
Best Laptops of 2025: Year-End Roundup from Budget to Premium
December 2, 2025
Best Music Production Gear of 2025: Top Picks Across All Categories
December 3, 2025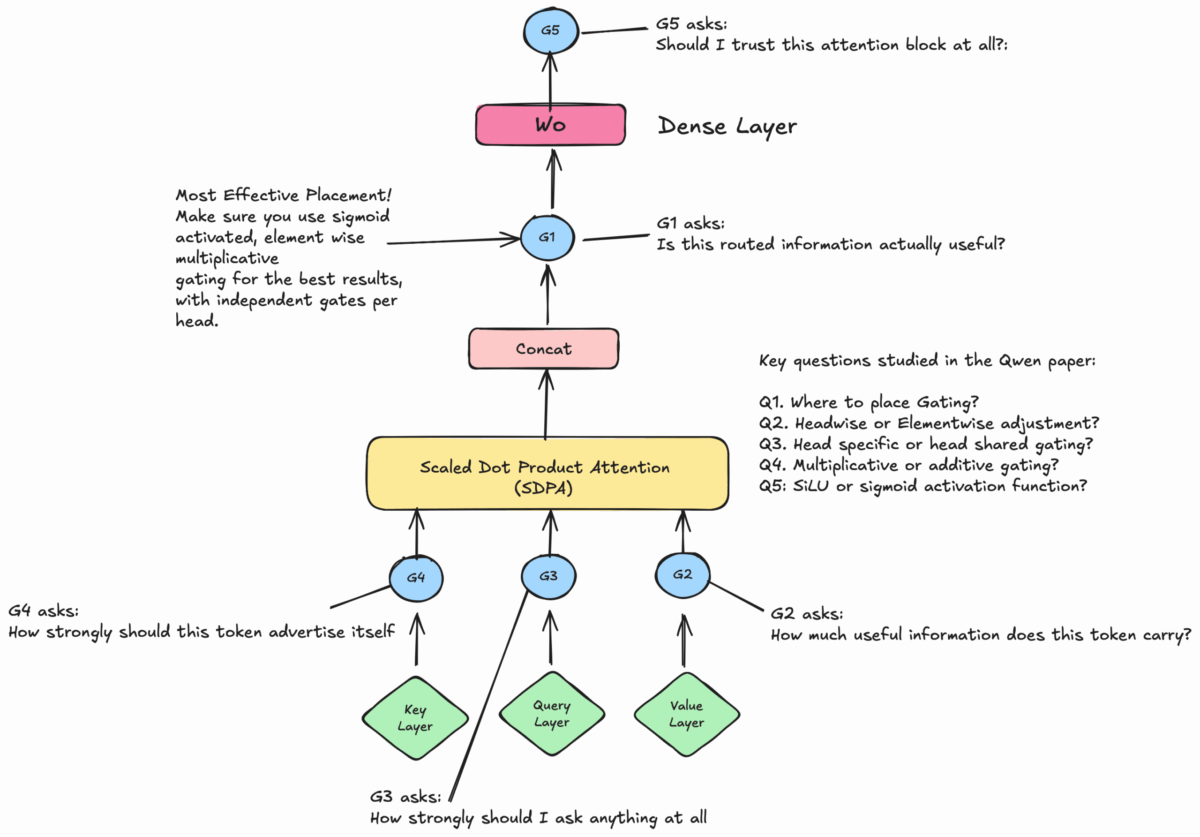
The NeurIPS 2025 best papers have just been announced, and they are nothing short of extraordinary. Forget incremental improvements — this year’s winners at the 39th Conference on Neural Information Processing Systems in San Diego include a technology already shipping in production models, a 1,024-layer reinforcement learning network that defies conventional wisdom, and a sobering warning about AI homogenization that should concern every technologist. Here is why these five papers will define the next chapter of artificial intelligence.
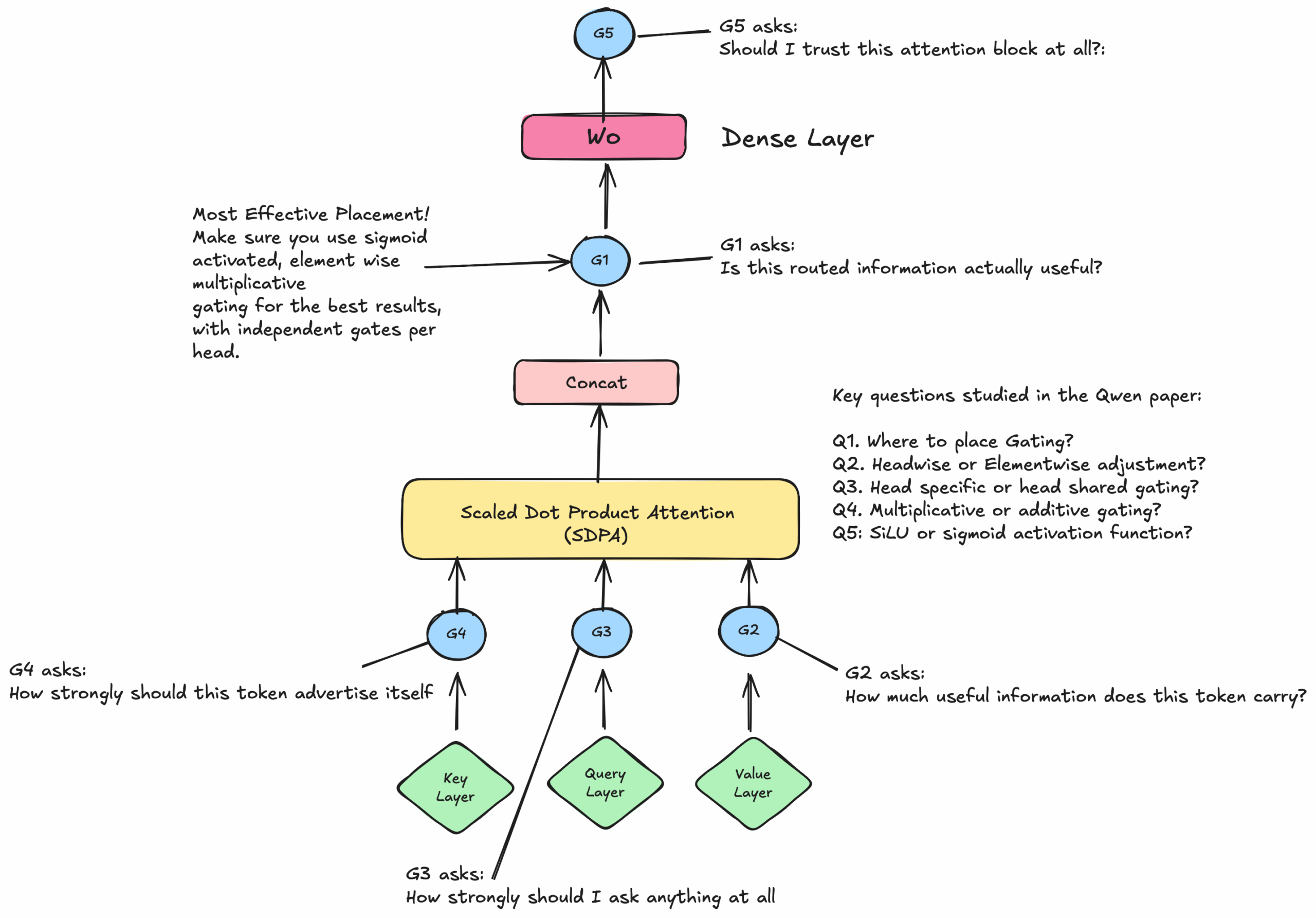
1. Gated Attention: Alibaba Qwen Rewrites the Transformer Playbook
The most immediately impactful of the NeurIPS 2025 best papers comes from Alibaba’s Qwen team. Their paper, “Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free,” introduces a deceptively simple modification to the transformer architecture that yields sweeping improvements across the board.
The core idea is straightforward: add a head-specific sigmoid gate right after Scaled Dot-Product Attention (SDPA). But the execution is anything but simple. Lead author Zihan Qiu and colleagues systematically explored five distinct gating positions — labeled G1 through G5 — and tested over 30 architectural variants. Their experiments ran on both a 15-billion parameter Mixture-of-Experts model and a 1.7-billion dense model, trained on a massive 3.5 trillion tokens.
The results were decisive. The G1 position (sigmoid gate after SDPA) emerged as the clear winner, delivering three critical advances:
- Elimination of the attention sink phenomenon: In standard transformers, the first token in a sequence often receives disproportionately high attention weights regardless of its relevance. Gated attention eliminates this anomaly entirely, producing cleaner and more semantically meaningful attention patterns.
- Superior long-context extrapolation: Models with gated attention maintain stable performance on inputs significantly longer than their training context length — a critical capability for real-world applications like document analysis and code generation.
- Consistent scaling improvements: As model size increases, gated attention delivers increasingly reliable performance gains, suggesting this modification becomes more valuable, not less, at larger scales.
What makes this paper truly remarkable is its immediate practical impact. The gated attention mechanism is already being integrated into Qwen3-Next, Alibaba’s upcoming model release. The implementation is open-source, and given the simplicity of the modification and the strength of the results, industry observers expect other major LLM developers to adopt gated attention within 6 to 12 months. This is not theoretical research waiting for applications — it is a production-ready improvement to the fundamental building block of modern AI.
2. The Artificial Hivemind: Are AI Models Converging Into a Single Worldview?
If the gated attention paper represents the engineering pinnacle of NeurIPS 2025, the “Artificial Hivemind” paper represents its philosophical reckoning. Researchers from the University of Washington, Carnegie Mellon, and the Allen Institute for AI constructed the Infinity-Chat benchmark — comprising 26,000 queries and 31,000 human annotations — to conduct the most comprehensive study of LLM homogeneity ever attempted.
The findings are striking. Testing over 70 language models, the team documented pronounced homogenization occurring at two levels. Intra-model homogeneity means that a single model tends to produce remarkably similar outputs across repeated queries, lacking the natural variation you would expect from diverse human respondents. Inter-model homogeneity means that different models — GPT, Claude, Gemini, Llama, and others — are converging toward similar response patterns, styles, and even value judgments.
Lead author Liwei Jiang and the team argue this raises profound questions about the long-term consequences of an AI-saturated information ecosystem. If the models that increasingly mediate our access to information, education, and creative tools all think alike, what happens to human creativity? To value plurality? To the kind of independent, contrarian thinking that has driven every major breakthrough in human history?
This is not an abstract concern. Companies are already deploying LLMs for content generation, educational tutoring, hiring decisions, medical advice, and policy analysis. If all these systems share the same blind spots and biases — and this research suggests they increasingly do — the implications for society are serious and underexplored. The NeurIPS committee’s decision to award this paper a Best Paper prize signals that the AI research community is taking these concerns seriously at the highest level.
3. 1,000-Layer RL Networks: Depth Scaling Reaches Reinforcement Learning
For years, reinforcement learning practitioners have operated under an unquestioned assumption: RL networks should be shallow, typically 2 to 5 layers deep. Kevin Wang, Ishaan Javali, and their co-authors shattered this assumption with dramatic flair, scaling RL networks all the way to 1,024 layers and demonstrating 2x to 50x performance improvements in goal-conditioned self-supervised reinforcement learning.
The significance of this result cannot be overstated. The deep learning revolution in natural language processing was built on the insight that deeper networks learn richer representations. The same scaling philosophy drove the success of large language models. But RL had been left behind, with researchers assuming that the credit assignment problem and training instabilities made deep RL networks impractical.
This paper proves otherwise. Without any external demonstrations or reward signals — using purely self-supervised objectives — the 1,024-layer networks achieved capabilities that shallow networks simply could not reach, regardless of width or training time. The implications extend directly to autonomous robotics, game AI, autonomous driving, and any domain where agents must learn complex, multi-step behaviors from experience.
If gated attention rewrites the rules for language models, this paper rewrites the rules for everything else. The age of deep reinforcement learning has arrived.
The practical applications are already coming into focus. Robotics companies that have struggled with the sample efficiency of shallow RL networks now have a clear path forward: go deeper. The 2x to 50x improvement range suggests that many RL tasks previously considered too difficult for current methods may simply have been under-parameterized. Expect a wave of new results in robotic manipulation, navigation, and multi-agent coordination as labs begin adopting this approach.
4. Why Diffusion Models Create Rather Than Copy: A Mathematical Proof
Every time someone generates an image with Midjourney, DALL-E, or Stable Diffusion, a fundamental question lurks in the background: is the model creating something new, or simply remixing its training data? Tony Bonnaire and colleagues have provided the most rigorous answer to date, and it is good news for the generative AI industry.
Their paper delivers a mathematical proof that diffusion model training operates on two distinct timescales. During the first phase, the model learns to generalize — capturing the underlying distribution of its training data rather than memorizing individual examples. Only in a later phase does memorization begin, and critically, the onset of memorization grows linearly with dataset size.
This means that for models trained on the massive datasets used in practice — millions or billions of images — the generalization phase dominates, and the model produces genuinely novel outputs rather than reconstructions of training examples. This finding has immediate implications for the ongoing legal and ethical debates around AI-generated content and copyright. It also provides practical guidance for developers: by understanding the memorization dynamics, teams can design training regimes that maximize creativity while minimizing the risk of reproducing copyrighted material.
For the legal landscape, this paper could prove pivotal. Ongoing copyright lawsuits in the United States and Europe have often hinged on the question of whether generative models are “copying” or “learning from” training data. This mathematical framework provides the clearest scientific evidence yet that properly trained diffusion models operate in a generalization regime, not a memorization one. Legal teams on both sides of these cases will be studying this paper closely.
5. Superposition and Neural Scaling Laws: Why Bigger Really Is Better
The final paper in our NeurIPS 2025 best papers roundup — a runner-up prize winner — tackles one of the most important open questions in AI: why do neural scaling laws work? Yizhou Liu, Ziming Liu, and Jeff Gore identify representation superposition as the key mechanism. In essence, LLMs can represent more distinct features than they have dimensions, a kind of efficient data compression that improves as models grow larger.
The mathematical relationship is elegant: loss scales inversely with model dimension. Double the model size, and you get a predictable, reliable improvement in performance. This is not just a description of what happens — it is an explanation of why it happens, grounded in the geometry of high-dimensional feature spaces.
For the AI industry, this paper validates the continued investment in larger models while also providing a theoretical framework for understanding when scaling will deliver diminishing returns. It is the kind of foundational work that helps companies make better decisions about where to allocate billions of dollars in compute spending.
The superposition insight also connects to interpretability research — understanding how models store and retrieve knowledge internally. If features are superimposed rather than stored in dedicated neurons, this has profound implications for alignment and safety work. Researchers trying to understand what models “know” and how they make decisions now have a clearer theoretical grounding for why feature extraction is so challenging and why larger models exhibit emergent capabilities that smaller ones do not.
What NeurIPS 2025 Best Papers Tell Us About the Future of AI
Taken together, this year’s NeurIPS 2025 best papers reveal three major trends shaping the future of artificial intelligence.
First, architectural innovation is far from over. The transformer architecture that has dominated AI since 2017 is still being refined in fundamental ways. Gated attention shows that relatively simple modifications can yield outsized improvements — and that the best ideas often come from systematic exploration rather than radical redesign.
Second, scaling is a universal principle. The depth scaling breakthrough in reinforcement learning demonstrates that the “bigger is better” insight from LLMs applies far beyond language. As researchers learn to scale other domains — vision, robotics, scientific simulation — we should expect similar step-function improvements.
Third, the AI research community is maturing in its treatment of societal impact. The Hivemind paper’s Best Paper award signals that understanding and mitigating AI’s broader effects on society is now recognized as first-class scientific work, not a secondary concern.
NeurIPS 2025 runs from December 2 through 7 in San Diego, with detailed presentations and workshops covering these papers and the rest of the program. For anyone working in AI — whether you are a researcher, engineer, product manager, or investor — these five papers deserve a close read. They will shape the products, capabilities, and conversations that define 2026.
One final observation worth noting: the geographic and institutional diversity of this year’s winners is remarkable. From Alibaba’s industrial research lab in China to academic teams at UW and CMU, from European mathematicians tackling diffusion theory to a cross-institutional team challenging RL conventions — the best AI research is a genuinely global endeavor. That diversity of perspective is itself a counterpoint to the Hivemind paper’s warnings, and a reminder that the research community’s greatest strength lies in its plurality of approaches and viewpoints.
Get weekly AI, music, and tech trends delivered to your inbox.
Looking to integrate cutting-edge AI into your business? Let us help you navigate the latest advances and build a strategy that works.



{kind=link}
{kind=link}
{kind=link}