
Apple iPhone 17 Pro Review: Camera Bar, A19 Pro Benchmarks, and Why the $1,099 Upgrade Actually Delivers
September 30, 2025Waves Nx Head Tracking: 5 Virtual Studios That Turn Any Headphones into an Immersive Mix Room
October 3, 2025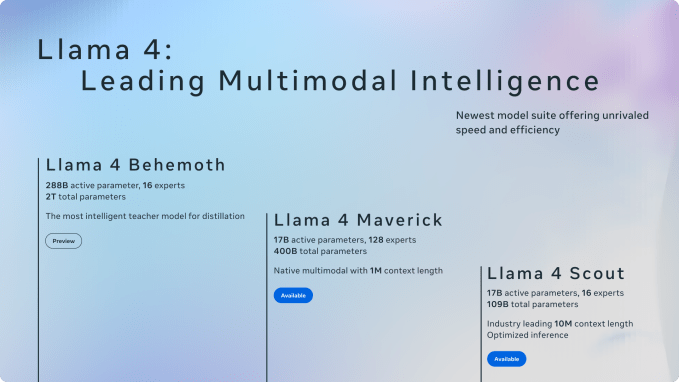
A 109-billion-parameter multimodal AI model that fits on a single GPU — Meta actually pulled it off. Llama 4 Scout, unveiled at Meta Connect 2025, runs with just 17B active parameters while delivering GPT-4-class performance. This is Llama 4 on-device AI at its most ambitious, and it changes everything about how we think about edge deployment.
Meta Connect 2025: The Foundation of Llama 4 On-Device AI Strategy
On September 17–18 at Meta’s Menlo Park campus, Mark Zuckerberg didn’t just announce products — he laid out a vision he called “Personal Superintelligence.” A system that remembers your events, summarizes key moments, and provides real-time coaching. The technical backbone of this vision? Llama 4 on-device AI processing that keeps your data exactly where it belongs: on your device.
The critical difference from cloud-centric AI is data sovereignty. Messages, calendar entries, personal context — all processed locally. No round trips to distant servers. No privacy compromises. Meta’s answer to the question of what AI looks like in the privacy era is unequivocal: it runs on your hardware.
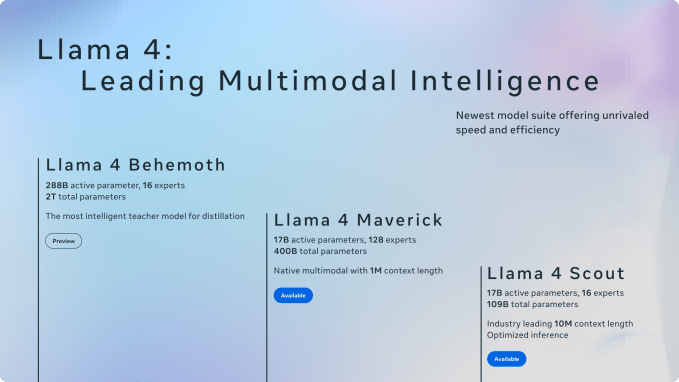
Llama 4 Scout: How 109B Parameters Fit on a Single H100 GPU
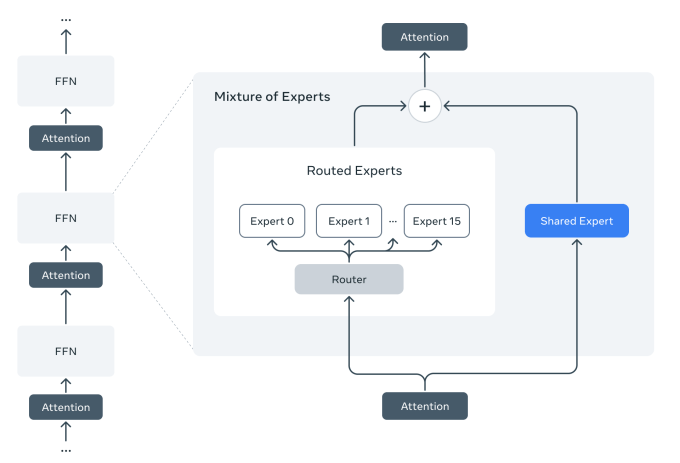
The magic behind Llama 4 Scout is its Mixture of Experts (MoE) architecture. Of its 109 billion total parameters, only 17 billion are active per token. The model contains 16 expert modules, and each token activates only a fraction of them, dramatically reducing compute requirements without sacrificing capability.
Here are the numbers that matter:
- Total parameters: 109B (16 experts)
- Active parameters: 17B (per token)
- Context window: Up to 10 million tokens (industry leading)
- Deployment: Fits on a single NVIDIA H100 with Int4 quantization
- Architecture: iRoPE — interleaved attention layers without positional embeddings
The iRoPE architecture deserves special attention. By placing attention layers without positional embeddings in an interleaved pattern and applying inference-time temperature scaling, Scout achieves exceptional length generalization. This is why it can extend to 10 million tokens despite being trained on a 256K context length — a feat that makes multi-document analysis and extensive activity log parsing genuinely practical.
From Llama 3.2 to Llama 4: The Edge AI Evolution
Meta’s on-device AI strategy didn’t appear overnight. It started at Meta Connect 2024 with Llama 3.2’s 1B and 3B lightweight models — the first highly capable Llama models built specifically for edge devices. Using pruning and distillation techniques, these text-only models supported 128K context tokens while running on smartphones.
Day-one optimization for Qualcomm, MediaTek, and Arm processors was a strategic move that paid off. These models delivered state-of-the-art performance for summarization, instruction following, and text rewriting tasks on mobile hardware. That technical foundation is what made Llama 4 Scout’s more ambitious on-device deployment possible.
The evolutionary leap becomes clear in comparison:
- Llama 3.2 (1B/3B): Text-only, smartphone-class, 128K context
- Llama 4 Scout (17B/109B MoE): Natively multimodal, GPU server-class, 10M context
- Common thread: Privacy-first local processing, open source/open weights
Ray-Ban Display + Neural Band: On-Device AI Gets Physical
Technology means nothing without hardware to run it on. The hardware stars of Meta Connect 2025 were the Meta Ray-Ban Display ($799) and the Meta Neural Band — Meta’s first smart glasses with an actual display, bundled with the company’s long-in-development sEMG (surface electromyography) wristband.
This is where the Llama 4 on-device AI connection becomes tangible. The Neural Band’s raw EMG data is processed entirely on-device. Only event-level information — a “click” gesture, for example — travels from the wristband to the glasses. Sensitive biometric data never reaches the cloud.
Current limitations are real. Continuous AI activity drains the battery in one to two hours, and “all-day support” remains a future goal pending improvements in battery technology and thermal management. But the direction is irreversible — AI is coming down from the cloud to your fingertips and your line of sight.
The On-Device AI Developer Ecosystem
Meta didn’t just release models and hardware. CTO Andrew Bosworth unveiled the Meta Wearables Device Access Toolkit, a suite of resources for developers to extend mobile apps and build hands-free experiences across Meta’s growing lineup of AI glasses. Horizon Studio now lets creators generate terrain, buildings, and NPCs through natural language prompts.
Both Llama 4 Scout and Maverick are available for download on llama.com and Hugging Face, with distribution expanding across cloud platforms, edge silicon providers, and service integrators. The open-weight strategy is clearly designed to build an edge AI ecosystem that no single company controls.
The On-Device AI Competitive Landscape: Apple, Google, and Qualcomm
Meta isn’t the only player in on-device AI. Apple is integrating Core ML-based on-device LLMs into iPhone, Google has deployed Gemini Nano on the Pixel series, and Qualcomm claims its Snapdragon 8 Gen 3 NPU can run models with up to 7 billion parameters.
But Meta’s approach is fundamentally different in four ways:
- Open weights: Fully open, unlike Apple (closed) or Google (partially open)
- Wearable-first: Smart glasses and bands as primary form factor, not smartphones
- MoE efficiency: 109B-scale intelligence at 17B compute cost
- 10M token context: Overwhelming advantage in long-term memory over competitors
From a producer and engineer’s perspective, the implications extend far beyond AI tools. Real-time translation, context-aware AI assistants, and privacy-guaranteed local processing — when these three converge, creative workflows from live performance to studio sessions could fundamentally change.
Conclusion: The Real On-Device AI Game Starts Now
What Meta Connect 2025 demonstrated wasn’t a tech demo — it was a clear roadmap. Pack large-model intelligence into small hardware with Llama 4 Scout’s MoE architecture. Establish the wearable form factor with Ray-Ban Display and Neural Band. Scale the ecosystem through open weights. A three-pronged strategy that’s hard to counter.
Battery life and thermal challenges remain unsolved, but the direction is irreversible. AI is migrating from cloud APIs to our pockets and to the bridge of our noses — and Llama 4 just marked the inflection point.
Interested in AI-powered music production pipelines or tech consulting? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}