Google Pixel 10 Pro Review: 7 Tensor G5 Camera & AI Features That Actually Matter
June 11, 2025
Granular Synthesis Ambient Music: Sound Design Guide for Evolving Textures
June 12, 2025
For the first time in AI history, an openly available model has gone toe-to-toe with the best closed-source systems — and won on several benchmarks. Meta’s Llama 3.1 405B, released on July 23, 2024, isn’t just another incremental update. With 405 billion parameters trained on 16,000 H100 GPUs, this is Meta’s boldest bet yet that the future of AI is open.
Why Meta Llama 3.1 405B Matters: The Numbers Don’t Lie
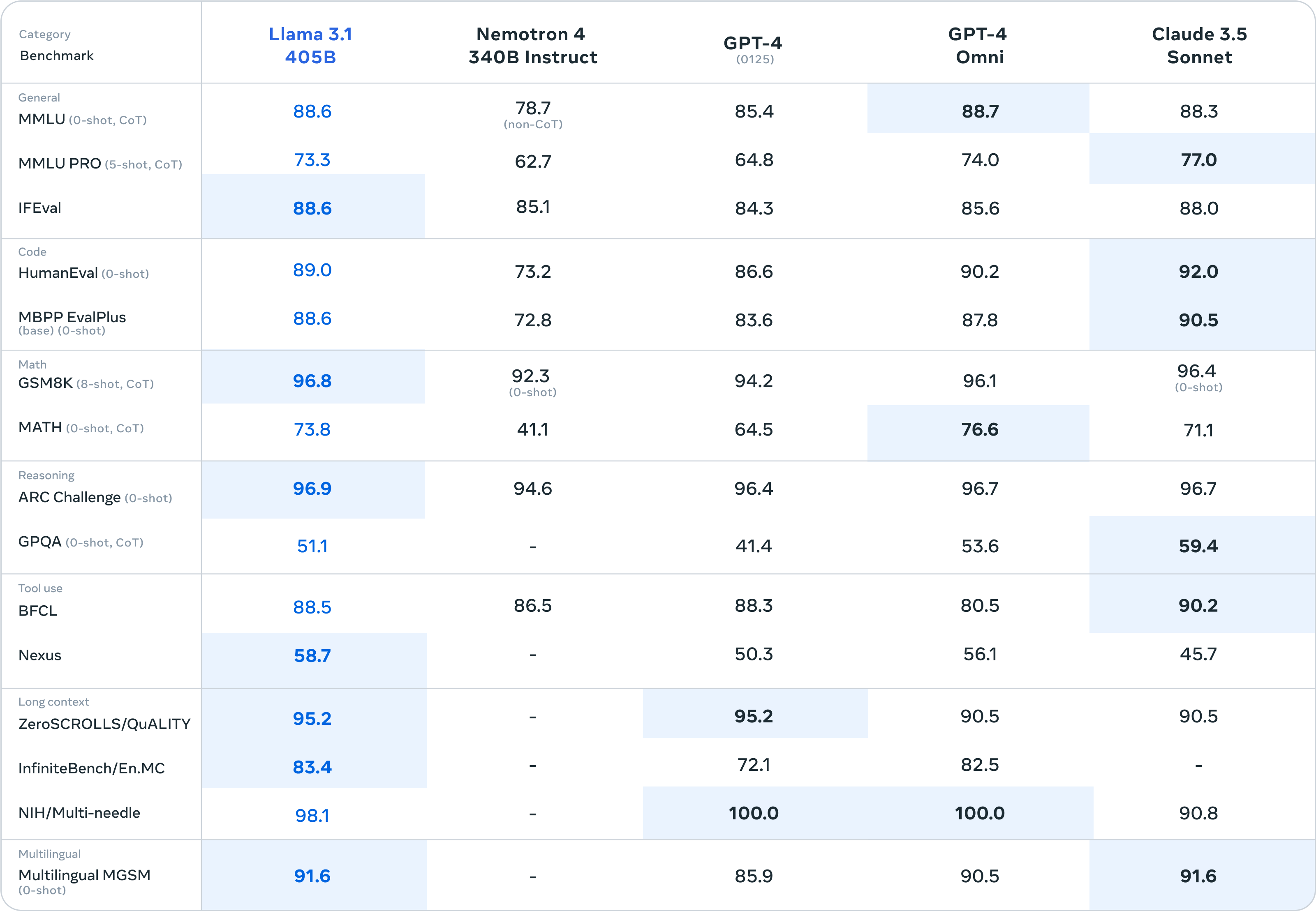
Let’s cut straight to what everyone wants to know: can an open-source model actually compete with GPT-4o and Claude 3.5 Sonnet? The benchmarks say yes — emphatically.
On the DROP reading comprehension benchmark, Llama 3.1 405B scored 84.8, outperforming GPT-4o’s 83.4 and Claude 3 Opus’s 83.1. In math reasoning (MATH 0-shot CoT), it hit 73.8% — trailing GPT-4o’s 76.6% but beating GPT-4 Turbo at 72.6% and Claude 3.5 Sonnet at 71.1%. On HumanEval coding tasks, the 405B instruct model scored an impressive 89.0%, and on the MMLU academic benchmark, it reached 87.3%.
These aren’t cherry-picked results. Meta evaluated the model across over 150 benchmark datasets, and the conclusion is clear: Llama 3.1 405B is the first openly available model to achieve genuine parity with frontier closed-source systems.

405 Billion Parameters: Inside the Architecture
What makes the 405B technically fascinating is Meta’s decision to use a dense transformer architecture rather than a mixture-of-experts (MoE) approach. While MoE models like Mixtral activate only a subset of parameters per inference, Meta opted for a standard decoder-only transformer where all 405 billion parameters are active during every forward pass. The reasoning? Greater stability during training at unprecedented scale.
The training numbers are staggering. Meta used over 15 trillion tokens of training data — the equivalent of reading every book in the Library of Congress roughly 15,000 times over. This training ran across a custom cluster of 16,000 NVIDIA H100 GPUs, making it one of the largest training runs in AI history. The model supports a 128K context window (up from 8K in Llama 3), putting it on par with GPT-4o’s enterprise context length and enabling processing of hundreds of pages of content in a single prompt.
Post-training involved iterative rounds of supervised fine-tuning (SFT) and direct preference optimization (DPO), with Meta using synthetic data generation to improve the model’s instruction-following capabilities. The final model was also quantized from BF16 to FP8 numerics, reducing compute requirements for inference without significant quality loss.
The Open-Source Play: Why Meta Is Giving Away Frontier AI
This is the question that keeps OpenAI and Google executives up at night. Why would Meta invest hundreds of millions of dollars training the largest openly available AI model and then release it for free?
Mark Zuckerberg’s strategy is increasingly clear: by commoditizing the AI layer, Meta ensures that competitive advantage shifts to distribution and application — areas where Meta dominates with 3+ billion daily active users across Facebook, Instagram, and WhatsApp. If the best AI model is free, there’s no reason for enterprises to pay OpenAI or Google premium prices, and the ecosystem gravitates toward Meta’s platform.
The license change is also significant. Unlike previous Llama releases, developers can now use Llama 3.1 outputs to train other models. This single change enables synthetic data generation at scale, model distillation, and fine-tuning workflows that were previously restricted — effectively turning the 405B into a teacher model for the entire open-source AI community.
Enterprise Impact: 25+ Partners and 50% Cost Reduction
The enterprise response has been immediate and overwhelming. Twenty-five partners offered Llama 3.1 support on day one, including AWS, NVIDIA, Databricks, Groq, Dell, Microsoft Azure, Google Cloud, and Snowflake. Monthly Llama usage grew 10x from January to July 2024 across major cloud providers, and the 405B variant quickly became the most popular model among unique users.
For startups and mid-sized enterprises, the financial impact is profound. Running a frontier-level AI model on your own infrastructure — with full control over data privacy, customization, and costs — was previously impossible without building your own model from scratch. Now, organizations willing to manage their own infrastructure can cut high-level AI costs by an estimated 50% compared to API-based closed-source alternatives.
On Hugging Face, Llama has spawned over 60,000 derivative models — fine-tuned versions optimized for everything from medical diagnosis to legal document analysis. This vibrant ecosystem is something no closed-source model can replicate.
Eight Languages, 128K Context: The Multilingual Advantage
Llama 3.1 supports eight languages out of the box: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. While this doesn’t cover every language (notably missing Korean, Japanese, and Chinese in the official support list), the open nature of the model means the community can fine-tune it for additional languages — and many already have.
The 128K context window is a game-changer for enterprise use cases. Legal teams can feed entire contracts for analysis. Development teams can provide full codebases for review. Research teams can process lengthy papers with full context retention. This puts Llama 3.1 on par with GPT-4o’s enterprise context length, removing one of the last technical advantages closed-source models held.
What This Means for the AI Industry
The release of Llama 3.1 405B represents what many are calling AI’s “Linux moment.” Just as Linux commoditized server operating systems and eventually became the foundation for cloud computing, Llama 3.1 405B could commoditize the foundation model layer of AI.
For developers, this means unprecedented choice. You can use the 8B model for lightweight applications, the 70B for most production use cases, and the 405B for tasks that require frontier-level intelligence — all without API rate limits, usage fees, or data privacy concerns. For enterprises, it means the build-vs-buy calculus for AI has fundamentally shifted.
The competitive pressure on OpenAI and Google is real. If the best model is free and open, the value proposition of paying for API access becomes harder to justify. This doesn’t mean closed-source models will disappear — they’ll likely compete on ease of use, ecosystem integration, and specialized capabilities. But the floor has been raised for everyone.
Whether you’re building AI-powered applications, evaluating LLMs for enterprise deployment, or simply trying to understand where the industry is headed, Llama 3.1 405B is the most important AI release of 2024 so far. The era of open-source AI competing at the frontier isn’t coming — it’s here.
Want to integrate open-source AI models into your production pipeline or build custom automation systems? Let’s talk about what’s possible.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}