
SSL Native Bus Compressor 2 Review: 5 New Ratios and X Mode Redefine Glue Compression
November 21, 2025
Xbox Series X Refresh vs Next-Gen Project Helix: 5 Hardware Changes That Actually Matter
November 21, 2025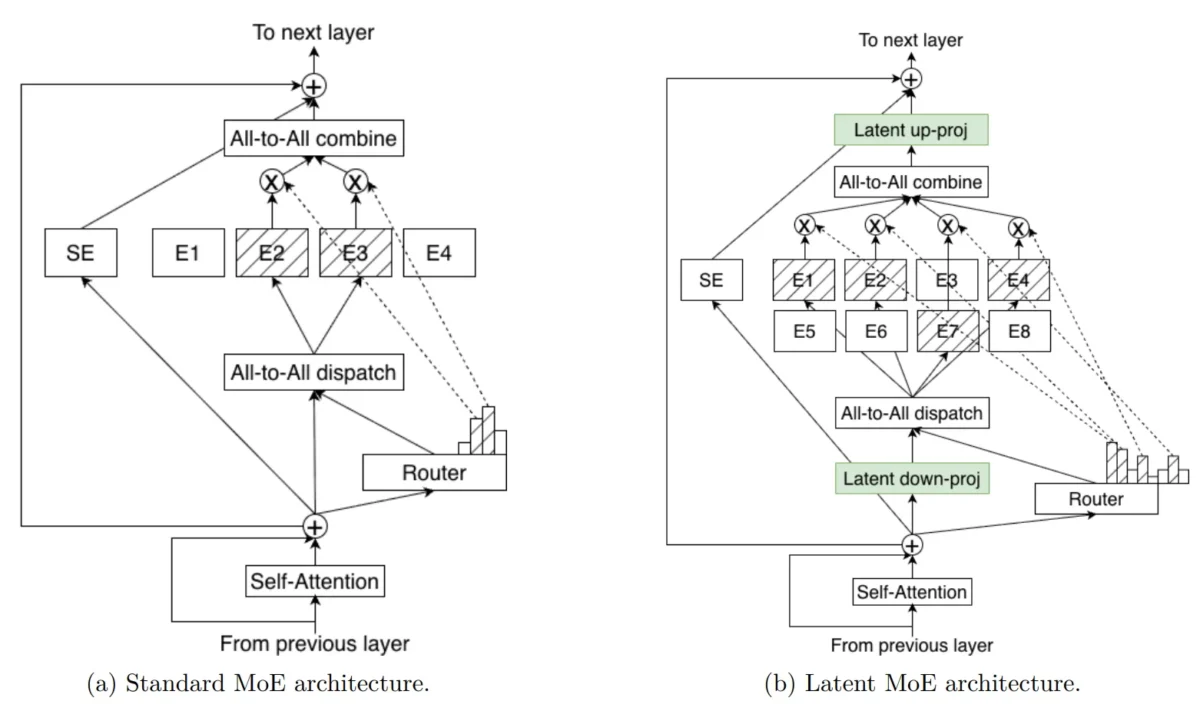
Finally — an open model family that doesn’t force you to choose between accuracy and throughput. NVIDIA Nemotron 3 just dropped with a hybrid Mamba-Transformer MoE architecture that activates only 3 billion of its 30 billion parameters per token, and the benchmarks suggest this sparse approach might redefine what’s possible for agentic AI at scale.
What Makes NVIDIA Nemotron 3 Different from Every Other Open Model
The AI model landscape has been locked in a brute-force arms race. More parameters, more compute, more cost. NVIDIA’s Nemotron 3 family takes the opposite approach: three models — Nano (30B), Super (100B), and Ultra (500B) — that activate only a fraction of their total parameters per token through a hybrid Mamba-Transformer MoE architecture. Nano fires 3B parameters, Super activates 10B, and Ultra uses 50B per token.
The result? Nemotron 3 Nano delivers 4x higher throughput than its predecessor, Nemotron 2 Nano, while simultaneously reducing reasoning-token generation by up to 60%. That’s not incremental improvement — that’s a fundamental shift in the cost-to-quality ratio for running AI agents in production.
NVIDIA Nemotron 3 Hybrid Architecture: Mamba-2, Transformer, and MoE Working Together
Most large language models are pure Transformers. They scale quadratically with sequence length, which means long contexts get expensive fast. Nemotron 3 takes a different path by interleaving three distinct layer types in a carefully designed pattern: 5 Mamba-2/MoE pairs followed by an attention block, then 3 Mamba-2/MoE pairs with another attention block, and a final stretch of 4 Mamba-2/MoE pairs.
Each component serves a specific purpose. Mamba-2 layers handle the bulk of sequence processing with linear-time complexity — critical for the native 1-million-token context window. Transformer attention layers are interspersed at strategic intervals for precise associative recall, the kind of exact-match retrieval that agents need for reliable tool calling. MoE layers scale effective model capacity while keeping inference costs predictable.
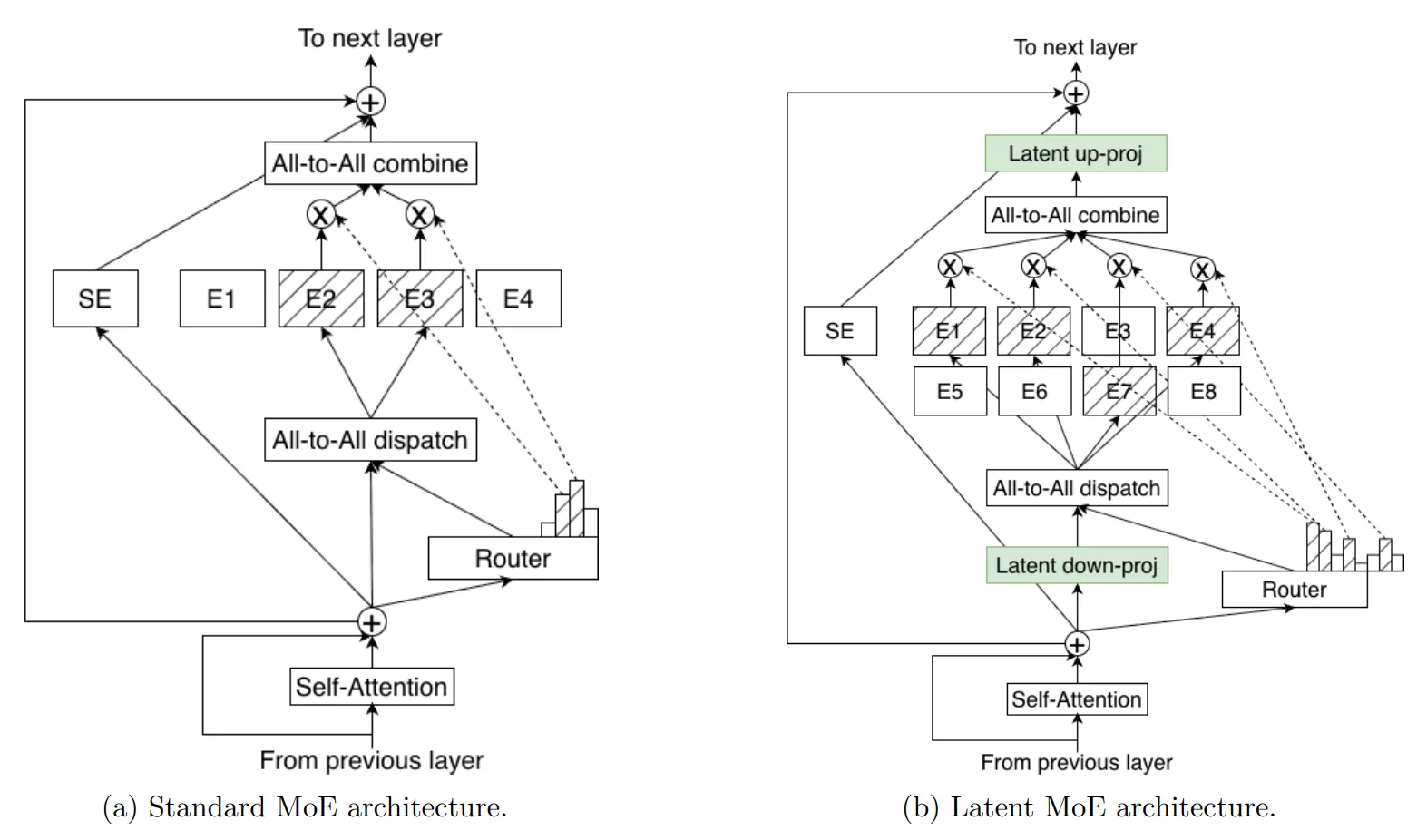
Latent MoE: 4x More Experts at the Same Cost
The standout innovation is NVIDIA’s Latent MoE technique. Before routing tokens to experts, the system compresses token embeddings into a shared latent representation. This compression-before-routing approach enables “4x as many expert specialists for the same inference cost,” according to NVIDIA’s technical blog. For multi-hop reasoning tasks — exactly what agentic AI systems need — this means more fine-grained specialization across diverse task types without the computational penalty.
Multi-Token Prediction: 3x Speedups for Structured Generation
Nemotron 3 also predicts multiple future tokens simultaneously without requiring a separate draft model. This Multi-Token Prediction (MTP) approach produces 3x wall-clock speedups for structured generation tasks — tool calls, JSON output, code generation — while improving training accuracy by approximately 2.4% through weight sharing across prediction heads.
Why does this matter for agents specifically? When an AI agent calls a function, it needs to generate structured output — a function name, parameters, closing brackets. Traditional autoregressive generation handles this token by token. MTP predicts the entire structured block in fewer forward passes, which directly translates to lower latency in agent tool-calling loops. For a system making hundreds of tool calls per workflow, the cumulative time savings are substantial.
The 1M Token Context Window: Not Just Marketing
Many models claim extended context windows but achieve them through positional encoding tricks that degrade accuracy at longer ranges. Nemotron 3’s 1-million-token context is native to its architecture — the Mamba-2 layers process long sequences with linear time complexity, meaning the computational cost grows proportionally (not quadratically) with context length. In practical terms, an agent can hold approximately 750,000 words of context simultaneously — enough to analyze a full enterprise codebase, maintain conversation history across an entire workday, or process thousands of PDF pages without retrieval-augmented generation (RAG) overhead.
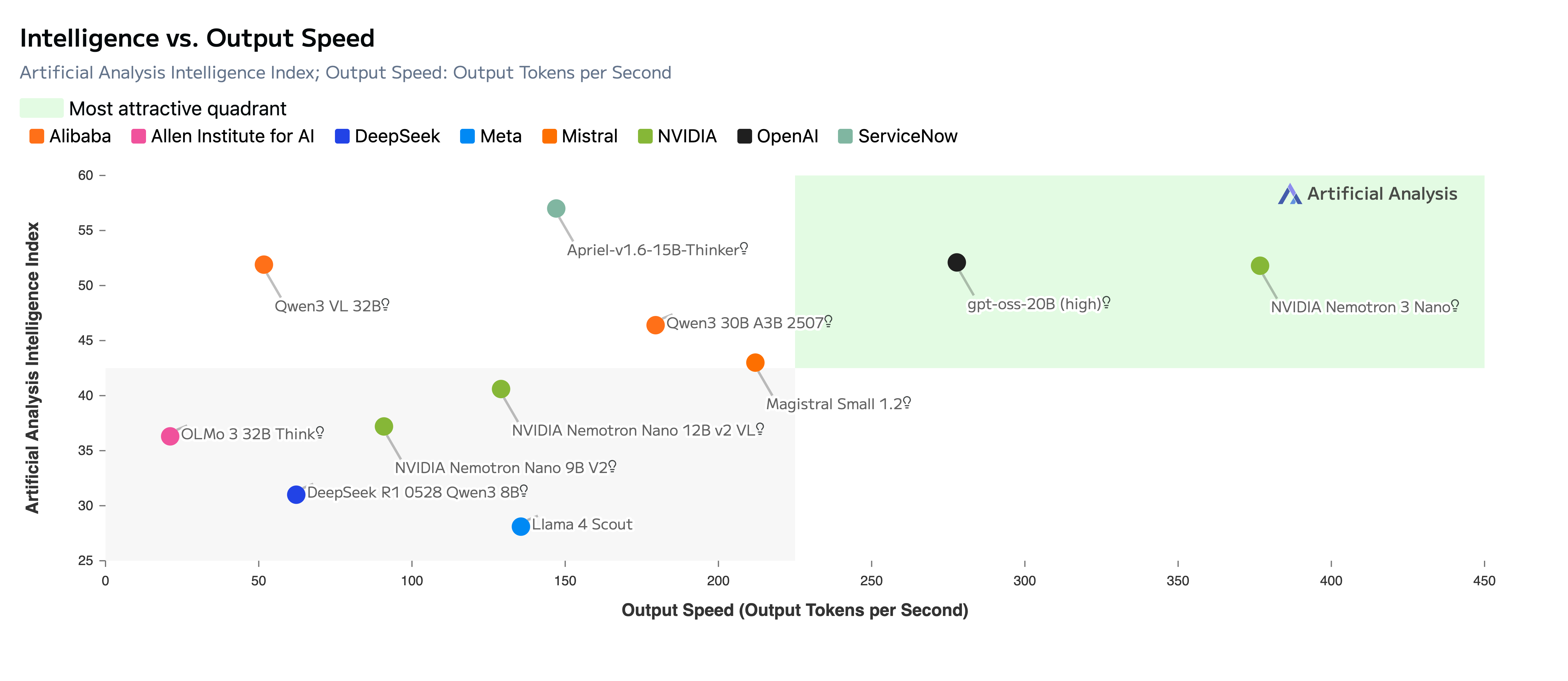
The Numbers: How NVIDIA Nemotron 3 Stacks Up Against Competing Open Models
Benchmarks tell a compelling story. Nemotron 3 Nano scores 52 on the Artificial Analysis Intelligence Index v3.0, placing it among the highest-throughput models in its class. The Super variant scores 85.6% on PinchBench — described as the best open model in its class for agentic tasks.
But the real differentiator isn’t just accuracy — it’s efficiency. Nemotron 3 Super delivers 5x higher throughput than the previous Nemotron Super, trained on 25 trillion total tokens (10 trillion unique) and refined through 1.2 million reinforcement learning environment rollouts across 21 different configurations.
NVFP4: Native 4-Bit Training Changes the Economics
The Super and Ultra variants train natively in NVIDIA’s NVFP4 (4-bit floating-point) format on Blackwell architecture. This isn’t post-quantization — the models are trained from scratch in 4-bit precision, delivering 4x improved memory and compute efficiency compared to FP8 on H100. For enterprises deploying agentic systems at scale, this means running Ultra-class (500B parameter) models on hardware that previously could barely handle 70B dense models.
The training pipeline itself is massive: a 3-trillion-token pretraining dataset, a 13-million-sample post-training corpus covering reasoning, coding, safety, and multi-step agent tasks. NVIDIA also released NeMo Gym and NeMo RL — open-source libraries for the multi-environment reinforcement learning that makes Nemotron 3 particularly effective at sustained multi-step reasoning without goal drift.
Why This Matters for Agentic AI Development
The agentic AI landscape has a critical problem: most open models either have the accuracy for complex multi-step tasks but can’t run cheaply at scale, or they’re fast and cheap but fail at the precise tool calling and long-context reasoning that agents demand. Nemotron 3’s architecture directly addresses this gap.
The 1-million-token native context window means agents can maintain full project context — entire codebases, thousands of document pages, extended conversation histories — without the accuracy degradation that plagues models using context extension hacks. Combined with the Latent MoE’s specialized expert routing, agents built on Nemotron 3 can navigate complex function libraries with higher reliability than previous open models.
Jensen Huang framed it clearly: “Open innovation is the foundation of AI progress. With Nemotron, we’re transforming advanced AI into an open platform that gives developers the transparency and efficiency they need to build agentic systems at scale.”
Deployment Options and the Enterprise Ecosystem
Nemotron 3 Nano is available immediately on Hugging Face and through inference providers including Baseten, DeepInfra, Fireworks AI, Together AI, and OpenRouter. AWS Amazon Bedrock offers serverless deployment, with Google Cloud, CoreWeave, Crusoe, Microsoft Foundry, and Nebius planned.
The early adopter list reads like a who’s who of enterprise AI: Accenture, Cadence, CrowdStrike, Cursor, Deloitte, EY, Oracle, Palantir, Perplexity, ServiceNow, Siemens, Synopsys, and Zoom. For privacy-sensitive deployments, the NVIDIA NIM microservice packaging enables fully on-premise inference.
The open-source ecosystem is also well-supported: vLLM, SGLang, TensorRT-LLM, llama.cpp, LM Studio, and Unsloth all provide compatibility. NVIDIA released complete pre-training recipes, RL alignment recipes, and data-processing pipelines alongside the model weights.
What makes this ecosystem particularly compelling is the open data commitment. NVIDIA released the full 3-trillion-token pretraining dataset, including the synthetic reasoning and coding corpora that give Nemotron 3 its edge. They also published the Nemotron Agentic Safety Dataset — 11,000 AI agent workflow traces specifically designed for evaluating emerging safety and security risks in autonomous AI systems. For enterprises concerned about agent safety auditing, this is the most comprehensive open evaluation framework currently available.
The NeMo Gym library deserves special attention. It provides 15+ reinforcement learning environments specifically designed for training agentic behaviors — from multi-step tool calling to code debugging to long-horizon planning tasks. Combined with NeMo RL, developers can fine-tune Nemotron 3 models on custom agent workflows and deploy them through the same NIM microservice infrastructure used by the base models.
The Bigger Picture: NVIDIA’s Open Model Strategy
Nemotron 3 isn’t just a model release — it’s a strategic positioning. By open-sourcing state-of-the-art reasoning models optimized specifically for NVIDIA hardware (Blackwell’s NVFP4), NVIDIA creates a gravitational pull toward its GPU ecosystem. The 11,000-trace Nemotron Agentic Safety Dataset further establishes NVIDIA’s framework as the reference standard for evaluating agent system safety.
For developers and enterprises building agentic AI, the equation is straightforward: Nemotron 3 offers the most efficient open path to production-grade multi-agent systems, with the architectural innovation (Mamba-Transformer MoE hybrid) to back up that claim. The question isn’t whether this architecture matters — it’s how quickly the rest of the industry adopts it.
Consider the competitive landscape. Meta’s Llama 3.1 405B is dense — all parameters active, all the time — making it expensive for sustained agent workloads. Mistral’s Mixtral uses MoE but lacks the Mamba layers for efficient long-context processing. Qwen3’s 122B model is competitive on benchmarks but doesn’t offer the same open training data and RL environment ecosystem. Nemotron 3 occupies a unique position: hybrid architecture, full open-source toolchain, native hardware optimization, and an enterprise adoption wave that’s already in motion.
The timing is also significant. As Black Friday approaches and enterprises finalize their 2026 AI infrastructure budgets, Nemotron 3 arrives as the strongest argument for building on NVIDIA’s stack rather than proprietary alternatives. With the open-weight license enabling full customization and the NIM microservice packaging simplifying deployment, the barriers to adoption are remarkably low for a model family of this sophistication.
Interested in building AI-powered automation pipelines or integrating agentic AI into your workflow? Sean Kim specializes in AI systems architecture and automation consulting.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}