
Best Gaming Laptops October 2025: 7 Picks for the Holiday Season
October 10, 2025
Synthwave Production Techniques: The Complete Guide to Crafting Retro Sounds with Modern Tools
October 13, 2025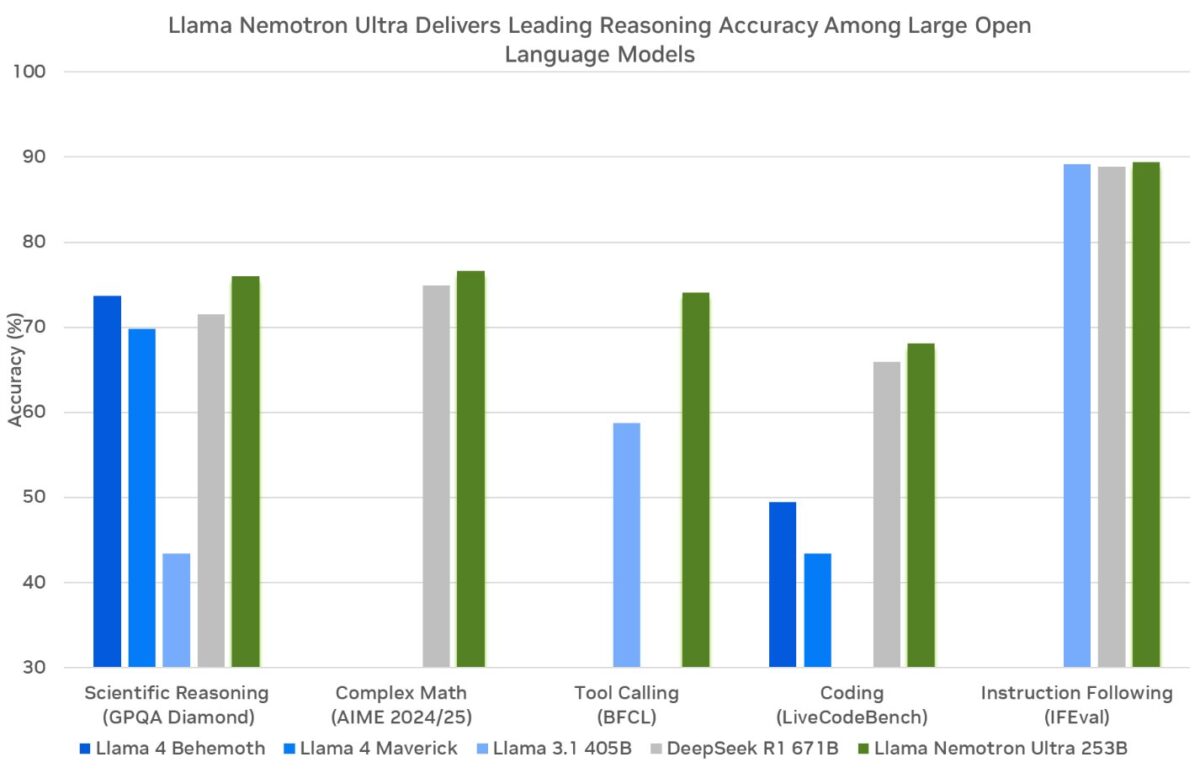
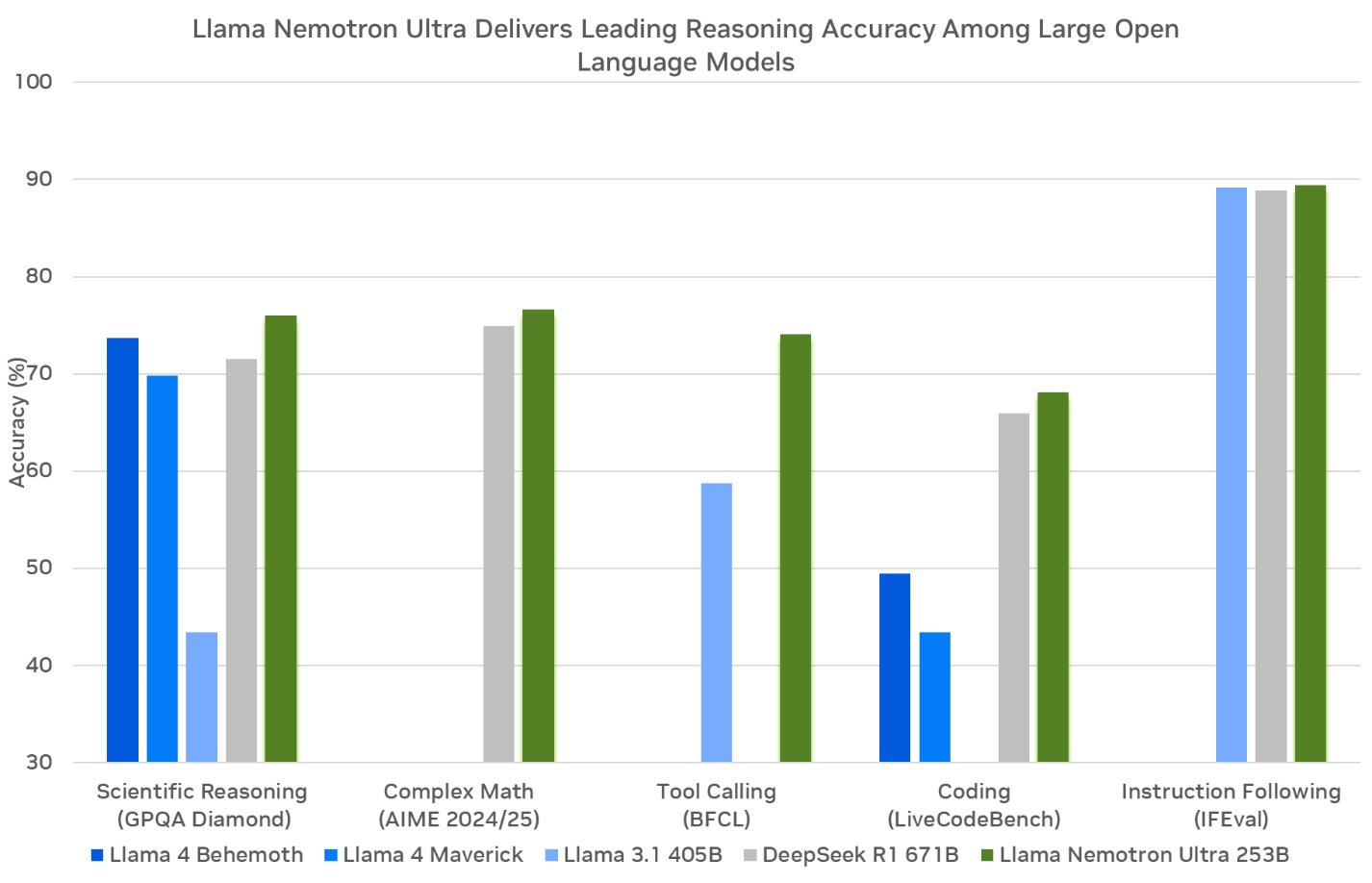
What if you could flip a switch to turn reasoning on and off in an open-source AI model? That is no longer hypothetical. NVIDIA Llama Nemotron just dropped three models that took MATH500 scores from 36.6% to 95.4%, delivered 4x the throughput of DeepSeek R1, and beat OpenAI’s o3 on real-world coding benchmarks. The agentic AI landscape just shifted dramatically.
” alt=”NVIDIA Llama Nemotron benchmark performance comparison”/>
Meet the NVIDIA Llama Nemotron Family: Ultra, Super, and Nano
NVIDIA’s new Llama Nemotron lineup consists of three models purpose-built for different deployment scales. Ultra (253B parameters) is the flagship, distilled from Llama 3.1 405B and deployable on a single 8xH100 node using FP8 precision. Super (49B) is distilled from Llama 3.1 70B, hitting the sweet spot between performance and efficiency. Nano (8B) derives from Llama 3.1 8B, designed for edge deployment and resource-constrained environments.
The distillation approach is worth unpacking. Rather than training from scratch, NVIDIA compressed the knowledge from larger Llama 3.1 models into smaller, more efficient architectures. Ultra retains the reasoning depth of the 405B model while cutting parameters by 37%. Super achieves 70B-class intelligence at 49B parameters. Nano squeezes surprisingly strong reasoning into a model small enough to run on a single GPU — making it viable for on-device inference in laptops, mobile workstations, and IoT edge devices where latency-sensitive agent tasks need to execute without round-tripping to a cloud endpoint.
The training pipeline is where things get particularly interesting. NVIDIA used 60 billion tokens of synthetic data for supervised fine-tuning, followed by REINFORCE reinforcement learning combined with the HelpSteer2 dataset. The synthetic data strategy is deliberate: by generating precisely the type of multi-step reasoning examples these models needed — mathematical proofs, code debugging chains, logical deductions — NVIDIA avoided the noise and inconsistency of scraped internet text. The REINFORCE RL phase then optimized the models to prefer longer, more accurate reasoning chains when precision matters.
The Dynamic Reasoning Toggle: A First for Open-Source AI
Here is the feature that sets NVIDIA Llama Nemotron apart from everything else in the open-source space: a dynamic reasoning toggle. Through a simple system prompt instruction, you can switch reasoning mode on or off at inference time. This is the first time any open-source model has offered this capability.
Why does this matter so much? Not every task requires deep chain-of-thought reasoning. A simple classification or summarization task runs faster and cheaper with reasoning off. A complex mathematical proof or multi-step code generation task benefits enormously from reasoning on. With one model, you can handle both scenarios efficiently — no need to maintain separate model deployments for different workloads. In practical terms, an enterprise running customer support agents can keep reasoning off for routine FAQ responses, then toggle it on when a customer raises a complex technical issue that requires multi-step analysis.
The benchmark numbers tell a compelling story. Nano (8B) jumps from 36.6% to 95.4% on MATH500 when reasoning is toggled on — a 2.6x accuracy improvement from a simple prompt change. Super (49B) goes from 74.0% to 96.6% on the same benchmark and scores 9.17 on MT-Bench, placing it among the highest-rated conversational models at any scale. Ultra (253B) achieves 92.7 on Arena Hard, representing a 20%+ accuracy boost over the base model. These are not marginal gains; they represent a fundamental shift in what a single model deployment can accomplish.
Throughput That Makes DeepSeek R1 Look Slow
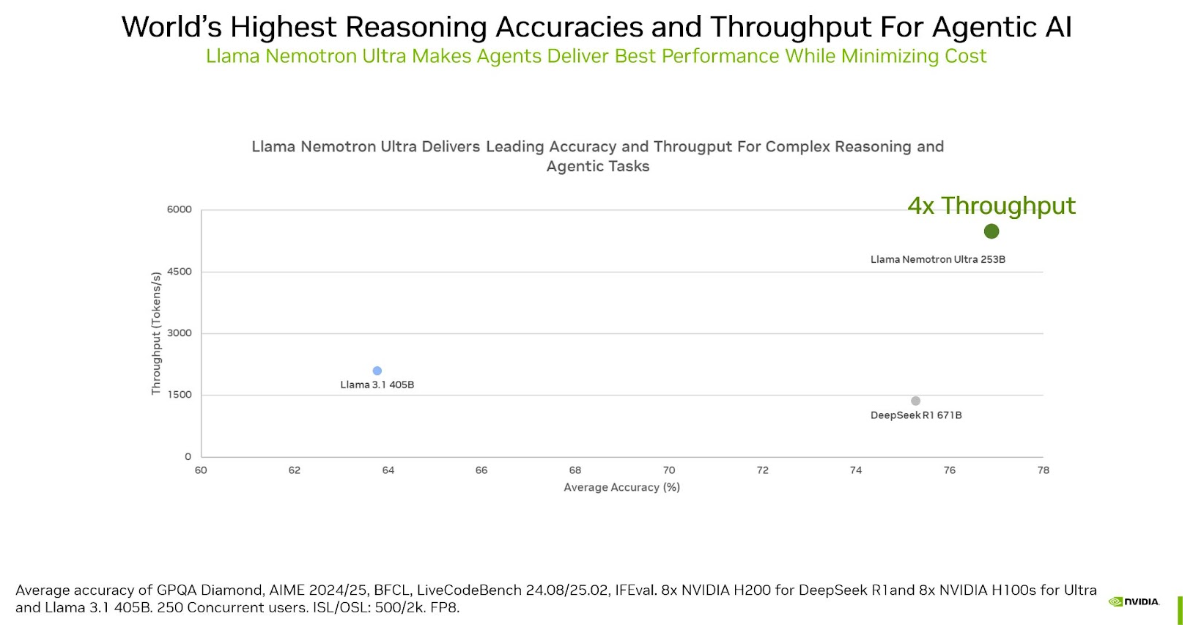
Performance benchmarks only tell half the story. In production environments, throughput — how many requests you can process per second on a given hardware setup — determines whether a model is economically viable at scale. This is where NVIDIA Llama Nemotron delivers a knockout punch to the current open-source reasoning leader.
Ultra (253B) achieves 4x the throughput of DeepSeek R1 (671B). Let that sink in: fewer than half the parameters, four times the inference speed. The efficiency gap is even starker with Super (49B), which delivers 5x throughput compared to DeepSeek R1 Llama 70B. For enterprises running AI agents that make hundreds or thousands of inference calls per task, this throughput advantage translates directly into infrastructure cost savings that can reach 75-80% compared to equivalent DeepSeek R1 deployments.
Consider a typical agentic workflow where an AI agent needs to reason through 50 sequential steps to complete a software engineering task. At 4-5x throughput, those 50 steps that might take 10 minutes on DeepSeek R1 could complete in under 2 minutes on Nemotron Super. Scale that across an engineering team running dozens of agents simultaneously, and the time and cost savings become substantial. For a mid-size company processing 10,000 agent tasks daily, the difference between 1x and 5x throughput could mean the difference between needing 50 GPU nodes and needing 10.
The architectural reason behind this efficiency advantage comes down to parameter count and optimization. DeepSeek R1 at 671B parameters requires massive memory bandwidth and multi-node setups for inference. Nemotron Ultra at 253B fits on a single 8xH100 node with FP8 quantization, eliminating the inter-node communication overhead that bottlenecks larger models. NVIDIA’s NIM microservices further optimize serving with techniques like continuous batching and speculative decoding.
” alt=”NVIDIA Llama Nemotron agentic AI workflow diagram”/>
Nemotron-CORTEXA: The Open-Source Coding Agent That Beats o3
If the reasoning benchmarks were not enough, NVIDIA’s Nemotron-CORTEXA just dethroned one of the most capable closed-source models on the benchmark that matters most for AI coding agents. On SWE-bench Verified — which measures an AI’s ability to autonomously resolve real GitHub issues — CORTEXA scored 68.2%, surpassing OpenAI’s o3 at 66%.
SWE-bench Verified is not a toy benchmark. Each test case is a real issue from popular open-source repositories like Django, Flask, and scikit-learn. The model must read the issue description, navigate the codebase, understand the existing architecture, write a correct fix, and ensure that fix passes the project’s test suite. It tests the full spectrum of software engineering skills: code comprehension, debugging, patch generation, and regression awareness. Scoring 68.2% means CORTEXA successfully resolves roughly two out of every three real-world software issues it encounters autonomously.
This result is historically significant because it marks one of the first times an open-weight model system has surpassed a leading proprietary model on a coding agent benchmark. For enterprises in regulated industries — finance, healthcare, defense — where model auditability and data sovereignty are non-negotiable, having an open-weight alternative that matches closed-source coding performance removes a major barrier to AI agent adoption. Teams can inspect the model weights, run inference entirely on-premise, and maintain full control over their intellectual property.
What makes CORTEXA particularly impressive is its cost efficiency. At just $3.28 in LLM inference costs per resolved issue, it achieves a practical cost-to-performance ratio that makes AI-assisted code review and bug fixing viable for day-to-day development workflows — not just showcase demos. The agent uses a two-stage pipeline: first localizing the bug using NV-EmbedCode (a specialized code embedding model that maps bug descriptions to faulty code), then generating diverse repair candidates and selecting the best one. This structured approach is why it outperforms brute-force reasoning approaches that rely on raw model intelligence alone.
The Expanding Nemotron Ecosystem
NVIDIA is not stopping at the core Llama Nemotron trio. The broader ecosystem is expanding rapidly with specialized variants. Mistral-Nemotron brings Nemotron optimizations to the Mistral architecture, offering an alternative foundation for teams already invested in the Mistral ecosystem. AceReasoning 14B targets the mid-range segment where teams need stronger reasoning than Nano provides but cannot justify the infrastructure for Super or Ultra. Nemotron-H experiments with hybrid architectures that blend different attention mechanisms, potentially defining the next generation of efficient model design. And Safety Guard V2 delivers 81.6% accuracy on safety benchmarks, providing a dedicated guardrail model that can screen agent outputs before they reach end users.
On the deployment side, NVIDIA has made accessibility a clear priority. All models are available as open weights on Hugging Face for teams that want full control over their inference stack. NVIDIA’s NIM microservices provide containerized API-based access for teams that prefer managed infrastructure with built-in load balancing and auto-scaling. You can test-drive the models for free on build.nvidia.com before committing to a deployment strategy. Enterprise partners including major cloud providers are already integrating these models into their managed AI platforms.
What This Means for AI Agents and Enterprise AI
The Llama Nemotron release represents a convergence of capabilities that the AI agent ecosystem has been waiting for. Dynamic reasoning toggle provides workload flexibility that no other open-source model offers. Throughput numbers that are 4-5x faster than DeepSeek R1 make production deployment economically viable for the first time at this quality level. CORTEXA’s SWE-bench results prove that open-source models can match proprietary alternatives on real-world tasks. And the range from 8B to 253B parameters means there is a model for every scale — from edge devices running local agents to data center clusters powering enterprise-wide AI platforms.
For teams building AI agents or adding reasoning capabilities to existing systems, NVIDIA Llama Nemotron is arguably the most practical choice available right now. The combination of open-source transparency, NVIDIA’s mature inference infrastructure, and a growing ecosystem of specialized models makes these models strong candidates to become the default backbone for enterprise agentic AI. Whether you are prototyping with Nano on a single GPU or deploying Ultra across a fleet of H100 nodes, the Nemotron family covers every point on the performance-cost curve. The open-source reasoning model race just got a definitive new frontrunner.
Interested in building AI agent systems or LLM-powered automation pipelines? Let’s design the optimal architecture for your use case.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}