
How to Use AI for Music Production: Ethical and Practical Guide 2026
January 26, 2026
Best Budget Microphones 2026: 8 Top Vocal Mics Under $200 (Post-NAMM Guide)
January 27, 2026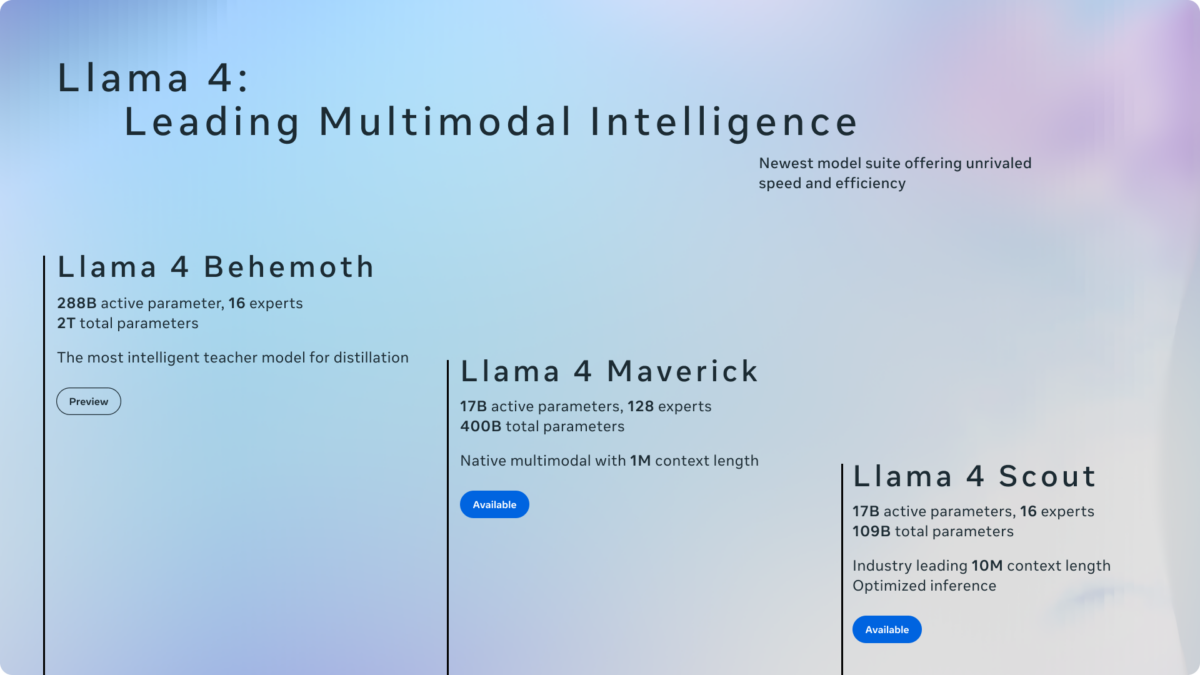
Meta Llama 5 open source AI is finally taking shape, and what we’re seeing is nothing short of extraordinary. Codenamed ‘Avocado,’ the next-generation model promises 10x compute efficiency for text and up to 100x for specific workloads—numbers that could fundamentally reshape who gets to build with frontier AI. As someone who’s spent 28+ years at the intersection of music, audio, and technology, I can tell you: this is the kind of inflection point that changes entire industries overnight. We are entering a phase where the cost-performance curve of open-weight models threatens to obsolete the traditional API-first business model that companies like OpenAI and Anthropic have built their revenue strategies around.
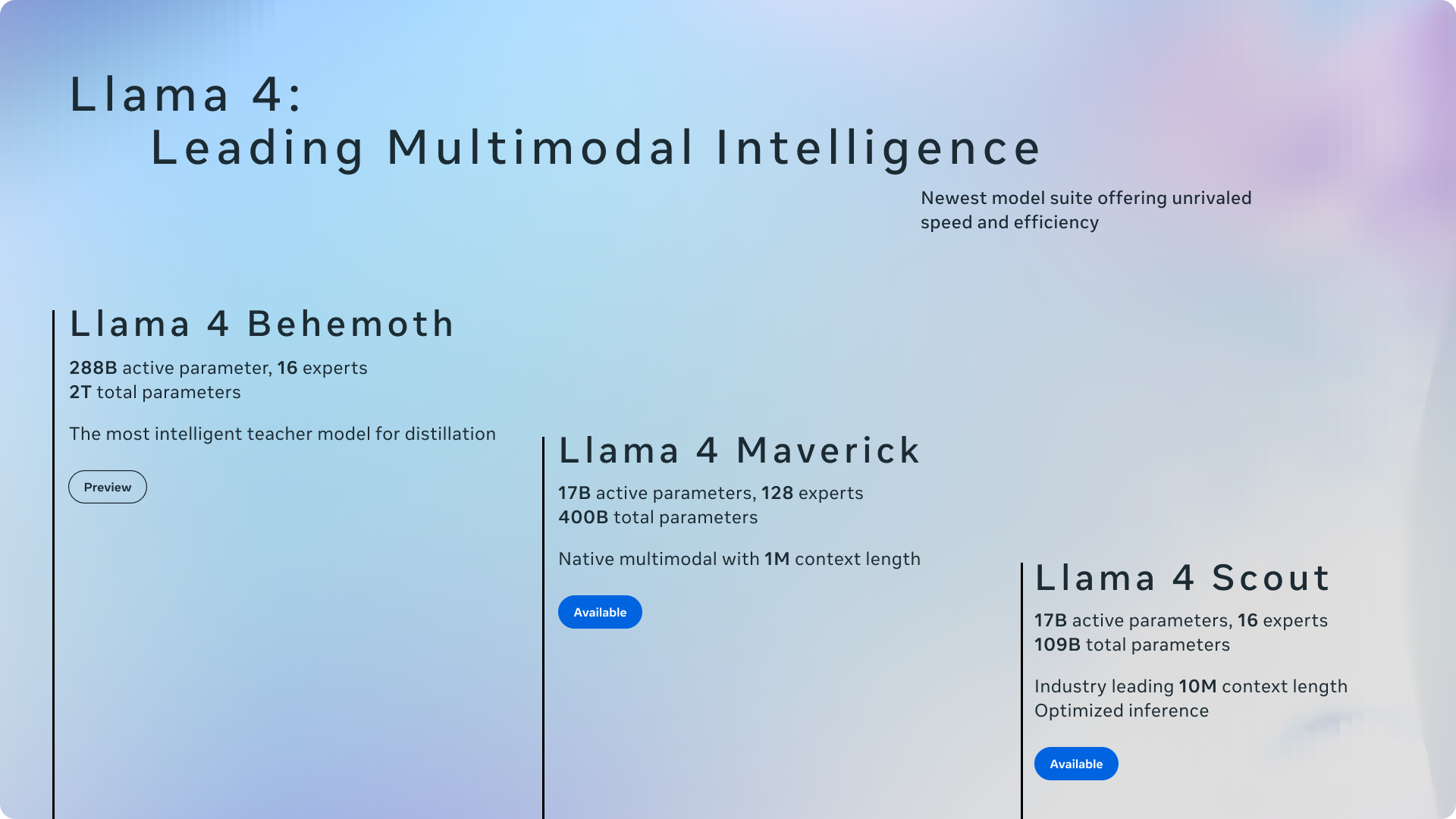
The Llama 4 Foundation: Scout, Maverick, and Behemoth
Before we look ahead, let’s ground ourselves in where Meta stands today. The Llama 4 family, released in April 2025, introduced a full Mixture of Experts (MoE) architecture across the lineup. Scout runs 17B active parameters across 16 expert networks with a staggering 10 million token context window. Maverick matches the 17B active parameter count but scales to 128 experts for broader task coverage. These models established a critical proof point: MoE architectures can deliver frontier performance while keeping inference costs dramatically lower than dense models of equivalent capability.
The real showpiece, however, is Behemoth—still in training as of early 2026. With 288B active parameters and roughly 2 trillion total parameters, it’s already posting benchmark numbers that demand attention. On MATH-500, Behemoth scores 95.0, compared to GPT-4.5’s approximate 90 and Claude 3.7’s 82.2. Its MMLU Pro score of 82.2 further cements its position at the frontier. But Behemoth’s most significant role may be behind the scenes: Meta is using it as a teacher model for co-distillation, compressing its intelligence into the smaller, deployable Scout and Maverick models. Enterprise previews are planned for 2026.
What makes the Llama 4 foundation particularly relevant is the competitive pressure it already exerts. DeepSeek R1, released in late 2025, demonstrated that Chinese AI labs could match or exceed Western frontier models at a fraction of the training cost. DeepSeek’s success sent shockwaves through Silicon Valley and arguably accelerated Meta’s timeline for both Behemoth completion and Avocado development. The message was clear: efficiency innovation, not just raw scale, would determine the next generation of AI leadership. Avocado’s accelerated development timeline is a direct strategic response to this competitive reality.
Codename Avocado: The Meta Llama 5 Open Source AI Blueprint
According to leaked roadmap details, Meta’s next-generation model carries the internal codename ‘Avocado.’ The ambition is staggering: 10x compute efficiency for standard text processing, with certain specialized workloads seeing up to 100x improvement. Here’s what we know about the technical pillars:
- Deterministic Training: Reproducible training pipelines that ensure consistent model quality across runs—a major step toward production reliability.
- New Multimodal Encoder: A unified architecture handling text, image, and audio natively within a single model.
- Enhanced Long Context + Tool Calls + Reasoning Speed: Building on Scout’s 10M-token context window while dramatically improving agentic capabilities and inference throughput.
- GPT-5 and Gemini 3 Ultra Performance Targets: Meta is explicitly benchmarking against OpenAI’s and Google’s next-generation models.
From my perspective as CEO of Montadecs, where we integrate AI tools into real production workflows, the 10x efficiency claim is the headline that matters most. It’s not just about speed—it’s about making frontier-level AI accessible to organizations that don’t have hyperscaler budgets. That’s a genuine democratization moment.
To put the efficiency gains in concrete terms, consider the current economics of self-hosted versus API-based AI deployment. Running a Llama 4 Maverick instance on a cluster of 8x NVIDIA H100 GPUs costs roughly $25,000-$30,000 per month in cloud infrastructure. An equivalent volume of API calls to GPT-4-class models would run $40,000-$80,000 monthly for a mid-scale enterprise application. If Avocado delivers even half of its promised 10x efficiency improvement, the self-hosted cost drops to $5,000-$6,000 per month—a price point that brings frontier AI within reach of startups, research labs, and mid-market companies that were previously priced out entirely. The Avocado efficiency revolution is fundamentally an economic story as much as a technical one.
The practical implications for MoE fine-tuning workflows are equally significant. Today, fine-tuning an MoE model like Maverick requires careful expert routing configuration, selective expert freezing to avoid catastrophic forgetting, and significant GPU memory overhead because all experts must be loaded even though only a subset activates per token. Avocado’s deterministic training pipeline is expected to simplify this process considerably. Early indications suggest Meta is developing tooling that allows practitioners to fine-tune specific expert subsets without loading the full model into memory—a workflow that could reduce fine-tuning costs by 60-70% compared to current approaches. For enterprise teams running domain-specific adaptations, this is a game-changer.

The Open Source Question: Will Avocado Stay Open?
Here’s where things get complicated—and frankly, concerning. Reports indicate that Meta is actively considering making Avocado a closed-source release. The proposal under discussion: API-only access with no downloadable model weights. If true, this would represent a seismic shift from the open-source strategy that made Llama the most widely adopted foundation model family in the world.
Consider the ecosystem at stake. Llama models have surpassed 650 million cumulative downloads. Over 85,000 derivative models exist on HuggingFace alone. Enterprise adoption doubled year-over-year, and the open source AI market has grown 340% YoY. A closed Avocado wouldn’t just affect Meta—it would send shockwaves through the entire open-source AI ecosystem.
That said, VentureBeat reports that internal confusion persists, suggesting the final decision hasn’t been made. Meta appears to be weighing the competitive advantages of proprietary control against the ecosystem moat that open-source distribution provides. The DeepSeek factor looms large here as well—if Chinese labs can replicate or exceed Avocado-level performance with open weights, Meta closing its model would hand the open-source AI crown to competitors while gaining little strategic advantage. It is a high-stakes poker game with the future of open-weight AI distribution hanging in the balance.
$65-72 Billion in Conviction: Meta’s AI Infrastructure Bet
Whatever happens with the open-source question, Meta’s financial commitment to AI is unambiguous. The company’s 2026 AI infrastructure capex sits between $65 and $72 billion. That figure includes $1.5 billion in talent acquisition—headlined by the recruitment of Scale AI founder Alexandr Wang as Chief AI Officer—and a $2.7 billion Hyperion Data Center currently under construction.
This isn’t R&D spending in the traditional sense. Meta is rebuilding its entire product stack—Facebook, Instagram, WhatsApp, and Reality Labs—around AI-first architectures. Llama 5 (Avocado) will serve as the foundation model powering this transformation. As TechNewsWorld characterized it, we’re witnessing an “open-source AI tsunami”—though the open-source part of that description may need an asterisk going forward.
To put Meta’s investment in competitive context: Google’s 2026 AI capex is estimated at $50-$55 billion, while Microsoft’s sits around $60 billion. Amazon Web Services has committed approximately $45 billion. Meta’s $65-$72 billion figure makes it the single largest AI infrastructure investor in the world—a remarkable position for a company that generates its revenue primarily from advertising rather than cloud services or enterprise software. This signals that Meta views AI foundation models not as a product line but as the core infrastructure layer for its entire 3.9-billion-user ecosystem.
What Practitioners Should Do Right Now
With CES 2026 (January 6-10) and NAMM 2026 (January 20-25) freshly behind us, the industry’s attention has fully pivoted to the next-generation model race. Here’s what I’d recommend based on what we know today:
Invest in MoE expertise now. The Mixture of Experts architecture validated by Llama 4 will carry forward into Avocado. The ratio of active to total parameters keeps widening, meaning inference costs drop while capability rises. If you’re fine-tuning MoE models today, you’re building skills that will directly transfer to the next generation. Specifically, learn expert routing patterns, understand how to configure load balancing across experts, and practice selective expert fine-tuning on domain-specific datasets. Teams that master these workflows now will have a 6-12 month head start when Avocado drops.
Build multimodal pipelines. Avocado’s new unified encoder architecture signals that text-only workflows are becoming a limitation. For those of us in the music and audio space, a single model handling text, image, and audio natively could transform production workflows from multi-tool chains into integrated AI-first pipelines. Consider the implications for healthcare as well: a unified multimodal model could process patient notes (text), medical imaging (vision), and patient-reported voice recordings (audio) in a single inference pass, dramatically reducing diagnostic pipeline complexity. In education, the same architecture enables AI tutors that simultaneously analyze written responses, diagram submissions, and spoken explanations—creating genuinely adaptive learning experiences. These vertical applications represent where the real enterprise value of Avocado’s open-weight distribution will ultimately be realized.
Hedge your open-source bets. If your infrastructure depends heavily on downloadable Llama weights, start mapping contingency plans now. Evaluate the 85,000+ HuggingFace derivatives as potential fallbacks. Diversify across model families—Mistral’s Mixtral line, Alibaba’s Qwen series, and the emerging DeepSeek ecosystem all offer viable MoE alternatives. The worst-case scenario is being locked into an API-only dependency without alternatives. Build abstraction layers in your inference stack so that swapping underlying models requires configuration changes, not code rewrites.
The Meta Llama 5 open source AI story is ultimately about more than one model or one company. It’s about whether the most powerful AI systems in the world will remain accessible to everyone—or become gated behind API paywalls. Behemoth’s teacher model role, Avocado’s efficiency revolution, and the open-source strategy pivot together make 2026 the most consequential year in AI since the transformer architecture was introduced. The competitive dynamics between Meta, OpenAI, Google, and increasingly capable players like DeepSeek ensure that no single company can afford to slow down. For practitioners, the strategic imperative is clear: build deep expertise in MoE architectures, invest in multimodal infrastructure, and maintain optionality across model providers. Stay sharp, stay informed, and most importantly—start building now.
Navigating the Llama 5 transition, evaluating MoE architectures, or building AI-first infrastructure? With 28+ years in music, audio, and tech, I help organizations turn AI hype into production-ready systems.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}