
NVIDIA RTX 5090 Ti 루머 총정리: GB202 풀 다이, 최대 36GB GDDR7, 600W+ TGP — 지금까지 알려진 모든 것
9월 23, 2025
비트메이킹에 Circle of Fifths 적용하기: 프로듀서가 알아야 할 코드 진행 트릭 5가지
9월 24, 2025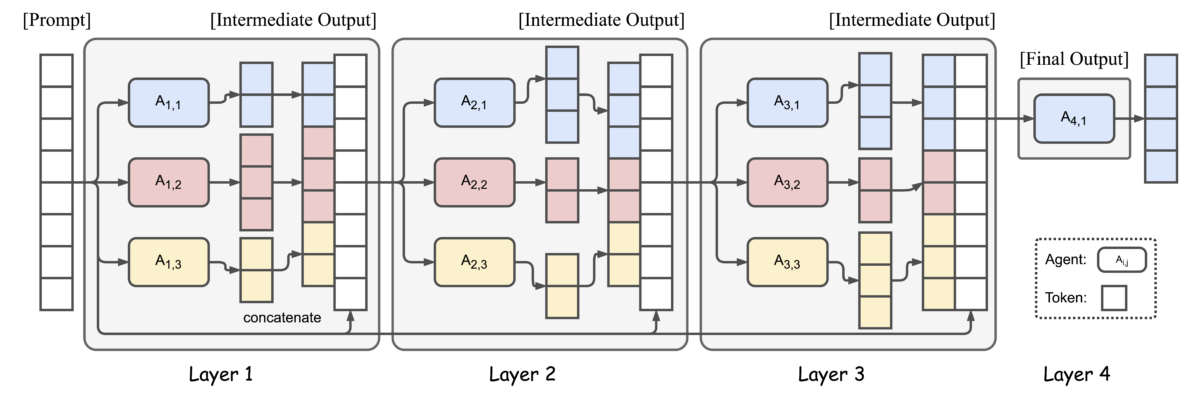
오픈소스 모델 6개를 합치니 GPT-4o를 넘었습니다. AlpacaEval 2.0에서 65.1% — GPT-4o의 57.5%를 7.6%p 차이로 제쳤습니다. Together AI의 Mixture of Agents(MoA)가 증명한 숫자입니다. 그리고 2025년 9월, Together AI는 이 기술을 뒷받침할 GPU 인프라까지 정식 출시하며 본격적인 엔터프라이즈 공략에 나섰습니다.
Together AI Mixture of Agents — 오픈소스 LLM 앙상블의 새로운 패러다임
MoA의 핵심 아이디어는 단순하지만 강력합니다. 하나의 거대 모델에 의존하는 대신, 여러 오픈소스 모델의 강점을 레이어별로 조합하는 것입니다. Together AI의 연구팀은 이를 Proposer-Aggregator 아키텍처로 구현했습니다.
Proposer(제안자)는 다양한 관점의 초기 응답을 생성합니다. WizardLM-2-8x22b, Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, Llama-3-70B-Chat, Mixtral-8x22B-Instruct, dbrx-instruct — 이 6개 모델이 동시에 같은 질문에 답합니다. 각 모델의 강점이 다르기 때문에 자연스럽게 다각적인 응답 풀이 형성됩니다.
Aggregator(종합자)는 이 모든 응답을 받아 하나의 최종 답변으로 통합합니다. 기본 구성에서는 Qwen1.5-110B-Chat이 이 역할을 맡습니다. 핵심은 “다음 레이어의 모든 에이전트가 이전 레이어의 모든 출력을 보조 정보로 활용”한다는 점입니다.
벤치마크가 말하는 Together AI Mixture of Agents 성능
- AlpacaEval 2.0: 65.1% (GPT-4o 57.5% 대비 +7.6%p)
- MT-Bench: 9.25±0.10 (GPT-4o 9.19 대비 소폭 우위)
- FLASK: 정확성, 사실성, 완전성 전 영역에서 GPT-4o 초과
- Arena-Hard: 최상위권 달성
주목할 점은 이 모든 성능이 100% 오픈소스 모델만으로 달성되었다는 것입니다. 개별적으로는 GPT-4o에 미치지 못하는 모델들이, 구조적 협업을 통해 폐쇄형 모델을 넘어섰습니다. Together AI 연구팀은 이 현상을 기초 논문에서 “collaborativeness(협업성)”라고 명명했는데, 개별 모델이 다른 모델의 출력을 보조 입력으로 받으면 단독 실행보다 유의미하게 더 나은 응답을 생성한다는 발견입니다.
MoA API 실전 활용: 개발자를 위한 구현 가이드
Together AI는 MoA를 단순한 연구 논문에 그치지 않고 프로덕션 API로 제공하고 있습니다. Chat Completions 엔드포인트를 통해 접근할 수 있으며, Python SDK로 쉽게 구현할 수 있습니다.
from together import AsyncTogether, Together
async_client = AsyncTogether()
client = Together()
reference_models = [
"Qwen/Qwen3.5-397B-A17B",
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
"deepseek-ai/DeepSeek-V3.1",
"mistralai/Mistral-Small-24B-Instruct-2501"
]
# 1단계: Proposer 병렬 호출
results = await asyncio.gather(*[
async_client.chat.completions.create(
model=model, messages=messages,
temperature=0.7, max_tokens=512
) for model in reference_models
])
# 2단계: Aggregator 통합
aggregated = client.chat.completions.create(
model="Qwen/Qwen3.5-397B-A17B",
messages=[{"role": "user", "content": combined_prompt}],
stream=True
)기본 2레이어 구성(4개 Proposer → 1개 Aggregator)부터 3레이어 이상의 고급 구성까지 유연하게 설정할 수 있습니다. AsyncTogether를 사용한 비동기 병렬 호출로 Proposer 단계의 지연 시간을 최소화하는 것이 실전 팁입니다.
MoAA: 앙상블 지능을 소형 모델에 증류하다 — ICML 2025
MoA의 한계도 분명합니다. 6개 모델을 동시에 돌리는 건 추론 비용과 지연 시간 면에서 부담이 큽니다. Together AI 연구팀은 이 문제를 Mixture-of-Agents Alignment(MoAA)로 해결했습니다. 2025년 ICML에서 발표된 이 논문의 핵심은 “MoA 앙상블의 집단 지능을 단일 소형 모델로 증류”하는 것입니다.
MoAA는 2단계로 작동합니다:
- MoAA-SFT: MoA 앙상블이 생성한 고품질 합성 데이터로 소형 모델을 지도 학습(Supervised Fine-Tuning)
- MoAA-DPO: MoA를 보상 모델로 활용한 Direct Preference Optimization으로 추가 정제
결과는 놀랍습니다. Llama-3.1-8B의 Arena-Hard 점수가 19.5에서 48.3으로 뛰었고, Gemma-2-9B은 42에서 55.6으로 향상되었습니다. 8B~9B 파라미터의 소형 모델이 자기보다 10배 큰 모델과 맞먹는 성능을 달성한 것입니다. 더구나 합성 데이터 생성 비용은 GPT-4o 대비 약 15% 저렴합니다.
가장 흥미로운 발견은 자기 개선 루프의 가능성입니다. MoA 앙상블에서 가장 강한 모델을 MoA가 생성한 데이터로 학습시켜도 성능이 향상된다는 것 — 외부의 더 큰 모델 없이도 자체적으로 개선되는 파이프라인이 가능하다는 의미입니다.
Instant Clusters GA: MoA를 위한 GPU 인프라가 완성되다
2025년 9월 9일, Together AI는 Instant Clusters의 정식 출시(General Availability)를 발표했습니다. 여름부터 베타 테스트를 거친 이 서비스는 MoA 같은 대규모 추론과 분산 학습을 위한 셀프서비스 GPU 인프라입니다.

GPU 옵션과 가격
NVIDIA Hopper부터 최신 Blackwell까지 지원합니다:
- HGX H100 Inference: $1.76~$2.39/GPU-hr (커밋먼트에 따라)
- HGX H100 SXM: $2.20~$2.99/GPU-hr
- HGX H200: $3.15~$3.79/GPU-hr
- HGX B200: $4.00~$5.50/GPU-hr
단일 노드(8 GPU)부터 수백 GPU의 멀티 노드 클러스터까지, API 한 줄로 몇 분 만에 프로비저닝됩니다. 기존에 수일이 걸리던 조달 과정을 분 단위로 단축한 것입니다. NVIDIA Quantum-2 InfiniBand 패브릭, NVLink, Kubernetes/Slurm 오케스트레이션이 기본 탑재됩니다.
개발자 친화적 기능
- Infrastructure-as-Code: Terraform, SkyPilot 통합 — 클러스터를 코드로 관리
- 에피소딕 학습: 클러스터를 재생성하면서 원래 데이터와 스토리지를 다시 마운트 — 간헐적 학습 워크로드에 최적
- 독립적 컴퓨팅/스토리지 확장: GPU와 스토리지를 별도로 스케일링
- 번인 테스트: 모든 노드에 NVLink/NVSwitch 검증, NCCL all-reduce 테스트 실행 후 배포
Together AI의 Chief Scientist Tri Dao는 “깨끗한 NVIDIA Hopper나 Blackwell GPU 클러스터를 좋은 네트워킹과 함께 몇 분 만에 띄울 수 있으면, 연구자들이 데이터, 모델 아키텍처, 시스템 설계, 커널에 더 많은 사이클을 쏟을 수 있다”고 설명했습니다.
9월 플랫폼 업데이트: 배치 API 3000배 확대와 새 모델들
Instant Clusters 외에도 9월에는 주목할 만한 플랫폼 업데이트가 쏟아졌습니다:
- Batch Inference API: 사용자당 모델별 큐 토큰 한도가 1000만에서 300억으로 3,000배 증가. 비용은 실시간 API의 50%
- 새 모델: Qwen3-Next-80B(사고형 + 명령형), Kimi-K2-Instruct-0905(Moonshot의 1T 파라미터 MoE 모델)
- 파인튜닝 확장: DeepSeek-V3.1, Qwen3-Coder-480B, Meta Llama-4 계열 지원 추가
- 스웨덴 데이터센터: 북유럽/중부유럽 대상 RTT 50~70ms 감소, 실시간 애플리케이션 응답 25~30% 개선
- 평가 도구: LoRA 및 Dedicated Endpoints의 평가 지원 추가
배치 API의 3000배 한도 확대는 특히 MoA 활용에 큰 의미가 있습니다. 여러 모델을 병렬로 호출하는 MoA 특성상, 대규모 배치 처리 시 비용 절감 효과가 극대화됩니다. 합성 데이터 생성, 오프라인 평가, 대량 콘텐츠 처리 같은 정확도 우선 워크로드에서 MoA + Batch API 조합은 강력한 선택지가 됩니다.
MoA vs 단일 모델: 언제 써야 하나?
MoA가 만능은 아닙니다. 레이어를 거칠수록 time-to-first-token 지연이 늘어나기 때문에, 실시간 채팅이나 스트리밍 응답이 중요한 서비스에는 부적합합니다. Together AI 자체도 이를 인정하고 최적화를 예고하고 있습니다.
MoA가 빛나는 시나리오:
- 오프라인 배치 처리: 대량 문서 분석, 합성 데이터 생성 — 지연 시간이 덜 중요한 곳
- 정확도 최우선 태스크: 법률 문서 검토, 의료 데이터 분석 — 단일 모델의 한계가 위험인 곳
- 모델 증류: MoAA로 소형 모델의 성능을 극대화한 뒤 프로덕션 배포 — 연구 단계에서 MoA, 실전에서 증류 모델
- 벤치마크/평가: 학습 데이터 품질 평가, 모델 비교 — MoA를 심판으로 활용
반면 실시간 채팅봇, 인터랙티브 코딩 어시스턴트처럼 지연 시간에 민감한 서비스라면 단일 모델이나 MoAA로 증류된 모델이 더 적합합니다.
오픈소스 AI 인프라의 미래를 보여주다
Together AI의 9월 업데이트는 단순한 제품 출시 이상의 메시지를 담고 있습니다. “오픈소스 모델의 구조적 협업이 폐쇄형 거대 모델을 넘을 수 있다”는 MoA의 증명과, 이를 프로덕션 레벨에서 운용할 수 있는 GPU 인프라의 결합 — 이것이 Together AI가 그리는 그림입니다.
MoAA로 앙상블의 지능을 소형 모델에 증류하는 기술까지 감안하면, “거대 모델 하나 vs 오픈소스 앙상블”이라는 구도는 더 이상 비용 대비 성능의 이분법이 아닙니다. 연구에서 MoA로 최적 응답을 찾고, MoAA로 프로덕션용 경량 모델을 만들고, Instant Clusters로 학습 인프라를 온디맨드로 확보하는 — 완전한 파이프라인이 갖춰진 셈입니다.
오픈소스 AI 모델이 단독으로는 폐쇄형 모델에 밀릴 때, “합치면 이긴다”는 전략의 기술적·인프라적 기반이 2025년 9월에 완성되었습니다. 그리고 이 전략은 앞으로 더 많은 모델이 등장할수록 더 강력해질 수밖에 없습니다.
MoA 같은 멀티 에이전트 AI 시스템이나 GPU 인프라 활용에 대해 더 알고 싶으시다면, 기술 컨설팅을 통해 구체적인 방향을 잡아드립니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}