
Best Student Tablets August 2025: iPad Air M3 vs Galaxy Tab S10 FE vs Pixel Tablet — Which One Wins?
August 14, 2025
Roland Cloud August 2025: GALAXIAS 1.7 MultiVerb V2, Jupiter-8 Legendary v2, and ZENOLOGY Bundle
August 15, 2025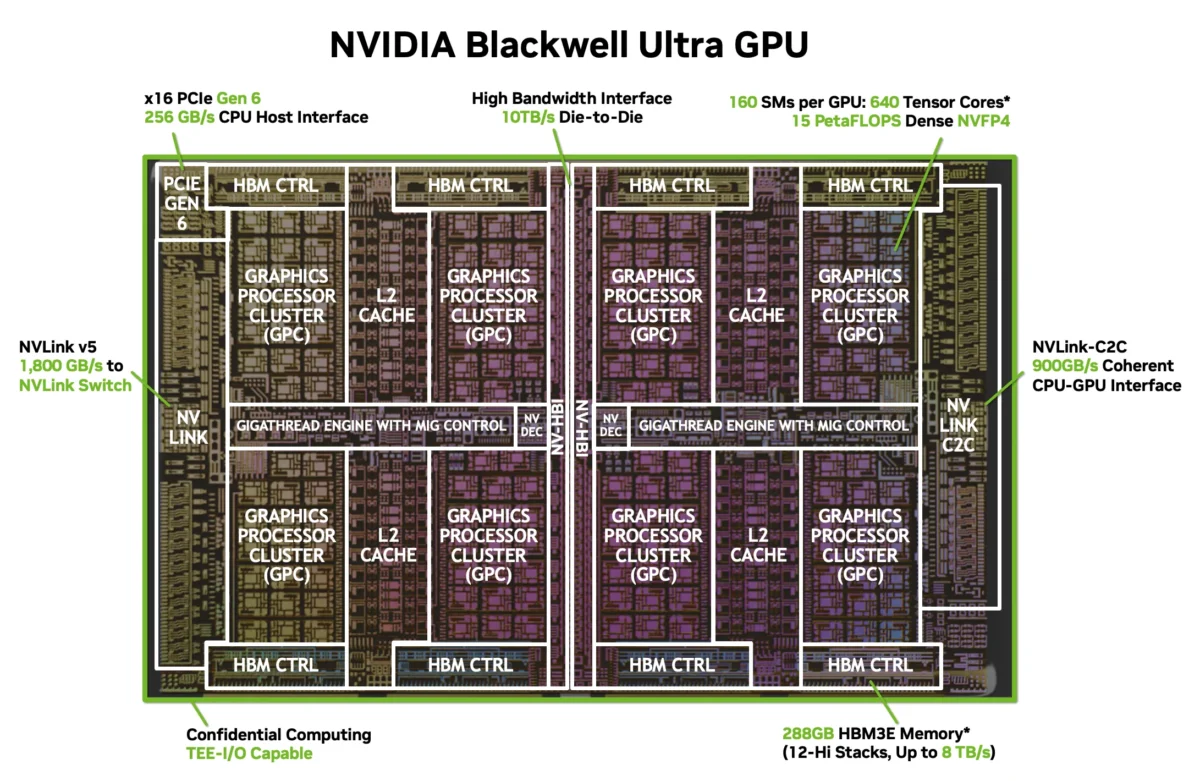
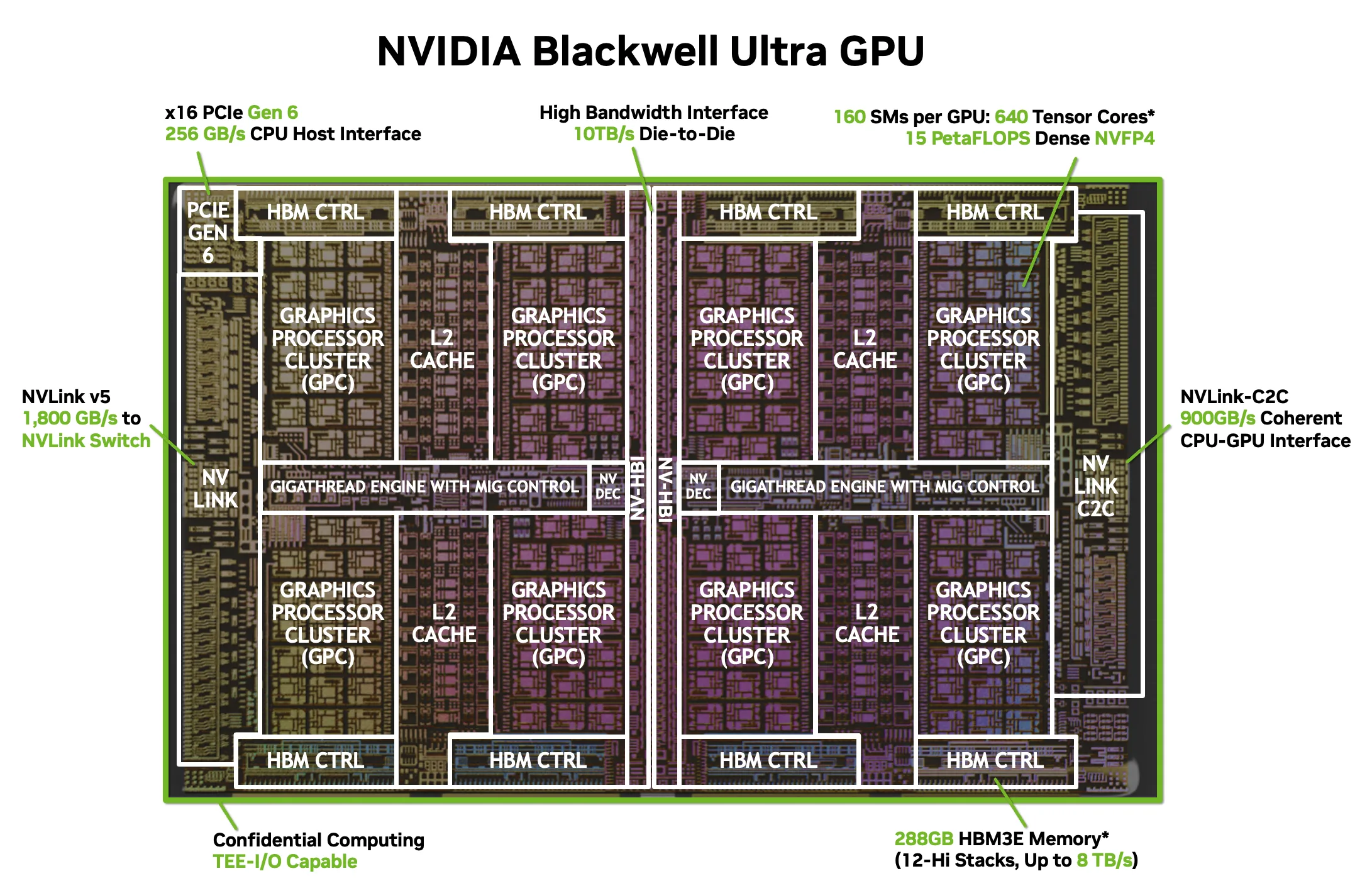
NVIDIA Blackwell Ultra just dropped at Hot Chips 2025, and the numbers are borderline absurd: 208 billion transistors, 15 PetaFLOPS of dense NVFP4 throughput, and a thermal envelope that peaks at 1,400 watts. This isn’t an incremental refresh — it’s the kind of generational leap that forces every AI infrastructure team to rethink their roadmap. Let’s break down exactly what NVIDIA revealed this week at Stanford and why it matters for the entire data center industry.
NVIDIA Blackwell Ultra Architecture: The Dual-Reticle Monster
At the heart of the GB300 GPU sits a dual-reticle die manufactured on TSMC’s 4NP process. Two massive silicon dies are fused together via NVIDIA’s proprietary NV-HBI (High Bandwidth Interface) running at an astonishing 10 TB/s — effectively making them behave as a single monolithic chip. This approach lets NVIDIA sidestep the reticle limits of current lithography while maintaining the programming simplicity of a unified GPU.
The raw specs read like a wishlist from an AI compute engineer: 160 Streaming Multiprocessors housing 20,480 CUDA cores and 640 fifth-generation Tensor Cores. The Tensor Cores are where the real story unfolds — they deliver 15 PetaFLOPS of dense compute in NVIDIA’s new NVFP4 format, 5 PetaFLOPS in FP8 dense, and 10 PetaFLOPS in FP8 sparse mode. Compared to the original Blackwell architecture, that’s a 1.5x improvement in dense NVFP4 throughput and a 2x gain in attention operations.
NVFP4: The New Precision Format That Changes the Math
Perhaps the most significant architectural addition is NVFP4, NVIDIA’s new 4-bit floating-point format. This isn’t just about cramming more operations per clock cycle — it fundamentally changes the memory economics of large language model inference. NVFP4 delivers a 1.8x reduction in memory footprint compared to FP8, which means models that previously required multiple GPUs can now fit within a single Blackwell Ultra’s memory space.
The practical implications are enormous. A 70-billion-parameter model in NVFP4 consumes roughly 35GB of memory versus 63GB in FP8 — well within the 288GB HBM3e capacity of a single GB300. For inference-heavy workloads like AI reasoning, code generation, and multi-turn conversations, this is a game-changer. NVIDIA claims the GB300 NVL72 system delivers 50x the AI factory output compared to Hopper-generation hardware, and the NVFP4 format is a major reason why.
What makes NVFP4 particularly compelling is the quality-performance tradeoff. Early benchmark data suggests that for most inference tasks — including text generation, summarization, and classification — NVFP4 maintains accuracy within 1-2% of FP8 while nearly doubling throughput. For organizations running millions of inference queries daily, this translates directly to either halved infrastructure costs or doubled serving capacity with identical hardware. The economic math is straightforward, and it heavily favors adoption.
288GB HBM3e and 8 TB/s: Memory That Keeps Up
Blackwell Ultra packs 288GB of HBM3e across eight 12-Hi stacks, delivering a combined memory bandwidth of 8 TB/s. That’s a substantial jump that directly addresses the memory wall problem plaguing AI inference workloads. When you’re running mixture-of-experts models or serving thousands of concurrent inference requests, memory bandwidth is often the bottleneck — not raw compute.
The 288GB capacity also enables new MIG (Multi-Instance GPU) configurations: 2x 140GB instances, 4x 70GB instances, or 7x 34GB instances. This flexibility is critical for cloud providers who need to slice a single GPU across multiple tenants without sacrificing isolation or performance predictability. Consider the 7x 34GB configuration — each slice provides enough memory for a 13B-parameter model in FP16 or a much larger model in NVFP4, making it viable for serving diverse workloads on a single physical GPU.
NVLink 5 and the 576-GPU Fabric
NVIDIA’s NVLink interconnect reaches its fifth generation with Blackwell Ultra. Each GPU gets 18 NVLink 5 links at 100 GB/s each, totaling 1.8 TB/s of bidirectional bandwidth. The chip-to-chip NVLink connection runs at 900 GB/s, and the system also supports PCIe Gen 6 x16 at 256 GB/s for host connectivity.
But the real flex is the topology: NVLink 5 enables a non-blocking fabric connecting up to 576 GPUs. That’s 576 Blackwell Ultra GPUs communicating at full bandwidth without congestion — the kind of scale needed for training next-generation frontier models. For context, this is roughly 8.6 quadrillion FP4 operations per second across the full fabric.
GB300 NVL72: The Rack-Scale AI Supercomputer
The GB300 NVL72 is where all these components come together into a single rack-scale system: 72 Blackwell Ultra GPUs paired with 36 Grace CPUs, connected by 130 TB/s of NVLink bandwidth, and delivering 1.1 exaFLOPS of dense FP4 compute. The entire system is fully liquid-cooled — and according to Tom’s Hardware, the cooling system alone costs approximately $50,000 per rack, with next-generation NVL144 racks expected to push that to $56,000.
To put the performance in perspective: a single NVL72 rack delivers more AI compute than entire data center floors did just three years ago. NVIDIA positions this as the building block for “AI factories” — dedicated facilities whose primary output isn’t traditional computation but trained models and inference capacity.

Attention Acceleration: 2x Performance Where It Matters Most
One of the less-discussed but critically important improvements is the enhanced attention accelerator. Blackwell Ultra delivers 2x the attention performance of the original Blackwell, rated at 10.7 TeraExponentials per second. In an era where transformer-based models dominate — and attention mechanisms are the computational bottleneck of every LLM inference pass — this improvement directly translates to faster token generation and reduced latency for real-time AI applications.
Combined with the NVFP4 format and expanded HBM3e capacity, the attention acceleration makes Blackwell Ultra particularly well-suited for the emerging class of reasoning models like OpenAI’s o-series and Google’s Gemini. These models perform significantly more compute per query than traditional LLMs, making them extremely sensitive to both memory bandwidth and attention throughput.
Hot Chips 2025: Beyond the GPU
NVIDIA’s Hot Chips 2025 presence extended well beyond the Blackwell Ultra reveal. The company also presented its ConnectX-8 SuperNIC, co-packaged optics leveraging silicon photonics, and the Spectrum-XGS Ethernet platform designed specifically for AI super-factories. There was also a session on the DGX Spark GB10 architecture — a desktop-class AI system — and neural rendering capabilities running on Blackwell silicon.
What’s striking about this year’s Hot Chips lineup is the holistic approach: NVIDIA isn’t just making faster GPUs, they’re building the entire ecosystem — from chip to rack to network fabric to software stack. It’s a level of vertical integration that makes it increasingly difficult for competitors to match on a system level, even if individual components close the gap.
Blackwell Ultra vs. Hopper vs. Blackwell: The Generational Leap
Here’s how the three generations stack up on key metrics:
- NVFP4 Throughput: Blackwell Ultra delivers 7.5x the throughput of Hopper (which didn’t support FP4 natively)
- Dense NVFP4 vs. Blackwell: 1.5x improvement generation-over-generation
- Attention Performance: 2x versus original Blackwell
- Memory: 288GB HBM3e at 8 TB/s (up from 192GB on Blackwell)
- AI Factory Output: 50x versus Hopper-based systems in NVIDIA’s benchmarks
- TDP: Up to 1,400W (requiring liquid cooling for NVL72 deployments)
The 50x AI factory improvement versus Hopper deserves context — this isn’t a single-chip metric but a system-level comparison factoring in NVFP4 precision, NVLink 5 bandwidth, and the NVL72 rack architecture working in concert. Individual chip improvement is closer to 7-8x for inference workloads, which is still a massive generational gain.
The Power and Cooling Reality
The 1,400W TDP per GPU isn’t just a number on a spec sheet — it represents a fundamental shift in data center design philosophy. At this power level, air cooling is physically insufficient. Every GB300 NVL72 deployment requires purpose-built liquid cooling infrastructure, and the $50,000 cooling cost per rack is just the beginning. Factor in the power delivery infrastructure, redundancy systems, and the electrical grid capacity needed to feed rows of NVL72 racks, and the total cost of ownership picture becomes very different from previous GPU generations.
This is driving a new category of data center construction — AI-native facilities designed from the ground up for liquid cooling at megawatt scale. Companies like Equinix, Digital Realty, and newer entrants are racing to build facilities specifically optimized for this class of hardware. The infrastructure moat around AI computing is getting deeper with every generation.
What This Means for the AI Infrastructure Market
The NVIDIA Blackwell Ultra architecture sends a clear signal: the AI infrastructure arms race is accelerating, not plateauing. With every major cloud provider — AWS, Azure, GCP, Oracle — scrambling to secure GB300 NVL72 allocations, the supply constraints that defined the Hopper and Blackwell eras are likely to repeat. The $50,000 cooling cost per rack is just one data point in what will be billions of dollars in total infrastructure investment across the industry.
For organizations planning AI infrastructure deployments, the key takeaway from Hot Chips 2025 is this: Blackwell Ultra isn’t just faster — it’s architecturally different in ways that enable new workload categories. The combination of NVFP4 precision, doubled attention performance, and rack-scale NVLink fabric means workloads that were economically impractical on Hopper become viable on Blackwell Ultra. And that shift will drive the next wave of AI applications we haven’t even imagined yet.
Navigating AI infrastructure decisions — from GPU selection to deployment architecture — requires deep technical understanding. If you need expert guidance on your AI hardware strategy, let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}