
Producer New Year Resolutions: 10 Ways to Level Up in 2026
December 29, 2025
Best Plugins of 2025: Editor’s Choice Awards for VSTs and Effects
December 31, 2025
What if a 500-billion-parameter model could match frontier performance while only activating 50 billion parameters at inference time? That is not a hypothetical — it is exactly what NVIDIA Nemotron 3 delivers. Announced on December 15, 2025, this three-model family represents NVIDIA’s boldest move into the open-source AI arena, and it could not have come at a more pivotal moment. With the entire industry racing toward agentic AI systems, NVIDIA just open-sourced the building blocks.
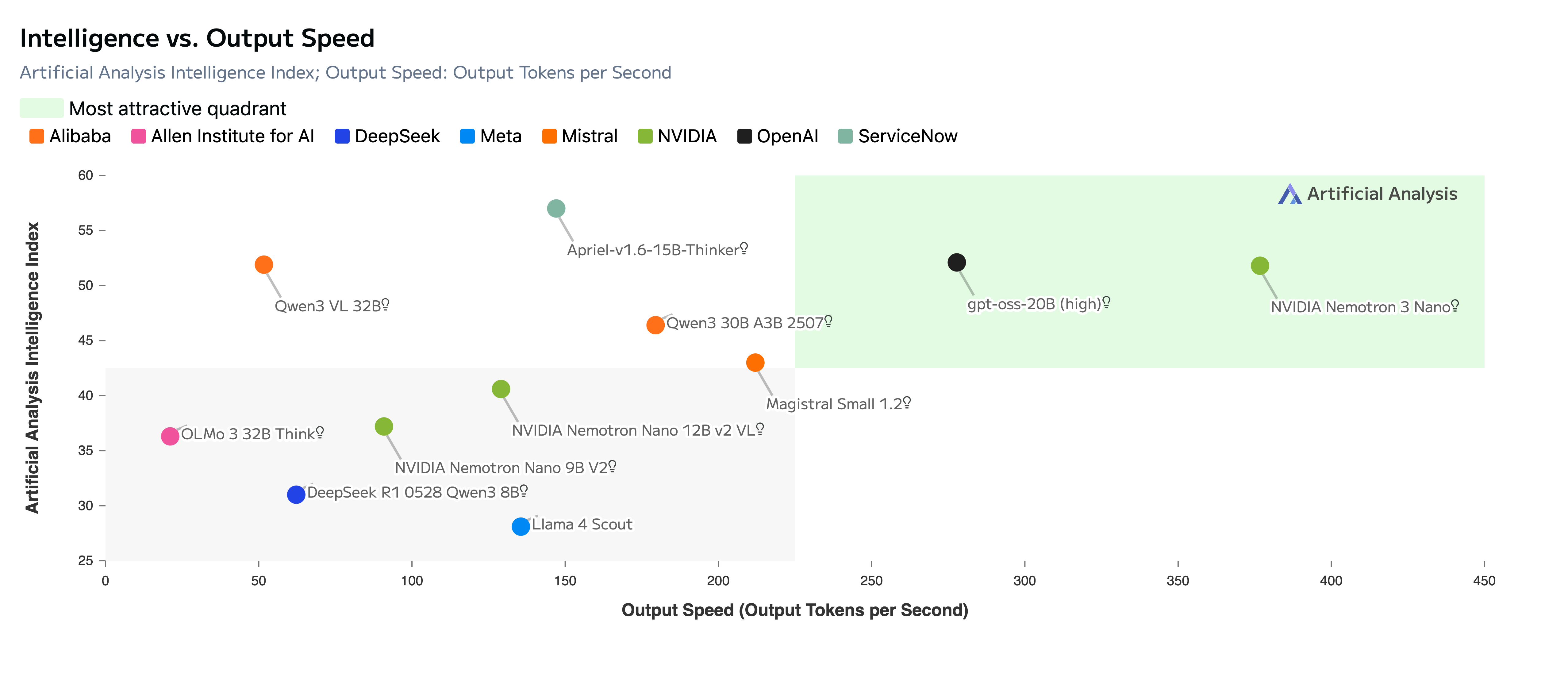
The NVIDIA Nemotron 3 Family: Three Models, One Vision
“Open innovation is the foundation of AI progress,” declared Jensen Huang at the announcement. And NVIDIA backed those words with action — releasing not just model weights, but 3 trillion tokens of pretraining data and complete training recipes. Here is what each model brings to the table.
Nano (30B total parameters / 3B active) is the immediately available workhorse. Designed for everything from edge deployment to cloud-scale inference, Nano delivers 4x higher throughput than its predecessor Nemotron 2 Nano while consuming 60% fewer reasoning tokens. According to the technical paper (arXiv:2512.20856), it uses 23 Mamba-2/MoE layers paired with 6 Attention layers. Each MoE layer contains 128 experts plus 1 shared expert, with only 6 experts activated per token. The result? A model that punches far above its active parameter weight class.
Super (~100B parameters / 10B active) targets complex agentic workflows and multi-agent orchestration. It adds Multi-Token Prediction layers for more sophisticated reasoning capabilities and is scheduled for release in the first half of 2026.
Ultra (~500B parameters / 50B active) is the flagship — built for the most demanding enterprise reasoning scenarios. Also featuring Multi-Token Prediction, Ultra will join the family alongside Super in H1 2026.
Hybrid Mamba-Transformer MoE: The Architecture Behind NVIDIA Nemotron 3’s Efficiency
The secret sauce behind Nemotron 3’s remarkable efficiency is its hybrid Mamba-2 + Transformer Mixture of Experts architecture. Traditional Transformer-based models suffer from quadratic computational scaling as sequence length grows. Mamba-2’s state space model (SSM) layers solve this with linear complexity, making long-context processing dramatically more efficient.
Layer the MoE structure on top of that, and you get a model that activates only roughly 10% of its total parameters at any given time while maintaining full-model-quality outputs. This is how Nano achieves its seemingly impossible ratio — 30B total parameters, but only 3B doing the actual work on each token.
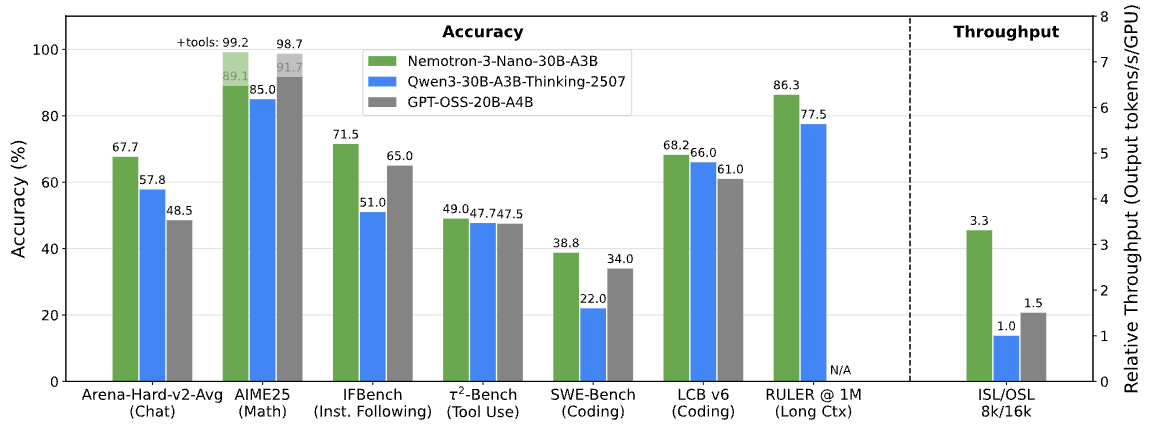
The NVIDIA technical blog details the LatentMoE design that minimizes routing overhead. The benchmark numbers speak for themselves: 3.3x higher throughput than Qwen3-30B-A3B and 2.2x higher than GPT-OSS-20B. These are not marginal improvements — they represent a generational leap in inference efficiency.
Perhaps the most impressive spec is the 1-million-token context window. On the RULER benchmark, Nemotron 3 Nano outperforms both GPT-OSS-20B and Qwen3-30B-A3B across all tested context lengths. For practical applications — analyzing entire codebases, processing lengthy legal documents, maintaining coherent multi-turn agent conversations — this is a game-changer.
NVFP4 and Blackwell: The Hardware-Software Integration Play
NVIDIA did not just release a model — they released an ecosystem. Nemotron 3 introduces NVFP4, a 4-bit floating-point training format purpose-built for the Blackwell GPU architecture. Unlike conventional FP8 or INT8 post-training quantization approaches, NVFP4 operates at 4-bit precision from the training phase itself, dramatically reducing both memory footprint and computational cost without the quality degradation typically associated with aggressive quantization.
To understand why this matters, consider the economics. Running a 30B-parameter model at FP16 precision requires roughly 60GB of GPU memory just for the weights. NVFP4 cuts that to approximately 15GB — meaning Nano can comfortably run on a single consumer-grade GPU for inference, or multiple instances can share a single datacenter GPU for production workloads. When you multiply this efficiency across the thousands of model instances needed for enterprise-scale agentic AI deployments, the cost savings become enormous.
This is vertical integration that only NVIDIA can pull off. GPU hardware (Blackwell), quantization format (NVFP4), model architecture (Nemotron 3), and training framework (NeMo) — all optimized within a single ecosystem. By open-sourcing the models while ensuring they run best on NVIDIA silicon, the company has executed what might be the smartest business strategy in AI for 2025. You can use the models anywhere, but you will want NVIDIA hardware to get the most out of them. It is the razor-and-blade model reimagined for the AI era — give away the razor (open-source models), sell the blades (Blackwell GPUs).
Built for the Agentic AI Era: Why Nemotron 3 Matters Now
According to SiliconANGLE’s analysis, the competitive axis in AI is shifting from “bigger models” to “better orchestration.” Nemotron 3 is designed precisely for this new paradigm. Rather than optimizing for single-model peak reasoning performance, it targets system-level multi-agent efficiency — how well can multiple instances of these models work together as coordinated agents?
The enterprise adoption speaks volumes. Accenture, CrowdStrike, Oracle, Palantir, Perplexity, ServiceNow, Siemens, and Zoom have all signed on as early adopters. Perplexity’s CEO specifically highlighted integrating Nemotron 3 into their agent router — using it as the brain that decides which specialized agent handles each user query.
NVIDIA also released two critical companion libraries: NeMo Gym and NeMo RL. These enable developers to perform multi-environment reinforcement learning-based post-training on their own data. Think of NeMo Gym as a training ground where you can create custom environments that simulate your specific use cases — customer support conversations, code review workflows, document analysis pipelines — and then use NeMo RL to fine-tune the model’s behavior through reinforcement learning rather than traditional supervised fine-tuning.
One particularly compelling feature is granular reasoning budget control at inference time — essentially letting agents decide “how hard to think” based on the complexity of each task. A simple factual lookup might use minimal reasoning tokens, while a complex multi-step analysis gets the full reasoning chain. For production AI systems where every token costs money, this kind of dynamic control is invaluable. It means you can deploy a single model that automatically scales its computational effort to match each request’s complexity, rather than paying for maximum reasoning on every query.
The Open-Source AI Landscape: How Nemotron 3 Stacks Up Against Llama, Mistral, and Qwen
Nemotron 3 enters a crowded field. Meta’s Llama, Mistral, and Alibaba’s Qwen have all established strong positions in the open model space. But NVIDIA’s approach differs in several important ways.
- Full transparency: Model weights + 3 trillion training tokens + complete training recipes — all open. Most competitors release weights only.
- NVIDIA Open Model License: Commercially permissive with safeguard clauses, striking a balance between openness and responsibility.
- Hardware optimization: Deep integration with Blackwell GPUs via NVFP4 for maximum efficiency — a unique advantage no pure-software company can match.
- Agent-first design: Optimized as components for multi-agent systems rather than standalone chatbots. The architecture choices (aggressive MoE sparsity, massive context window, reasoning budget control) all serve this purpose.
The licensing approach also deserves attention. The NVIDIA Open Model License is commercially permissive — you can build products and services on top of Nemotron 3 without restrictive revenue-sharing clauses — but it includes responsible AI safeguard provisions. This positions it as a pragmatic middle ground between fully permissive licenses like Apache 2.0 and more restrictive terms that some competitors impose. For enterprise adopters who need legal clarity, this is a significant advantage.
The comprehensive arXiv paper (2512.20856), published on December 25, 2025, provides complete architecture details, training methodology, and benchmark results. It marks a clear inflection point: the competition in open AI is no longer about who has the most parameters, but who builds the most efficient and capable systems.
Closing Out 2025: The Questions NVIDIA Nemotron 3 Raises for 2026
Nemotron 3 Nano is available today, with Super and Ultra arriving in the first half of 2026. Given that Nano alone already outperforms comparable models in throughput and efficiency, the complete family could significantly reshape the open-source AI landscape once fully deployed.
What makes Nemotron 3 genuinely significant is not that it is “another good model” — it is that NVIDIA designed it as a building block for better systems. The three-tier structure (Nano, Super, Ultra) is not just about offering different price points. It is about enabling hierarchical agent architectures where lightweight Nano instances handle routine tasks, Super manages complex reasoning chains, and Ultra tackles the most demanding analytical workloads — all using the same architectural DNA and training methodology.
For developers already working with frameworks like LangChain, CrewAI, or AutoGen, Nemotron 3 slots in as a drop-in foundation model that is specifically optimized for the kind of rapid, multi-turn interactions that agentic systems demand. The 1-million-token context window means agents can maintain coherent memory across extensive task chains without losing context — a persistent pain point with models that cap out at 128K or even 200K tokens.
With agentic AI poised to be the defining theme of 2026, NVIDIA has laid the open-source foundation. The question for developers and enterprises now is not whether to pay attention to Nemotron 3, but how to integrate it into their AI architectures before their competitors do.
Three model sizes, one unified architecture, 3 trillion tokens of training data, and a complete recipe book — all open. This is how NVIDIA chose to close out 2025, and it may well define how the industry opens 2026.
Building agentic AI systems or designing pipelines with open-source models? Let’s architect the optimal solution together.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}