
Apple HomePod 3 루머 총정리: 7인치 디스플레이와 Apple Intelligence가 바꿀 스마트홈의 미래
7월 21, 2025
PreSonus Eris E5 XT MkII 리뷰: 20만 원대 스튜디오 모니터의 진화, 5가지 핵심 변화 분석
7월 22, 2025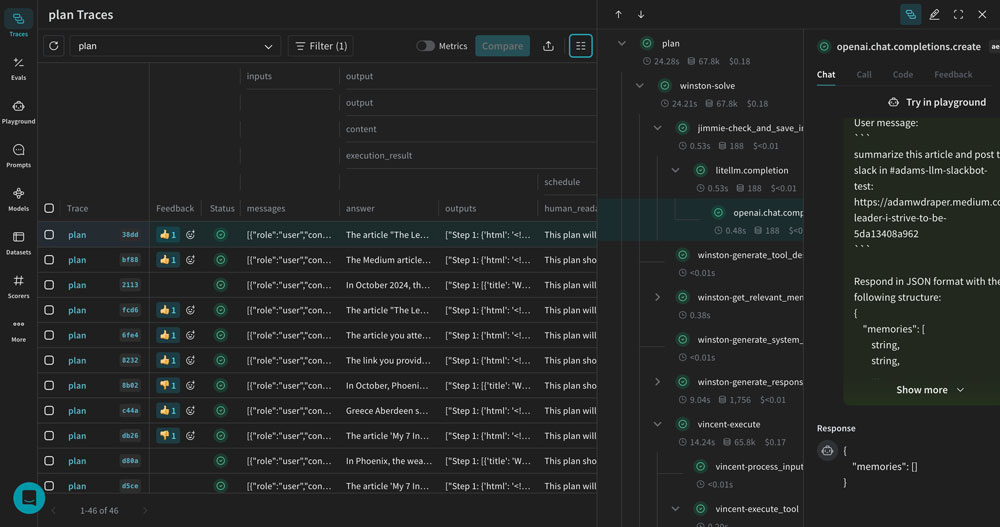
LLM 앱을 프로덕션에 배포한 뒤 “왜 이 응답이 나왔지?”라는 질문에 답하지 못한 경험, 한 번쯤 있으실 겁니다. 프롬프트를 수십 번 바꿔도 개선이 됐는지 퇴보했는지 감으로 판단하던 시절은 이제 끝날 수 있습니다. W&B Prompts와 Weave가 바로 그 문제를 정면으로 해결하고 있기 때문입니다.
Weights & Biases는 2025년 상반기 5,000만 달러 투자(기업가치 12.5억 달러)를 유치하면서 W&B Prompts를 전면에 내세웠습니다. 단순한 실험 추적 도구를 넘어, LLM 애플리케이션의 전체 라이프사이클—프롬프트 엔지니어링, 디버깅, 평가, 모니터링—을 하나의 플랫폼에서 관리할 수 있는 LLMOps 솔루션으로 진화한 것입니다. 이 글에서는 W&B Prompts 생태계의 핵심 구성 요소들을 실전 관점에서 분석하겠습니다.
W&B Prompts와 Weave: LLM 관측성의 새로운 기준
W&B Prompts의 핵심 엔진은 Weave입니다. Weave는 LLM 애플리케이션의 관측성(observability)과 평가를 위한 전용 플랫폼으로, 기존 ML 실험 추적 도구와는 근본적으로 다른 접근법을 취합니다.
가장 주목할 점은 @weave.op 데코레이터입니다. Python 함수에 이 데코레이터 하나만 붙이면 LLM 호출의 입력, 출력, 비용, 지연 시간이 자동으로 추적됩니다. 별도의 로깅 코드를 작성할 필요가 없습니다.
import weave
weave.init("my-llm-project")
@weave.op
def generate_response(prompt: str) -> str:
# OpenAI, Anthropic 등 어떤 LLM이든 자동 추적
return client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
).choices[0].message.content설치도 간단합니다. Python이라면 pip install weave, TypeScript라면 pnpm install weave 한 줄이면 됩니다. 이 간결한 시작점이 Weave의 가장 큰 강점 중 하나입니다. 복잡한 설정 없이 기존 코드에 바로 관측성을 추가할 수 있습니다.
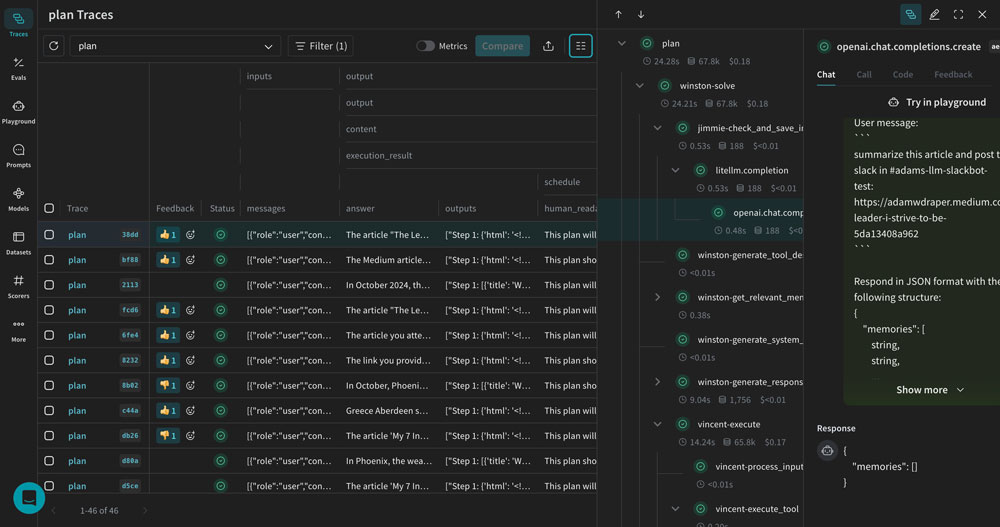
W&B Traces로 프롬프트 체인 디버깅하기
LLM 앱이 단일 프롬프트 호출로만 구성되던 시절은 지났습니다. RAG 파이프라인, 에이전트 체인, 멀티스텝 워크플로우가 표준이 된 2025년, 문제가 발생했을 때 “어디서 잘못됐는지”를 찾는 것은 점점 더 어려워지고 있습니다.
W&B Traces는 이 문제를 시각적 트레이스 디버깅으로 해결합니다. 프롬프트 체인의 각 단계—검색, 컨텍스트 조합, LLM 호출, 후처리—를 트리 구조로 시각화하여 중간 결과물을 단계별로 검사할 수 있습니다.
실제 프로덕션 환경에서 이 기능의 가치는 막대합니다. 예를 들어, RAG 시스템에서 잘못된 답변이 나왔을 때 원인이 검색 단계의 문서 선택 오류인지, 프롬프트 구성의 문제인지, LLM 자체의 환각인지를 트레이스 하나로 즉시 파악할 수 있습니다. 또한, 프롬프트와 LLM 체인 구성을 안전하게 관리하고 버전을 추적할 수 있어 팀 단위 협업에도 적합합니다.
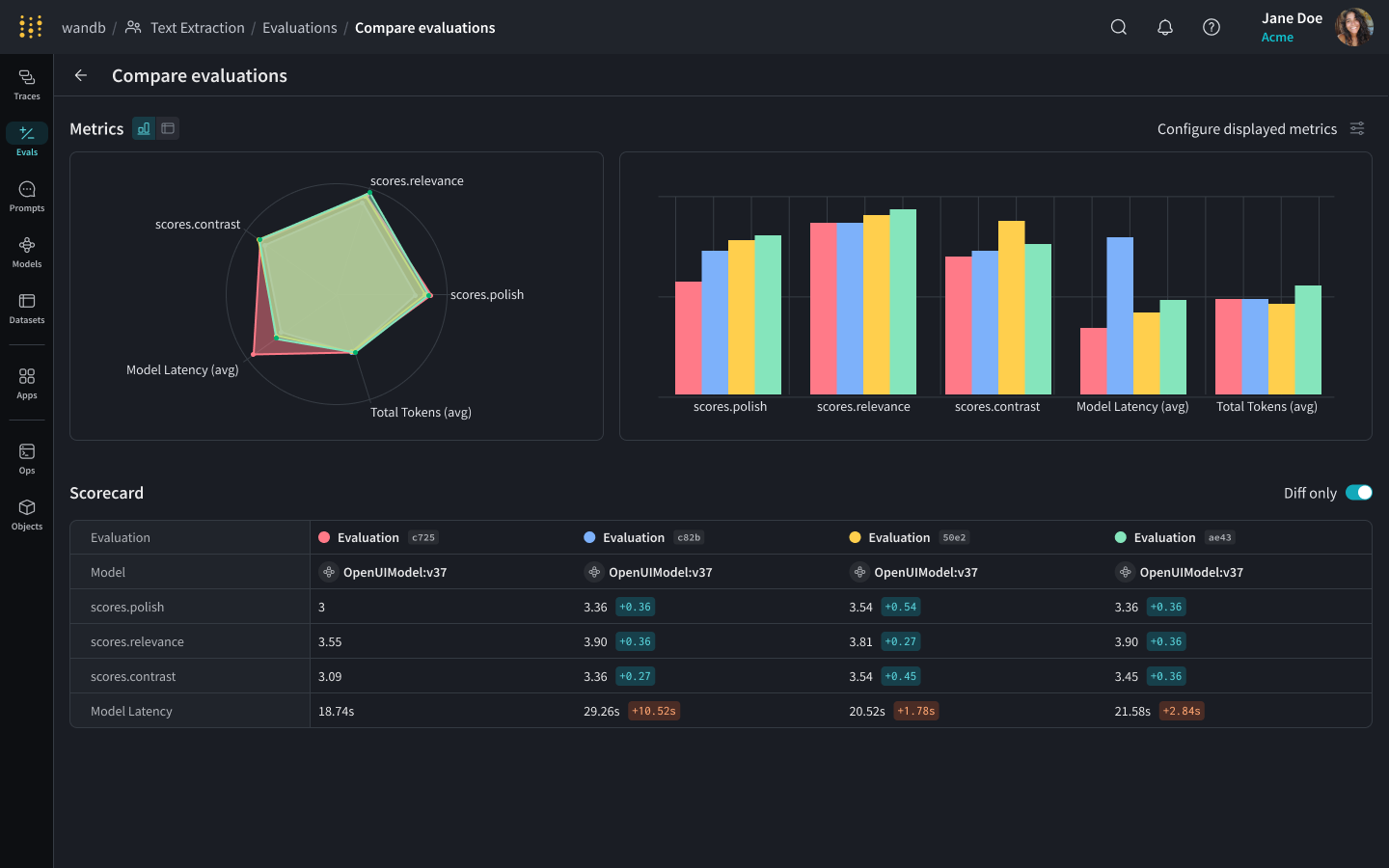
W&B Prompts 평가 시스템: LLM Judge와 커스텀 스코어러
프롬프트를 변경했을 때 “더 나아졌다”는 것을 어떻게 증명할 수 있을까요? 직감이 아닌 데이터로 답해야 합니다. W&B Evaluations는 체계적인 LLM 평가 프레임워크를 제공합니다.
핵심 기능은 세 가지입니다.
- LLM Judge: 다른 LLM을 평가자로 활용하여 응답의 정확성, 관련성, 안전성을 자동으로 채점합니다. 사람이 수천 건의 응답을 직접 검토할 수 없으니, LLM이 LLM을 평가하는 방식입니다.
- 커스텀 스코어러: 비즈니스 로직에 맞는 평가 기준을 직접 정의할 수 있습니다. 응답 길이, 특정 키워드 포함 여부, 형식 준수 등 도메인 특화 기준을 코드로 작성합니다.
- 리더보드: 모델, 프롬프트 버전, 파라미터 조합을 리더보드 형식으로 비교합니다. 정확도, 지연 시간, 비용을 한눈에 확인하며 최적의 조합을 찾을 수 있습니다.
특히 주목할 것은 온라인 평가(Online Evals) 기능입니다. 개발 단계의 오프라인 평가뿐 아니라, 프로덕션 환경에서 실시간으로 들어오는 응답을 지속적으로 모니터링할 수 있습니다. 모델 성능 저하를 조기에 감지하여 대응할 수 있는 것입니다.
OpenTelemetry 통합과 엔터프라이즈 확장성
W&B Prompts 생태계에서 2025년 가장 중요한 업데이트 중 하나는 OpenTelemetry(OTel) 통합입니다. 기존에는 Python과 JavaScript/TypeScript SDK로만 트레이스를 수집할 수 있었지만, OTel 통합으로 Go, Java, Rust 등 어떤 백엔드 언어에서든 트레이스 데이터를 W&B로 전송할 수 있게 되었습니다.
이는 엔터프라이즈 환경에서 특히 의미가 큽니다. 대규모 조직의 AI 시스템은 단일 언어로 구성되지 않습니다. Python으로 ML 파이프라인을 구축하고, Go로 API 서버를 운영하며, Java로 데이터 처리를 하는 것이 일반적입니다. OTel 통합 덕분에 이 모든 구성 요소에서 발생하는 LLM 관련 트레이스를 하나의 대시보드에서 관측할 수 있게 된 것입니다.
엔터프라이즈 확장성의 또 다른 증거는 AWS Bedrock AgentCore와의 통합입니다. Amazon Bedrock에서 실행되는 AI 에이전트에 W&B Weave를 엔터프라이즈급 관측성 레이어로 연결할 수 있어, AWS 인프라를 사용하는 기업들이 별도의 관측 시스템을 구축할 필요가 없습니다.
경쟁 플랫폼 비교: LangSmith, Arize Phoenix와 무엇이 다른가
LLM 관측성과 평가 플랫폼 시장은 빠르게 성장하고 있습니다. W&B Prompts의 포지셔닝을 이해하려면 주요 경쟁 제품과의 차이를 알아야 합니다.
LangSmith는 LangChain 생태계와 깊게 통합된 관측성 도구입니다. LangChain으로 앱을 만들었다면 가장 자연스러운 선택이지만, LangChain에 의존하지 않는 프로젝트에서는 활용도가 떨어집니다. W&B Prompts는 프레임워크에 구애받지 않는다는 점에서 더 넓은 유연성을 제공합니다. OpenAI, Anthropic, 로컬 모델 등 어떤 LLM을 사용하든 동일한 관측성을 확보할 수 있습니다.
Arize Phoenix는 오픈소스이며 OTel 네이티브라는 장점이 있습니다. 자체 인프라에 데이터를 보관하고 싶은 조직이나 커스터마이징이 중요한 팀에게 적합합니다. 다만, W&B가 제공하는 수준의 통합 평가 시스템(리더보드, 온라인 평가 등)과 엔터프라이즈 지원은 상대적으로 제한적입니다.
W&B Prompts의 가장 큰 차별점은 기존 ML 실험 관리 생태계와의 연속성입니다. 이미 W&B로 모델 학습을 추적하고 있는 팀이라면, 같은 플랫폼에서 프롬프트 엔지니어링과 LLM 평가까지 관리할 수 있다는 것은 운영 복잡성을 크게 줄여줍니다. 학습 실험에서 프로덕션 모니터링까지 하나의 도구 체인으로 커버할 수 있는 것입니다.
실전 도입 전략: W&B Prompts를 팀에 적용하는 방법
W&B Prompts를 도입할 때 가장 현실적인 접근법은 단계별 적용입니다.
1단계: 관측성 확보. 기존 LLM 호출에 @weave.op 데코레이터를 추가합니다. 이것만으로도 모든 호출의 입력/출력/비용/지연 시간을 자동으로 추적할 수 있습니다. 코드 변경은 최소화하면서 즉각적인 가시성을 확보하는 단계입니다.
2단계: 평가 체계 구축. 반복적인 프롬프트 수정 과정에 W&B Evaluations를 도입합니다. 골든 데이터셋을 준비하고, LLM Judge와 커스텀 스코어러로 프롬프트 변경의 영향을 정량적으로 측정합니다.
3단계: 프로덕션 모니터링. 온라인 평가를 활성화하여 프로덕션 환경의 응답 품질을 지속적으로 추적합니다. 성능 저하 알림을 설정하고, 트레이스 데이터를 기반으로 문제를 빠르게 진단합니다.
4단계: 팀 확장. 리더보드를 활용하여 팀 내 프롬프트 엔지니어링 실험 결과를 공유하고, W&B의 공식 문서의 RAG 평가 튜토리얼을 참고하여 고급 평가 파이프라인을 구축합니다.
LLM 애플리케이션이 프로토타입에서 프로덕션으로 넘어가는 2025년, “감”이 아닌 “데이터”로 프롬프트를 관리하는 것은 선택이 아닌 필수가 되고 있습니다. W&B Prompts는 그 전환을 가장 체계적으로 지원하는 플랫폼 중 하나입니다. 이미 ML 파이프라인에 Weights & Biases를 사용하고 있다면 Weave 도입은 자연스러운 다음 단계이고, 새로 시작하는 팀이라도 pip install weave 한 줄로 즉시 LLM 관측성을 확보할 수 있다는 점은 큰 매력입니다.
LLM 파이프라인 자동화나 AI 기반 시스템 구축에 관심이 있으시다면, Sean Kim이 도와드리겠습니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}