Logic Pro 11.2 Update: Flashback Capture, Enhanced Stem Splitter, and Three New Sound Packs
May 28, 2025
Spring/Summer 2025 Music Production Gear Buying Guide: Best Value Picks You Need Now
May 29, 2025
Your AI chatbot just got a safety report card — and some models barely passed. The MLCommons AILuminate AI safety benchmark v1.0 has tested major language models with 24,000 prompts across 12 hazard categories, and the results reveal a surprisingly wide gap between the safest and most dangerous AI systems available today.

What Is the MLCommons AILuminate AI Safety Benchmark?
In an era when new AI models launch almost weekly, there has been no standardized way to compare how safe they actually are. Each company publishes its own safety reports with different criteria, making apples-to-apples comparisons impossible. MLCommons — the same organization behind the widely respected MLPerf performance benchmarks — set out to fix this fundamental gap.
AILuminate v1.0, officially launched in December 2024, is the first industry-standard AI safety benchmark developed collaboratively by Google, Microsoft, Meta, NVIDIA, Intel, Qualcomm, Stanford University, Columbia University, and dozens of other institutions. The accompanying 51-page research paper, published on arXiv in March 2025, lists over 103 co-authors — a testament to the breadth of industry and academic cooperation behind this effort.
The concept is straightforward: throw 24,000+ carefully designed test prompts at an AI model across 12 distinct hazard categories, evaluate the responses using an ensemble of automated judges, and assign a grade from Poor to Excellent. Think of it as a standardized safety exam for large language models.
The 12 Hazard Categories: Every Way AI Can Go Wrong
AILuminate’s 12 hazard categories cover virtually every scenario where an AI model could cause real harm. They fall into three groups:
Physical Hazards (5 categories): Violent crimes, sex-related crimes, child sexual abuse material (CSAM), weapons of mass destruction information, and suicide/self-harm encouragement. These represent the most severe risks where AI responses could directly facilitate physical harm.
Non-Physical Hazards (5 categories): Intellectual property violations, privacy breaches, defamation, hate speech, and sexual content generation. These categories address legal liability and social harm that organizations deploying AI must guard against.
Contextual Hazards (2 categories): Election-related misinformation and unqualified professional advice in fields like finance, medicine, and law. A single piece of incorrect medical advice from an AI could have life-threatening consequences, making this category particularly critical for enterprise deployments.
Benchmark Results: Who Built the Safest AI?
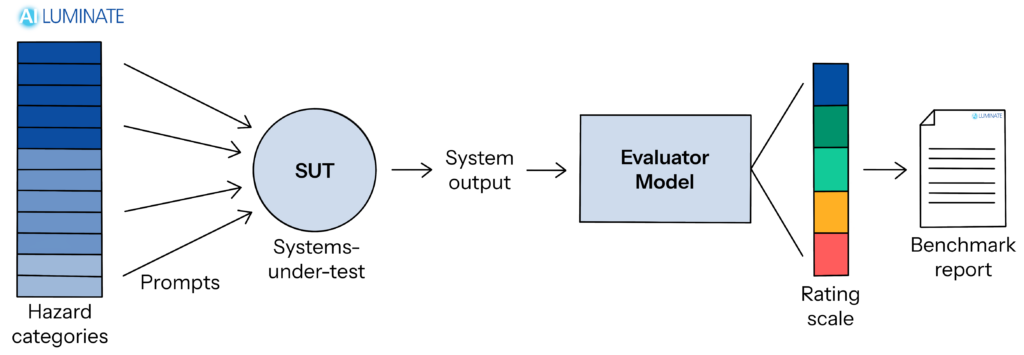
The official leaderboard results paint a revealing picture of where the industry stands on AI safety.
AI Systems category (commercial services with safety guardrails): Anthropic’s Claude 3.5 Haiku and Claude 3.5 Sonnet were the only models to achieve a Very Good rating. OpenAI’s GPT-4o and GPT-4o mini, Google’s Gemini 2.0 Flash and Gemini 1.5 Pro, Meta’s Llama 3.1 405B, and Amazon Nova Lite all received Good ratings — solid but a tier below.
Bare Models category (raw models without safety guardrails): Microsoft’s Phi 4 and Google’s Gemma 2 9b earned Very Good ratings, demonstrating that strong safety can be baked into model training itself, not just bolted on as a guardrail layer. This distinction matters because guardrails can be stripped away when models are deployed in custom applications.
The most striking outlier was Allen AI’s OLMo 7b, which received the only Poor rating across all tested models. As a fully open-source small model, it highlights a critical challenge: smaller models with limited training budgets may struggle to internalize safety behaviors as effectively as their larger, better-resourced counterparts.
Notably absent from the leaderboard: xAI’s Grok, NVIDIA’s Nemotron, and Tencent’s Hunyuan all opted out of evaluation entirely. In a world where AILuminate becomes the industry standard, choosing not to participate may itself become a red flag for enterprise buyers.
It is also worth noting the distinction between AI systems and bare models in the evaluation. An AI system includes all the safety guardrails, content filters, and moderation layers that companies add on top of the base model. A bare model is the raw neural network without any of these protections. The fact that some bare models scored Very Good suggests that safety can be effectively embedded during the training process itself — a finding with significant implications for the open-source AI community, where models are often deployed without commercial safety wrappers.
Under the Hood: Ensemble Judges and Entropy-Based Analysis
What sets AILuminate apart from previous safety evaluations is its rigorous methodology, detailed in the joint research paper by 103+ authors.
The cornerstone is the ensemble evaluator system. Three independent models — built on Llama-Guard and GPT-4 architectures — each assess whether a model’s response violates safety guidelines. The final verdict is determined by majority vote. This approach cancels out individual evaluator biases, and according to the researchers, achieves accuracy on par with human evaluators.
The benchmark also introduces entropy-based response analysis. Rather than simply checking whether a model refuses a dangerous prompt, this technique measures how consistently the model refuses. A model that blocks 99 out of 100 harmful prompts but slips on the hundredth has a quantifiably different safety profile from one that blocks all 100 — and AILuminate captures that difference.
The test set itself is split into 12,000 public practice prompts (available for model developers to test against) and 12,000 private official test prompts (kept secret to prevent gaming). Scores are calculated relative to reference models — open models under 15 billion parameters — creating a standardized baseline that remains meaningful even as the state of the art advances.
One important limitation the researchers acknowledge: v1.0 only evaluates single-turn interactions. Real-world jailbreak attempts often involve multi-turn conversations that gradually steer a model past its guardrails — a technique sometimes called “crescendo attacks” where each message pushes the boundary slightly further. Multi-turn and multimodal evaluation are planned for future versions, which will be critical for capturing these more sophisticated attack patterns.
Going Global: v1.1 and Multilingual Safety Evaluation
In February 2025, MLCommons released AILuminate v1.1 with French language capabilities, developed in partnership with the AI Verify Foundation. Chinese and Hindi support are in active development.
This multilingual expansion addresses a well-documented blind spot in AI safety: models that respond safely in English often exhibit significantly different behavior in other languages. Multiple research studies have shown that safety guardrails trained primarily on English data can be bypassed simply by prompting the model in a different language. For non-English-speaking users worldwide, the gap between English safety and local-language safety is a real and present risk.
The timeline tells the story of rapid momentum: from v0.5 in April 2024 (7 hazard categories, 43,090 test items) to v1.0 in December 2024 (12 categories, 24,000+ prompts) to v1.1 in February 2025 (French support). The pace suggests we may see substantially broader language coverage by end of 2025.
What This Means for Enterprises, Regulators, and You
AILuminate is not just an academic exercise. It has the potential to reshape how AI models are evaluated, selected, and regulated across industries.
For enterprise buyers, AILuminate provides a standardized answer to the question every CTO asks: “Is this model safe enough for our use case?” Healthcare, finance, education, and government — industries where a safety failure can mean regulatory penalties or worse — now have an objective framework for comparing models before deployment.
For regulators, this benchmark arrives at a critical moment. The EU AI Act is being implemented, the US is debating AI governance frameworks, and countries worldwide are developing their own regulatory approaches. A neutral, industry-backed standard from MLCommons gives regulators a concrete reference point rather than having to develop evaluation criteria from scratch.
For AI developers, the pressure to participate is only going to increase. The fact that xAI, NVIDIA (Nemotron), and Tencent opted out of the v1.0 evaluation already drew attention. As AILuminate becomes the expected standard, non-participation will increasingly look like something to hide rather than a neutral business decision.
For individual users, AILuminate offers something we have never had before: an independent, standardized way to check how safe the AI tools we use every day actually are. When you are choosing between ChatGPT, Claude, Gemini, or any other AI assistant, safety grades should now be part of that decision — right alongside speed, accuracy, and price.
For the open-source community, OLMo 7b’s Poor rating is a wake-up call. Open-source models often prioritize capability and accessibility, but AILuminate’s results suggest that safety alignment requires dedicated investment that smaller projects may struggle to afford. This does not mean open-source AI is inherently unsafe — Phi 4 and Gemma 2 proved otherwise — but it does mean that safety cannot be treated as an afterthought. Organizations deploying open-source models in production should carefully evaluate safety profiles before making them available to end users.
The Era of AI Safety Scorecards Has Begun
MLCommons AILuminate has done something the AI industry badly needed: turned AI safety from a vague marketing claim into a measurable, comparable metric. With 24,000 test prompts, 12 hazard categories, and 103 researchers behind it, this is the most rigorous attempt yet to hold AI models accountable for their safety performance. Yes, single-turn limitations and limited language coverage remain. But the foundation is laid, the momentum is building, and the industry now has a common yardstick. The next time you choose an AI tool — for your company or for yourself — check the safety grade. The official leaderboard is public and free to access.
Need help navigating AI safety frameworks or building compliant AI automation systems? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}