Cursor Automations Cloud Agents: Always-On AI Triggered by GitHub PRs, Slack, and PagerDuty
March 19, 2026
Klobuchar Antitrust Accountability Act: 7 Key Reforms Sparked by the ‘Weak’ Live Nation Settlement
March 19, 2026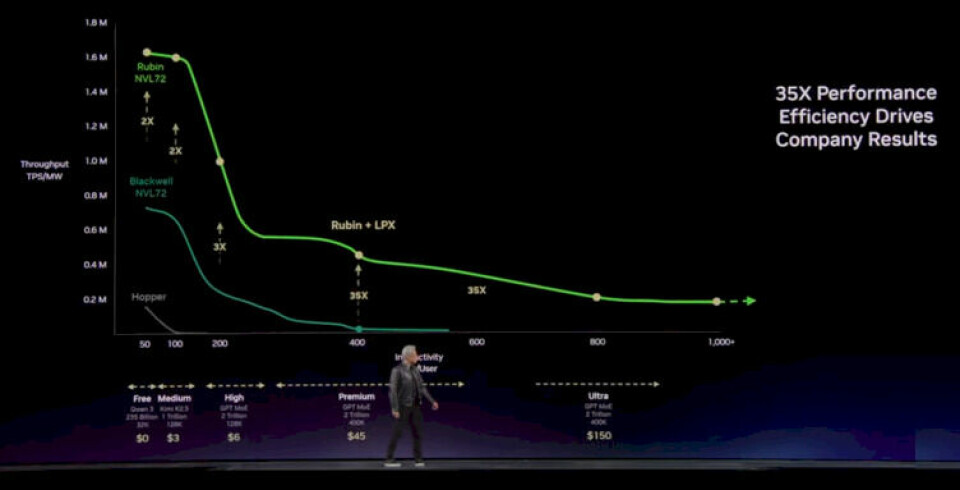
Half a gigabyte of SRAM on a single chip. No HBM. No DRAM. Just raw, on-die memory running at 150 terabytes per second. At GTC 2026, NVIDIA didn’t just announce another GPU — they revealed a fundamentally different approach to AI inference with the NVIDIA Groq 3 LPU, and the implications are staggering.
When NVIDIA dropped $20 billion to acquire Groq, the industry was split. Why would the GPU king buy an SRAM-based chip startup? After GTC 2026, the answer is crystal clear: training belongs to GPUs, inference belongs to LPUs, and NVIDIA intends to own both sides of the equation.

NVIDIA Groq 3 LPU Core Specs: Why SRAM Changes Everything
The most radical design decision in the Groq 3 LPU is the complete elimination of HBM (High Bandwidth Memory). While conventional GPUs wait for data to shuttle back and forth from external HBM stacks, the Groq 3 LPU keeps everything on-chip. Every weight, every activation, every intermediate result lives in SRAM — and that changes the latency equation entirely.
The numbers tell the story. Each NVIDIA Groq 3 LPU chip packs 500MB of SRAM with a memory bandwidth of 150 TB/s. For context, NVIDIA’s own Rubin GPU delivers HBM bandwidth in the single-digit TB/s range. That makes the Groq 3 LPU’s memory subsystem roughly an order of magnitude faster in terms of raw data access speed.
- Per-chip SRAM: 500MB — fully on-die, zero external memory dependency
- Memory bandwidth: 150 TB/s — enabling true deterministic execution
- Rack configuration: 256 LPUs per Groq LPX rack, 128GB total SRAM, 40 PB/s aggregate bandwidth
- Inference throughput: 35x more tokens generated per second compared to GPU-based inference
Why does this matter right now? Because the AI industry’s bottleneck has shifted dramatically. In 2024, the constraint was training — companies couldn’t get enough GPUs to build bigger models. In 2026, those models are already trained. The constraint is now serving them to hundreds of millions of users in real time. Every millisecond of inference latency translates directly to user experience, and ultimately, to revenue.
There’s another dimension worth understanding: deterministic execution. Traditional GPUs schedule work dynamically, meaning execution time varies from run to run. The Groq 3 LPU’s architecture is fundamentally deterministic — every operation completes in a fixed, predictable number of clock cycles. This eliminates the tail latency spikes that plague GPU-based inference deployments, where a small percentage of requests take dramatically longer than average. For production systems serving millions of users, eliminating these tail latency outliers is just as important as improving average throughput.
Groq LPX Rack System: 256 LPUs Working as One Giant Inference Engine
Individual chip performance is only part of the story. NVIDIA also unveiled the Groq LPX — a rack-scale system designed to make hundreds of LPUs operate as a single, unified inference engine.
A single Groq LPX rack houses 256 Groq 3 LPU chips. Combined, that’s 128GB of SRAM with an internal aggregate bandwidth of 40 PB/s (petabytes per second). To put 40 PB/s in perspective: you could transfer Netflix’s entire content library — roughly 15 petabytes — in under half a second. That kind of internal communication speed allows the 256 LPUs to function as if they were a single, monolithic processor.
What makes this especially significant is that the Groq LPX is fully integrated into NVIDIA’s Rubin platform. Training happens on Rubin GPU clusters, inference happens on Groq LPX racks, and the two communicate seamlessly through NVIDIA’s interconnect fabric. As The Decoder reported, this marks the first time NVIDIA has included dedicated inference hardware in its platform stack.

The Real Reason Behind the $20 Billion Acquisition
NVIDIA’s $20 billion acquisition of Groq wasn’t a technology shopping spree. It was a calculated strategic bet on where AI infrastructure is heading over the next five years.
Consider the current landscape. Through 2024 and 2025, model training was the primary revenue driver for AI chip makers. Meta, Google, and OpenAI were buying tens of thousands of GPUs to train ever-larger models. But in 2026, a fundamental shift is underway: inference workloads now account for over 60% of total AI compute demand. The models are built. Now they need to run — fast, efficiently, and at massive scale.
The problem is that GPUs aren’t optimized for inference. Their strength lies in massively parallel matrix operations — the bread and butter of training. Inference, by contrast, involves smaller batch sizes, sequential token generation, and extreme latency sensitivity. For this type of workload, the Groq 3 LPU’s deterministic execution model — where every operation completes in a predictable number of clock cycles — delivers efficiency that GPUs simply can’t match.
According to NextPlatform’s analysis, CEO Jensen Huang explicitly stated during the GTC keynote that “the agentic AI era cannot be unlocked without dedicated inference hardware.” When AI agents are making hundreds of chained API calls and performing multi-step reasoning in real time, millisecond-level latency isn’t a luxury — it’s a hard requirement.
Agentic AI and the Inference Hardware Imperative
2026 is shaping up to be the year of agentic AI. We’ve moved far beyond chatbots that answer questions. Today’s AI agents autonomously write code, analyze data, manage workflows, and make decisions — and each of those tasks requires dozens to hundreds of inference calls under the hood.
Here’s where the math gets interesting. In the chatbot era, a user could tolerate a 1-2 second response time. But when an AI agent chains 100 sequential inference calls to complete a complex task, even 1 second per call means the entire operation takes nearly two minutes. With hardware like the Groq 3 LPU delivering 35x faster token generation, that same 100-step operation could complete in under 3 seconds. The difference between a two-minute wait and a three-second response isn’t incremental — it’s the difference between a product people tolerate and a product people love.
Groq’s existing GroqCloud API had already demonstrated this potential, consistently delivering hundreds of tokens per second on LLaMA models — earning it a reputation as the fastest inference API in the developer community. With the Groq 3 LPU integrated into NVIDIA’s enterprise-grade infrastructure, that speed can now scale to the demands of Fortune 500 deployments and hyperscale cloud providers.
Consider a concrete example: a customer support AI agent that needs to read an email thread, check a CRM database, draft a response, verify it against company policy, and send it — all autonomously. That workflow might involve 15-20 sequential inference calls. On GPU infrastructure with 200ms per call, the entire chain takes 3-4 seconds. On Groq 3 LPU hardware, the same chain completes in under 200 milliseconds total. The customer never even notices the AI was thinking. That’s the kind of invisible, instantaneous intelligence that enterprise customers are willing to pay premium prices for.
GPU vs LPU: Not Competition — Coexistence
The emergence of the Groq 3 LPU doesn’t signal the end of the GPU era. Instead, NVIDIA is making a deliberate architectural choice to separate AI workloads into purpose-built hardware tracks.
- Training: Rubin GPU — massive parallel matrix operations, FP8/FP4 precision, multi-thousand GPU clusters
- Inference: Groq 3 LPU — deterministic execution, ultra-low latency, SRAM-based sequential token generation
- Unified platform: NVLink + Groq LPX — seamless transition from training to inference deployment
This division of labor is an attractive proposition for cloud providers (AWS, Azure, GCP) and large AI companies. Until now, both training and inference ran on the same GPU clusters, creating resource contention as inference demand surged. With dedicated Groq LPX racks handling inference, GPU resources stay reserved for training — eliminating the tug-of-war that has plagued AI infrastructure planning.
The economic argument is equally compelling. GPUs are expensive to run for inference because much of their transistor budget goes to features that inference doesn’t need — like the massive floating-point units designed for training’s backward pass. An LPU strips all of that away, dedicating every transistor to forward-pass execution. The result is dramatically better performance per watt and performance per dollar for inference-specific workloads. For cloud providers paying electricity bills on thousands of racks, that efficiency difference translates directly to margin.
NVIDIA’s message from GTC 2026 is unambiguous: the future of AI infrastructure is GPU + LPU, and NVIDIA will supply both. As for whether $20 billion was too much to pay — with the inference hardware market projected to reach $50 billion by 2027, the bet looks increasingly rational.
The tectonic shift in AI hardware is just beginning. Once Groq 3 LPU deployments go live and real-world benchmarks emerge, the competitive landscape for inference hardware will look nothing like it does today. AMD, Intel, and a constellation of AI chip startups — from Cerebras to SambaNova to Tenstorrent — will need to answer a question they’ve never faced before: how do you compete with a chip that has no external memory at all?
One thing is certain: the days of using the same hardware for both training and inference are numbered. NVIDIA has drawn a clear line in the silicon, and the rest of the industry will have to decide which side of that line they want to compete on. For developers, enterprises, and cloud providers watching from the sidelines, the practical advice is straightforward — start evaluating your inference workloads separately from training, because the hardware optimized for each is about to diverge dramatically.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}