
Mac Studio 2025 Music Production Review: M4 Max vs M3 Ultra DAW Benchmarks After 11 Months
February 23, 2026
Best Free DAW 2026: Cakewalk Sonar vs GarageBand vs Ardour 9 — The Definitive Comparison
February 24, 2026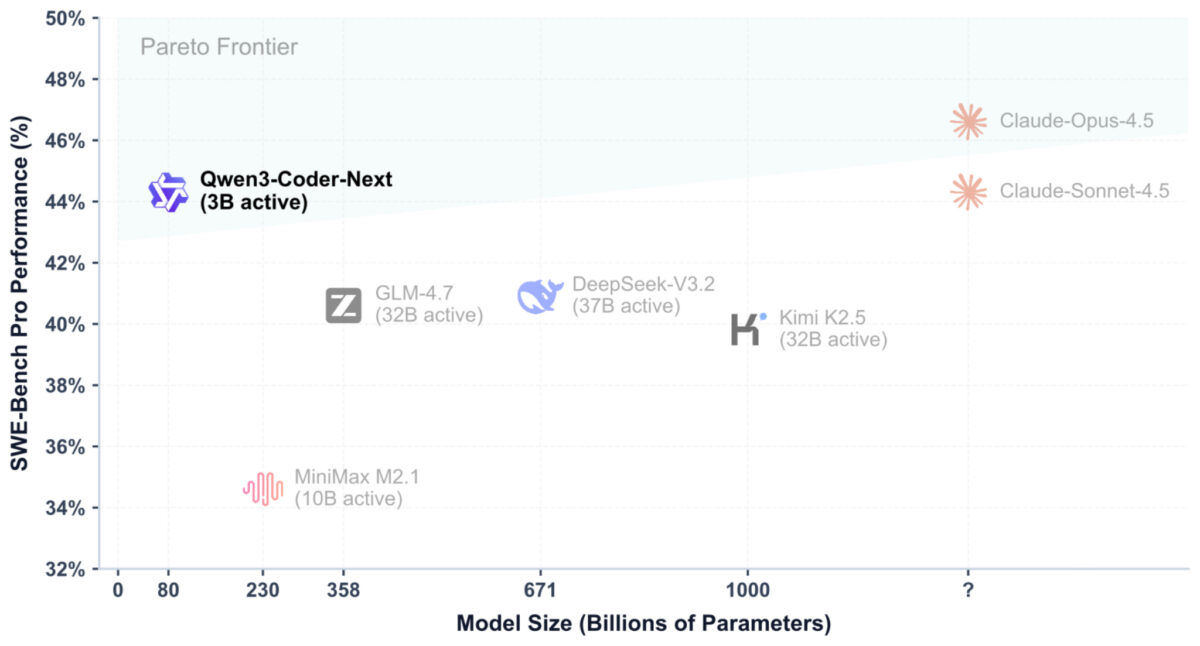
Open source AI February 2026 delivered what might be the most explosive month in the history of open-weight models. In just 28 days, we witnessed a complete reshuffling of the leaderboard — with at least 10 models arriving that would have been considered frontier-class a year ago. From Alibaba’s Qwen 3.5 redefining efficiency to z.AI’s GLM-5 debuting at the very top of the rankings, February proved that the open-source community isn’t just catching up with proprietary labs — it’s setting the pace.
Let’s break down every major release, the architectural trends driving them, and what it all means for developers and businesses choosing their AI stack in 2026.
GLM-5: The New #1 in Open Source AI February 2026
On February 12, z.AI dropped GLM-5 — and it landed at the top. With a Quality Index score of 49.64, GLM-5 debuted as the highest-ranked open-source model, comparable in capability to GPT-5.2 and Claude Opus 4.6. That’s not a typo: an open-weight model is now trading blows with the best proprietary systems on the planet.
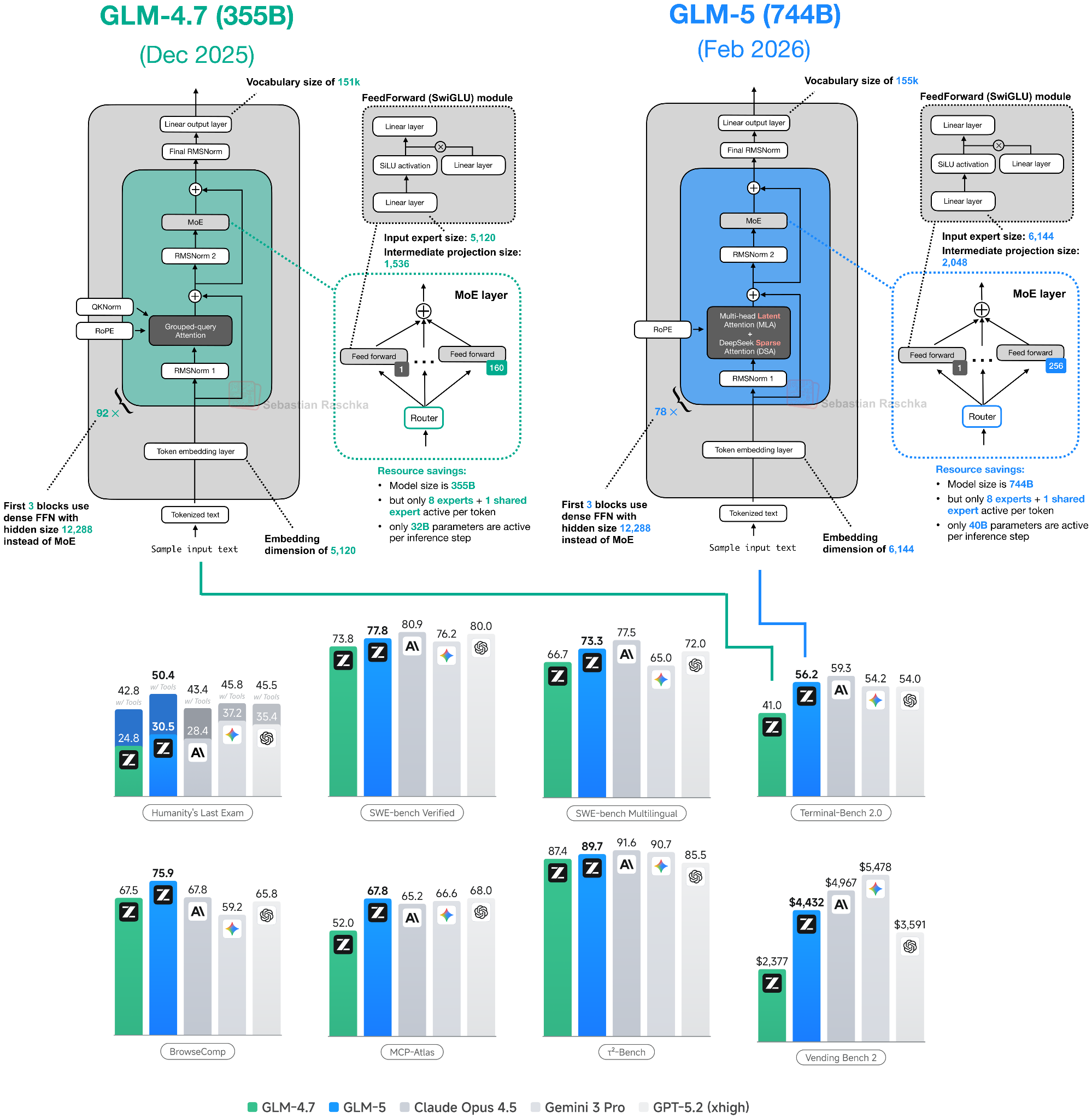
Under the hood, GLM-5 is a 744B-parameter Mixture of Experts (MoE) model with 40B active parameters per forward pass, spread across 256 expert modules. It leverages both Multi-Head Latent Attention and DeepSeek Sparse Attention — a combination that keeps inference costs manageable despite the enormous total parameter count. For teams that have been waiting for an open model they can actually trust with production workloads, GLM-5 is a watershed moment. The model’s weights are fully open, meaning enterprises can fine-tune and deploy it on their own infrastructure without licensing fees or API rate limits.
Qwen 3.5: Alibaba’s Efficiency Masterclass
Alibaba’s Qwen 3.5, released between February 15 and 17, might be the most impressive engineering achievement of the month — even if it didn’t claim the top spot. The model packs 397B total parameters with only 17B active via MoE, delivering 60% lower cost and 8x higher throughput than its predecessor.
The secret sauce is Gated DeltaNet hybrid attention, an architecture that blends linear and traditional attention mechanisms for dramatically better efficiency at long contexts. The benchmarks speak for themselves: 83.6 on LiveCodeBench v6, 91.3 on AIME26, and 88.4 on GPQA Diamond. Qwen 3.5 also supports 201 languages and ships with native multimodal capabilities — text, images, and video up to 2 hours — plus built-in agentic features for tool use and multi-step reasoning.
Notably, Alibaba unified all of its AI brands under the “Qwen” name on February 5, signaling that this family of models is now the company’s singular bet on the future of open AI.
Kimi K2.5 and MiniMax M2.5: The Trillion-Parameter Race
Moonshot AI’s Kimi K2.5 arrived on January 27 with a staggering 1 trillion parameters, built on the DeepSeek V3 architecture scaled up. It claimed the #2 spot in open-source rankings with a Quality Index of 46.73. Its benchmark numbers are eye-popping: 85% on LiveCodeBench and 96% on AIME 2025. For multimodal tasks, K2.5 is one of the most capable open models available.
Right behind at #3 is MiniMax M2.5 (February 12), a 230B model using classic Grouped Query Attention (GQA) architecture. Despite being “only” 230B, M2.5 punches well above its weight on coding benchmarks like SWE-Bench, earning a Quality Index of 41.97. Sometimes, a well-tuned smaller model beats a bloated larger one — and M2.5 proves that point convincingly.
The Speed Demons: StepFun Step 3.5 Flash and Qwen3-Coder-Next
Not every breakthrough is about raw intelligence. StepFun’s Step 3.5 Flash (February 1) is a 196B MoE model with just 11B active parameters, designed around Multi-Token Prediction. The result? 100 tokens per second on Hopper GPUs. For latency-sensitive applications — chatbots, real-time assistants, interactive coding tools — this kind of speed changes what’s possible.
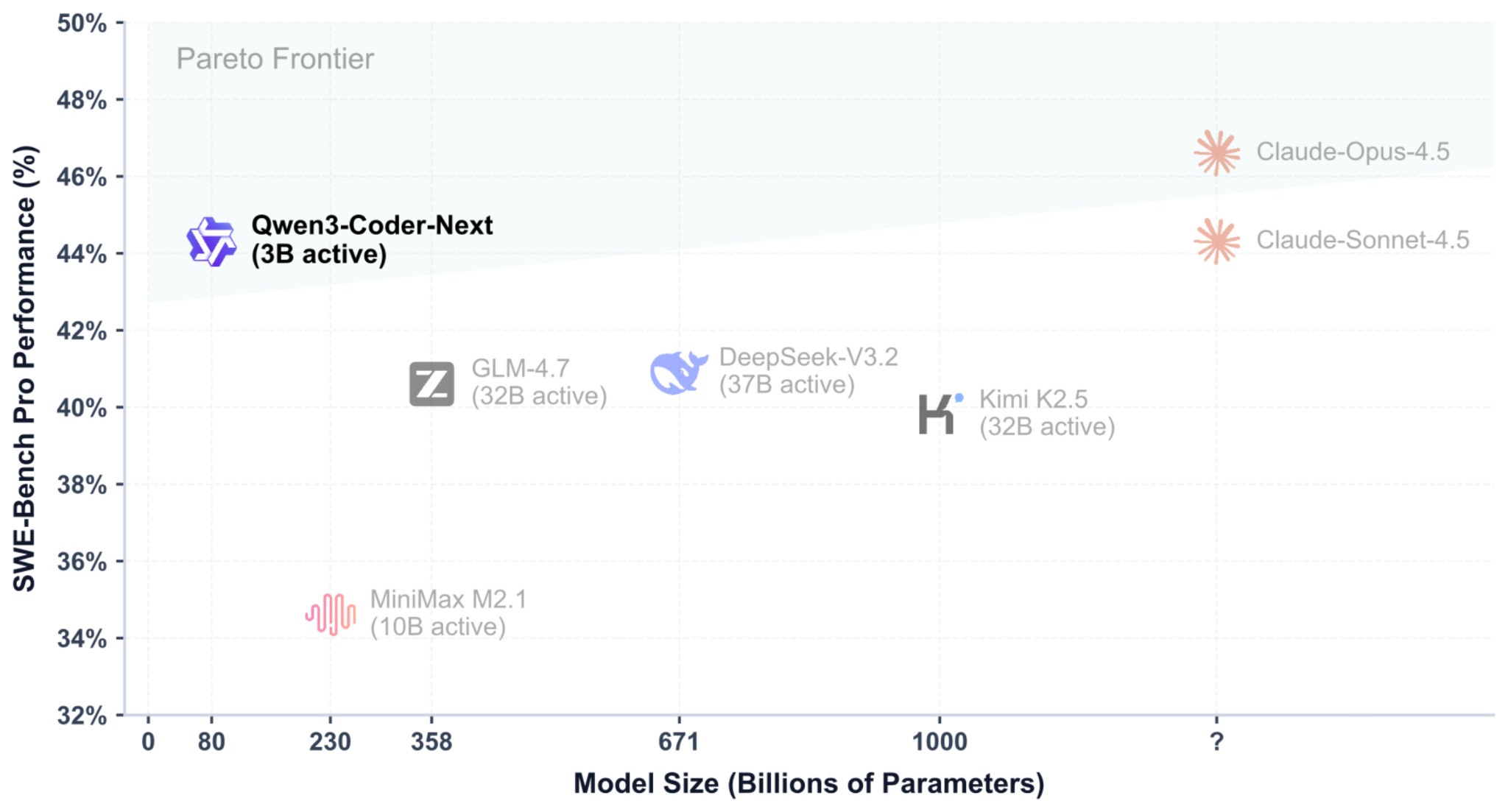
Then there’s Qwen3-Coder-Next (February 3), an 80B model with only 3B active parameters. This coding specialist consistently outperforms much larger general-purpose models and is comparable to Claude Sonnet 4.5 on SWE-Bench Pro. If you’re building AI-assisted developer tools, a 3B-active coding model that rivals the best proprietary systems is a game-changer.
The Trillion-Parameter Dark Horse: Ant Group’s Ling/Ring 2.5
Ant Group’s Ling/Ring 2.5 (February 16) also hits the 1 trillion parameter mark, but its real innovation is Lightning Attention — a custom attention mechanism that delivers 3.5x higher throughput than Kimi K2. In a month dominated by MoE architectures, Ling/Ring 2.5 shows there’s still room for attention-level innovation to drive massive efficiency gains.
Small Models, Big Surprises
February wasn’t just about massive models. Cohere’s Tiny Aya (February 17) is a 3.35B-parameter multilingual specialist that outperforms both Qwen3 4B and Gemma 3 4B on multilingual benchmarks. For organizations deploying AI in non-English markets, Tiny Aya offers remarkable capability per parameter.
Nanbeige 4.1 3B (February 13) takes a similar approach — a compact model that outperforms year-old models twice its size. And Arcee AI’s Trinity Large (January 27) offers 400B total parameters with 13B active, using an innovative alternating local/global attention pattern within its MoE architecture.
Mistral’s Voice and Vision Play
Mistral didn’t release a new flagship LLM in February, but it made two moves worth noting. Voxtral Mini Transcribe V2 and Voxtral Realtime bring open-source speech-to-text to a new level: 4B parameters, 200ms latency, 13 languages, and small enough to run on a phone. Meanwhile, Mistral OCR 3 offers document understanding at just $2 per 1,000 pages. These aren’t headline-grabbing trillion-parameter models, but they fill critical gaps in the open-source AI toolkit. For businesses processing documents or building voice interfaces, Mistral’s February releases could be more immediately useful than any of the flagship LLMs.
Architecture Trends Defining Open Source AI in February 2026
Four architectural patterns dominated this month’s releases:
- MoE Everywhere: Nearly every major release uses Mixture of Experts. The active-to-total parameter ratio keeps shrinking — Qwen3-Coder-Next activates just 3.75% of its parameters per pass.
- Gated DeltaNet Hybrid Attention: Qwen 3.5’s architecture is already being cited as a reference design for balancing quality and efficiency.
- Multi-Head Latent Attention: GLM-5’s combination with DeepSeek Sparse Attention shows how attention innovation can scale MoE models beyond 700B parameters.
- Efficiency Over Raw Size: The race isn’t about who has the most parameters anymore — it’s about who gets the most intelligence per active parameter, per dollar, per watt.
What This Means for Your AI Strategy
February 2026 made one thing clear: open-source AI models have reached parity with the best proprietary systems across coding, math, multilingual, and multimodal tasks. The cost advantages are enormous — Qwen 3.5’s 60% cost reduction and 8x throughput gains mean that self-hosted open models can now undercut API pricing from OpenAI and Anthropic by significant margins.
For developers, the practical takeaway is straightforward. If you need a general-purpose powerhouse, GLM-5 or Kimi K2.5 are the ones to evaluate. If efficiency and cost matter most, Qwen 3.5 is the clear winner. For coding tasks, Qwen3-Coder-Next delivers frontier performance at a fraction of the compute. And for edge deployment or multilingual needs, Cohere Tiny Aya and Mistral’s Voxtral family are hard to beat.
The open-source AI landscape isn’t just evolving — it’s accelerating. And February 2026 will likely be remembered as the month it crossed the point of no return. As Sebastian Raschka noted, we’re witnessing a true spring for open-weight models.
Navigating the rapidly shifting open-source AI landscape? Whether you’re evaluating models for production deployment or building an AI strategy from scratch, I can help you make the right choice.



{kind=link}
{kind=link}
{kind=link}