RIAA 2025 Year-End Report: US Recorded Music Revenue Hits $11.5 Billion as Paid Streaming Subscriptions Cross 106 Million
March 26, 2026
TypeScript 6.0: The Last JavaScript-Based Release Before the Go Rewrite — What Changes, What Dies, and How to Migrate
March 27, 2026
The open-source AI landscape just shifted dramatically. On March 16, 2026, Mistral AI dropped Mistral Small 4 — a 119B parameter Mixture of Experts model under Apache 2.0 — and it’s not just competitive with proprietary models. It’s beating them while using fewer resources to do it. The benchmark numbers don’t lie: GPT-OSS 120B outperformed on LiveCodeBench, 40% lower latency than its predecessor, and 3x the throughput on identical hardware.
Why Mistral Small 4 Changes the Game: Three Models Unified Into One
Here’s what makes Mistral Small 4 genuinely interesting: it consolidates three previously separate models — Magistral (reasoning), Devstral (coding), and Pixtral (vision) — into a single unified architecture. Before this, organizations had to deploy and manage different models for different task types. Need reasoning? Spin up Magistral. Code generation? Switch to Devstral. Image analysis? Route to Pixtral. Each with its own GPU allocation, monitoring pipeline, and update cycle.
Now you get text reasoning, code generation, and image analysis from one endpoint. The implications for infrastructure cost and operational complexity are significant. Three model deployments collapse into one. Three sets of GPU memory requirements become one. Three update pipelines merge into a single workflow. For engineering teams managing AI infrastructure, this is a genuine quality-of-life improvement that translates directly to reduced operational overhead.
The practical killer feature? A reasoning_effort parameter that lets you dial reasoning depth in real-time. Set it to "none" for fast, Small 3.2-level responses — perfect for simple Q&A or text classification tasks. Crank it to "high" for deep, Magistral-grade step-by-step reasoning that can tackle complex mathematical problems or multi-step coding challenges. This means you can optimize cost vs. quality on a per-request basis — something that was previously impossible without building custom routing logic between separate model endpoints.
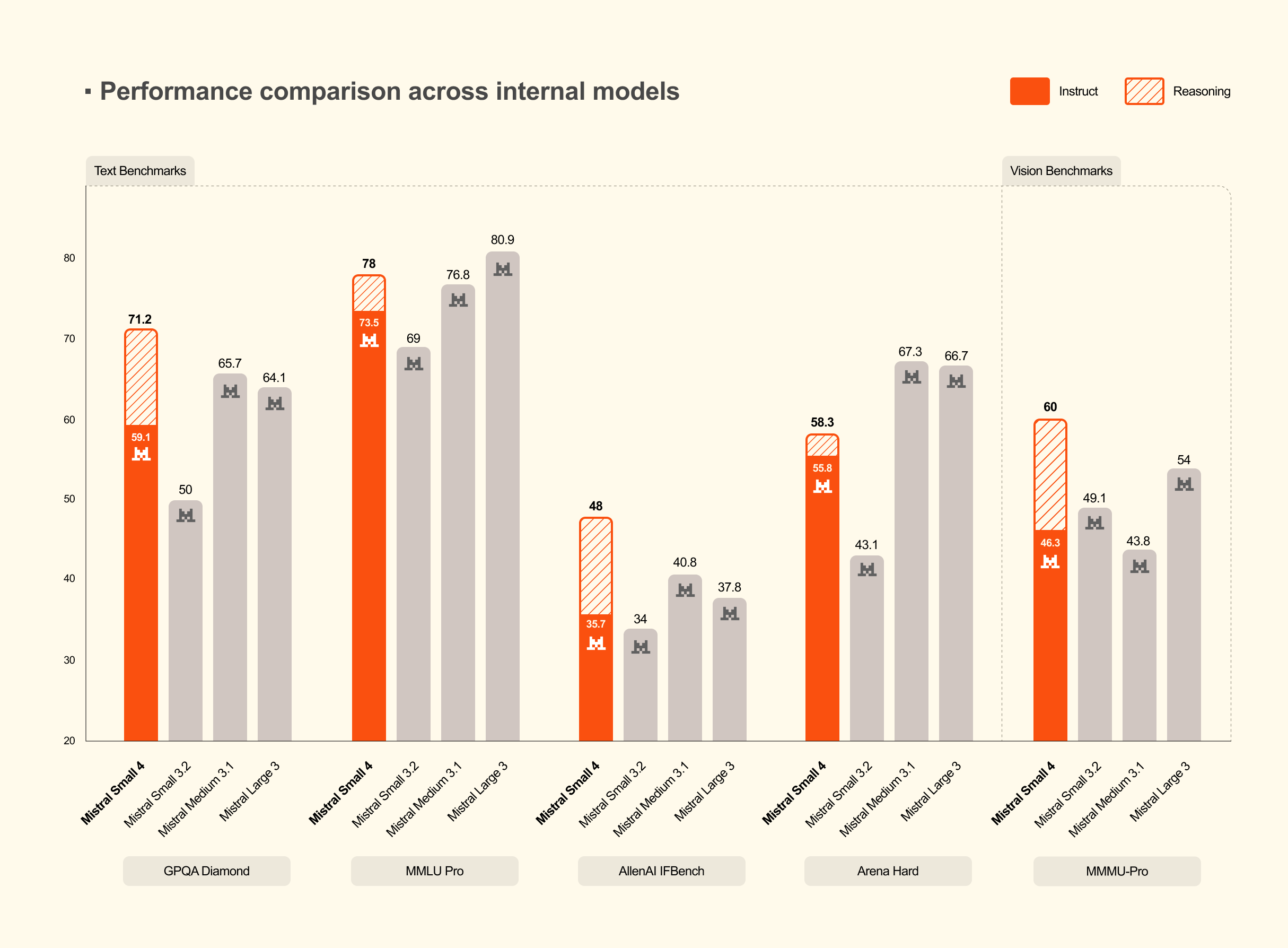
Inside the MoE Architecture: 128 Experts, Only 4 Active Per Token
The Mistral Small 4 architecture tells a fascinating efficiency story through its Mixture of Experts design. The model contains 128 expert networks, but only 4 are activated per token. This means that while total parameters sit at 119B, the actual active computation per inference is roughly 6B parameters (8B including embedding and output layers). This is the fundamental magic of MoE architecture at scale.
In a traditional dense model, all 119B parameters would need to be activated for every single token, making inference prohibitively expensive. But with MoE, a gating network selects the 4 most relevant experts for each token. The remaining 124 experts sit idle for that particular computation, incurring zero additional compute cost. Think of it as having a team of 128 specialists but only consulting the 4 most relevant ones for each specific question.
Why does this matter in practice? Compare it to Small 3, which activated 24B parameters per token. With Small 4, a workload handling 100 requests per second on Small 3 infrastructure can now handle 300 requests per second. Total parameters went up 5x, but active parameters dropped 75% — resulting in dramatically better real-world throughput. For companies processing millions of API calls monthly, this efficiency difference translates directly into substantial infrastructure cost savings.
The 256K token context window deserves attention as well. Whether you’re analyzing large codebases, reviewing lengthy legal documents, or conducting research that requires cross-referencing multiple papers simultaneously, you’re far less likely to hit context limitations. This expanded context combined with the MoE efficiency means you can feed the model more information without proportionally increasing compute costs.
Benchmark Deep Dive: Head-to-Head with GPT-OSS 120B
The benchmark numbers tell a compelling story that goes beyond simple performance matching. According to Mistral AI’s official announcement, with reasoning enabled, Mistral Small 4 scored 0.72 on the AA LCR benchmark using just 1.6K characters of output. For context, Qwen-series models needed 5.8K to 6.1K characters — 3.5 to 4 times more output — to achieve comparable scores. Efficiency isn’t just about speed; it’s about doing more with less.
This difference has real-world financial implications. When your model generates fewer output tokens to reach the same answer quality, response times improve and token-based API billing drops proportionally. For organizations making millions of API calls monthly, a 3.5x reduction in output tokens per request represents a massive cost optimization — potentially saving thousands of dollars per month without sacrificing accuracy.
On LiveCodeBench, the results are even more striking. Mistral Small 4 outperformed GPT-OSS 120B while producing 20% less output. This coding benchmark superiority is particularly noteworthy because it demonstrates the model’s viability as a development tool. Combined with the AIME 2025 mathematical reasoning benchmark — where it also showed competitive results — Mistral Small 4 proves itself as a genuine all-rounder rather than a specialist model that excels in one domain at the expense of others.
- Latency: 40% reduction vs. Small 3 (optimized setup)
- Throughput: 3x increase vs. Small 3 (requests per second)
- LiveCodeBench: Outperforms GPT-OSS 120B with 20% less output
- AA LCR: 0.72 score with 3.5-4x less output than competitors
- Context Window: 256K tokens for handling large-scale inputs
- AIME 2025: Competitive mathematical reasoning performance confirmed
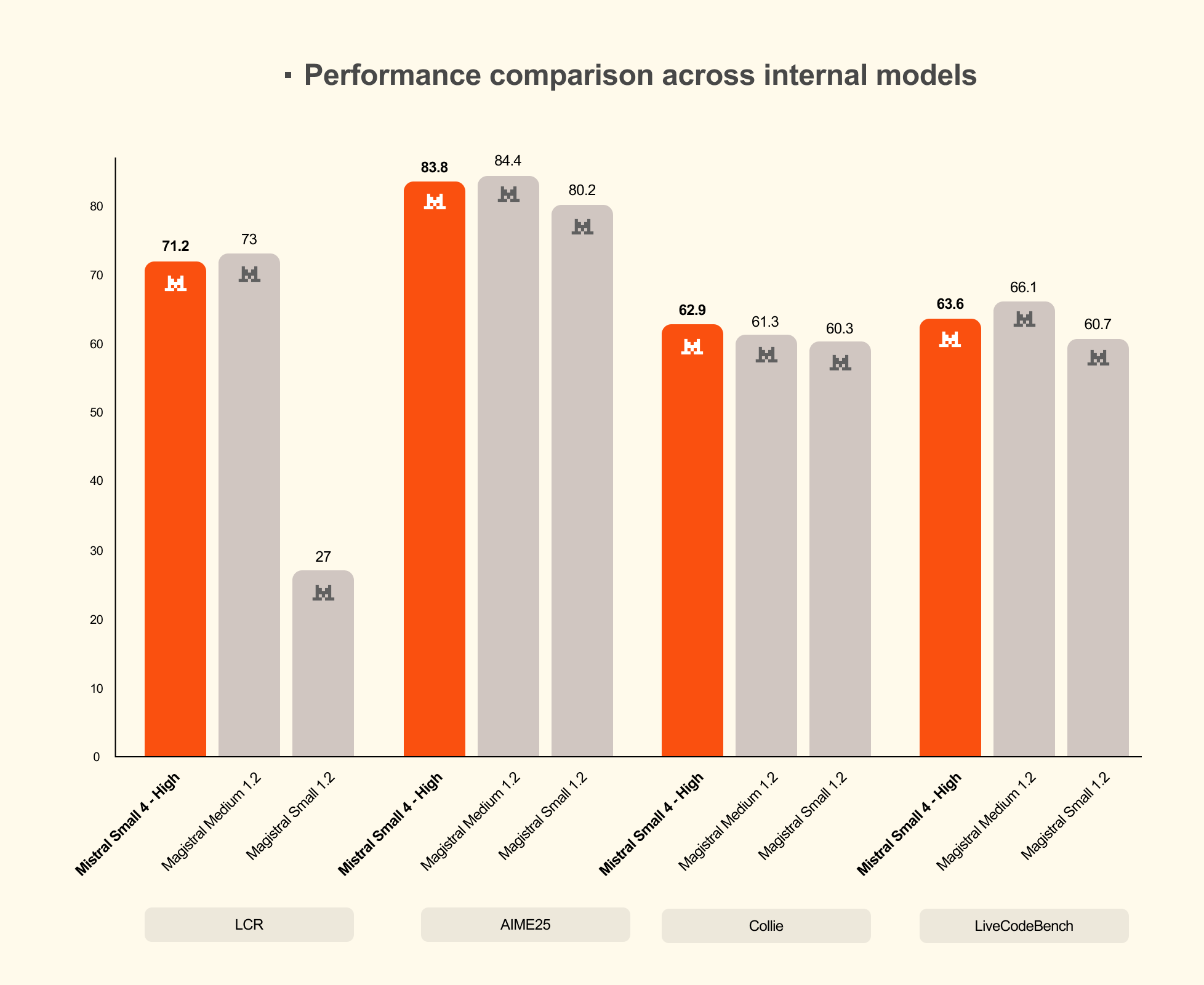
Multimodal Capabilities and Enterprise Use Cases
Mistral Small 4 accepts both text and image inputs, inheriting Pixtral’s vision capabilities in full. This means image analysis, chart interpretation, document OCR, and screenshot analysis are all possible without a separate vision model deployment. Manufacturing quality inspection lines can analyze defect images; financial teams can automatically interpret report charts; legal departments can process scanned documents — all through a single model endpoint.
For enterprise teams running multi-modal pipelines, this consolidation eliminates an entire layer of infrastructure complexity. Consider the practical implications: a company that previously maintained separate endpoints for reasoning, coding assistance, and visual document processing can now unify everything behind a single deployment. That’s not just a cost saving — it’s a fundamental simplification of the AI stack that reduces maintenance burden, minimizes monitoring overhead, and eliminates potential failure points between model handoffs.
From a DevOps perspective, the benefits compound. Model updates, rollbacks, and scaling operations all happen through a single pipeline. Load balancing becomes simpler when you’re managing one model instead of three. And with the configurable reasoning_effort parameter, you can implement sophisticated request routing within the same model — using lightweight inference for simple tasks and deep reasoning for complex ones — without maintaining separate infrastructure for each.
The Competitive Landscape: Why MoE Architecture Is the Future
The competitive landscape context matters here. When Mistral Small 3 launched, it was already considered efficient for its class. But Small 4 represents a fundamentally different approach to model scaling. Rather than simply making the model bigger and hoping for better results, Mistral’s engineering team redesigned the expert routing system to maximize the ratio of model knowledge to active compute. The result is a model that knows as much as a 119B parameter model but thinks as fast as a 6B one. This architectural philosophy — maximizing knowledge density while minimizing inference cost — may well define the next generation of practical AI models for production use.
Apache 2.0 License and the Deployment Ecosystem
The Apache 2.0 licensing isn’t just a checkbox item — it’s a deployment enabler. Full commercial use, modification, and redistribution rights mean organizations can deploy on their own infrastructure with complete control over their data and model behavior. No API dependency, no usage-based pricing surprises, no data sovereignty concerns. For industries like finance, healthcare, and government where data control is non-negotiable, this licensing model is the difference between “interesting research” and “deployable solution.”
The ecosystem support is substantial and production-ready: NVIDIA NIM provides Day-0 support with enterprise-grade inference optimization, and integration with Hugging Face, vLLM, llama.cpp, SGLang, and Transformers is ready out of the box. Having NVIDIA NIM support from launch day means teams planning production deployments can leverage optimized inference serving immediately rather than spending weeks on custom optimization.
The catch? Self-hosting requires minimum 4x H100 GPUs, 2x H200s, or 1x DGX B200. This isn’t a model you’ll run on a laptop or a single consumer GPU. But for organizations with existing GPU infrastructure, the ROI case is compelling: eliminate recurring API costs, maintain full data control, and serve 3x more requests per second compared to the previous generation. For teams without dedicated hardware, Mistral’s cloud API provides an immediate on-ramp while the self-hosting case builds over time.
The Bottom Line: A New Benchmark for Open-Source AI
Mistral Small 4 has set a new standard for what open-source AI models can deliver. The 128-expert MoE architecture with only 4 active per token achieves an efficiency breakthrough that enables both better performance and lower operational costs simultaneously. Consolidating three specialized models into one unified system while maintaining top-tier quality in each domain — reasoning, coding, and vision — is a genuine engineering achievement that simplifies the entire AI deployment stack. With GPT-OSS 120B-beating benchmarks, 40% lower latency, 3x throughput, and Apache 2.0 licensing, the argument for staying locked into proprietary AI APIs is getting harder to make. If your organization has been weighing the move from proprietary to self-hosted open-source models, Mistral Small 4 makes that transition more compelling than ever.
Need help deploying open-source LLMs or building AI automation pipelines? Let’s find the right solution for your stack.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}