approach. For developers building AI applications that need to run on edge devices or within strict compute budgets, the Phi-4 lineup is becoming hard to ignore.
The practical implications are significant. A 14B model that outperforms a 70B model means you need roughly one-fifth of the GPU memory and compute. For startups and smaller teams, this translates to running frontier-quality reasoning on a single consumer GPU rather than requiring expensive multi-GPU setups. The MIT license removes commercial use restrictions entirely, making Phi-4 viable for production applications without licensing concerns. Combined with the ONNX optimizations for Snapdragon hardware, Microsoft has created a complete ecosystem from cloud to edge for efficient reasoning workloads.
Falcon H1: Hybrid Architecture Opens New Frontiers
The Technology Innovation Institute (TII) from the UAE introduced Falcon H1 with a hybrid Transformer-Mamba architecture that combines the attention mechanism of Transformers with the efficiency of State Space Models (SSM). The result: 256K context windows with inference speeds that pure Transformer models struggle to match at this scale.
The model family spans six sizes from 0.5B to 34B parameters, each available in both base and instruction-tuned variants. Multilingual support covers both high-resource and low-resource languages, making Falcon H1 particularly attractive for global deployments. The entire Falcon series has surpassed 55 million total downloads, demonstrating strong community adoption.

The standout feature is integration with NVIDIA NIM microservices, enabling instant deployment in regulated and latency-sensitive environments. TII has positioned Falcon H1 specifically for sovereign AI deployment, targeting government agencies and financial institutions where data must remain within national borders. This is not just a research model. It is built for production.
The hybrid Transformer-Mamba architecture itself represents a significant technical advancement. Traditional Transformers scale quadratically with sequence length due to their attention mechanism, making very long contexts computationally expensive. State Space Models like Mamba scale linearly but have historically struggled with certain recall tasks. By combining both approaches, Falcon H1 gets the best of both worlds: efficient processing of long sequences with strong recall and reasoning capabilities. The six model sizes from 0.5B to 34B also mean teams can start small and scale up within the same architecture family without changing their deployment pipeline.
Hot Chips 2025: The Hardware Race Behind Open Source AI Models
From August 24 to 26 at Stanford University, Hot Chips 2025 showcased the silicon powering these AI advances. NVIDIA presented its Blackwell architecture alongside NVLink and Spectrum-X inference acceleration. AMD unveiled CDNA 4 and the MI350, while Google introduced its next-generation Ironwood TPU. The conference theme centered on the trillion-dollar data center computing market purpose-built for “AI factories.”
Noam Shazeer’s keynote on predictions for the next phase of AI drew significant attention. Qualcomm’s presentation of the Oryon CPU core for Snapdragon X AI PCs connects directly to the Phi-4 story. When you have optimized reasoning models running locally on consumer hardware with dedicated AI silicon, the gap between cloud AI and local AI narrows considerably. The hardware ecosystem is catching up to the software ambitions of open source AI.
The conference underscored a critical truth: the trillion-dollar data center computing market is being rebuilt around AI workloads. NVIDIA’s Blackwell architecture and NVLink interconnect are designed specifically for the massive parallel compute that large language models demand. AMD’s CDNA 4 and MI350 aim to capture a larger share of this market with competitive price-performance ratios. Meanwhile, Google’s Ironwood TPU signals continued investment in custom silicon designed from the ground up for AI training and inference. For open source model developers, more competitive hardware means lower barriers to training and deploying ambitious models.
The Macro Shift: China’s Open Source AI Surge
Beyond individual model releases, a broader shift defined summer 2025. According to industry analysis, total model downloads on Hugging Face shifted from US-dominant to China-dominant during this period. Qwen overtook Llama as the most downloaded and most fine-tuned base model. Between 1,000 and 2,000 new models were being uploaded to Hugging Face daily by late 2025, with five frontier-class open source models released under permissive licenses throughout the year.
A Red Hat Developer analysis noted that 2025 marked a genuine turning point for open source AI, with DeepSeek and Qwen becoming household names in the developer community. The trend toward smaller, more efficient models was not limited to Western labs. Chinese open source models gained significant market share during summer 2025, and on-premises LLM solutions controlled over half the market. Organizations are clearly prioritizing reduced cloud API dependency and greater control over their AI stack.
Practical Takeaways: Choosing the Right Open Source AI Model
With so many strong releases in open source AI models August 2025, here is a practical breakdown by use case. For cost-efficient multimodal workloads, Mistral Medium 3.1 offers near-frontier performance at a fraction of the typical price point. It is the obvious choice when you need vision and text capabilities without breaking your compute budget.
For reasoning-heavy applications, the Phi-4 family delivers outsized performance relative to its parameter count. If you need to run inference on local devices, Phi-4-mini-reasoning combined with ONNX optimization for Snapdragon hardware is a realistic production path today. For long-context processing and multilingual deployments, Falcon H1’s 256K context window and hybrid architecture provide unique advantages. The NVIDIA NIM integration makes enterprise deployment straightforward.
One factor that often gets overlooked is licensing. Phi-4 is MIT licensed, meaning zero restrictions on commercial use. Mistral Medium 3.1 is available through their commercial API with competitive pricing. Falcon H1 is fully open source on Hugging Face. Compare this to the proprietary alternatives where you are locked into a vendor’s API pricing and terms of service. The open source ecosystem in August 2025 gives you not just competitive performance, but genuine ownership and control over your AI infrastructure. For organizations building long-term AI strategies, this flexibility is invaluable.
The overarching narrative from August 2025 is unmistakable: efficiency over scale. A 14B model beating a 70B model. Medium replacing Large. Hybrid architectures surpassing pure Transformers. The open source AI ecosystem is maturing rapidly, and whether you are an enterprise evaluating deployment options or an individual developer building applications, ignoring these models is no longer an option.
Looking to implement open source AI models or build automation pipelines? Sean Kim can help you navigate the options.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}