10월 29, 2025Published by Sean Kim on 10월 29, 2025Categories 테크 & 하드웨어M4 Max AI 추론 벤치마크: Llama 70B 20 tok/s, 로컬 AI의 새로운 기준을 세우다700억 파라미터 언어 모델을 노트북에서 초당 20토큰으로 돌린다 — 클라우드 없이, GPU 서버랙 없이, 천만 원짜리 NVIDIA 카드 없이. M4 Max 맥북 프로가 실제 벤치마크에서 보여준 […]
8월 8, 2025Published by Sean Kim on 8월 8, 2025Categories AI 도구 & 서비스Claude Opus 4.1: SWE-bench 74.5% 달성, Anthropic 최강의 코딩 모델 분석3일 전, Anthropic이 플래그십 모델의 칼날을 한 번 더 갈았습니다. Claude Opus 4.1 — SWE-bench Verified 74.5%, 확장 사고 64K 토큰, 멀티파일 리팩토링 정밀도 향상. 숫자만 […]
6월 6, 2025Published by Sean Kim on 6월 6, 2025Categories AI 도구 & 서비스Claude 3.5 Sonnet 에이전틱 코딩: SWE-bench 49% 달성이 AI 개발 도구의 판도를 바꾼 1년실제 GitHub 이슈의 절반 가까이를 자율적으로 해결하는 AI 모델이 등장했을 때, 개발자 커뮤니티의 반응은 “정말 가능한 건가?”에서 “내 워크플로우에 어떻게 적용하지?”로 빠르게 바뀌었습니다. Claude 3.5 Sonnet […]
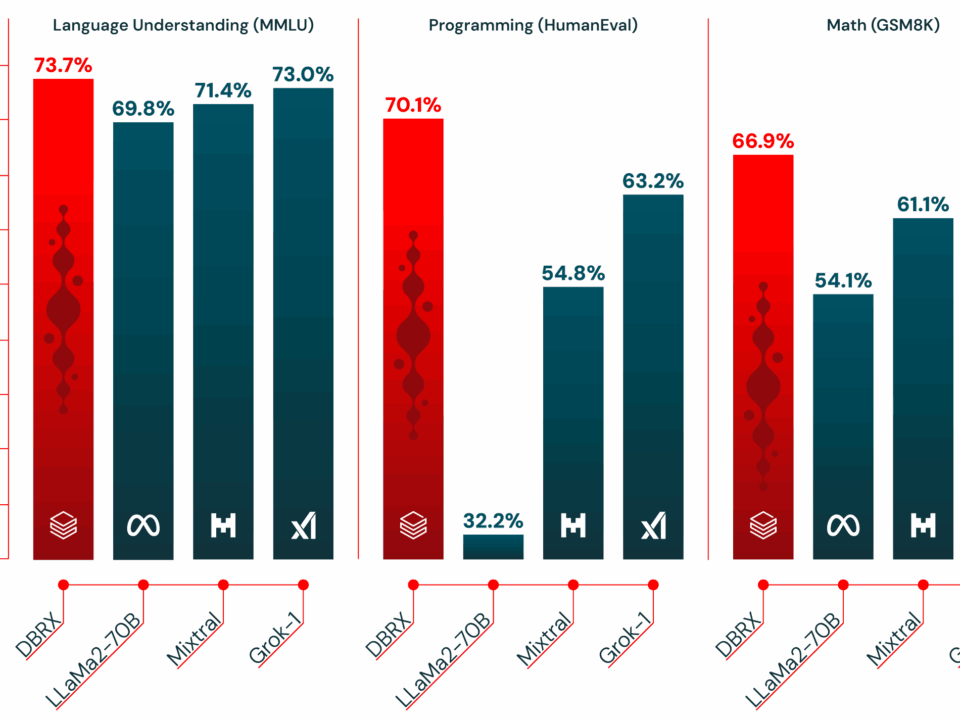
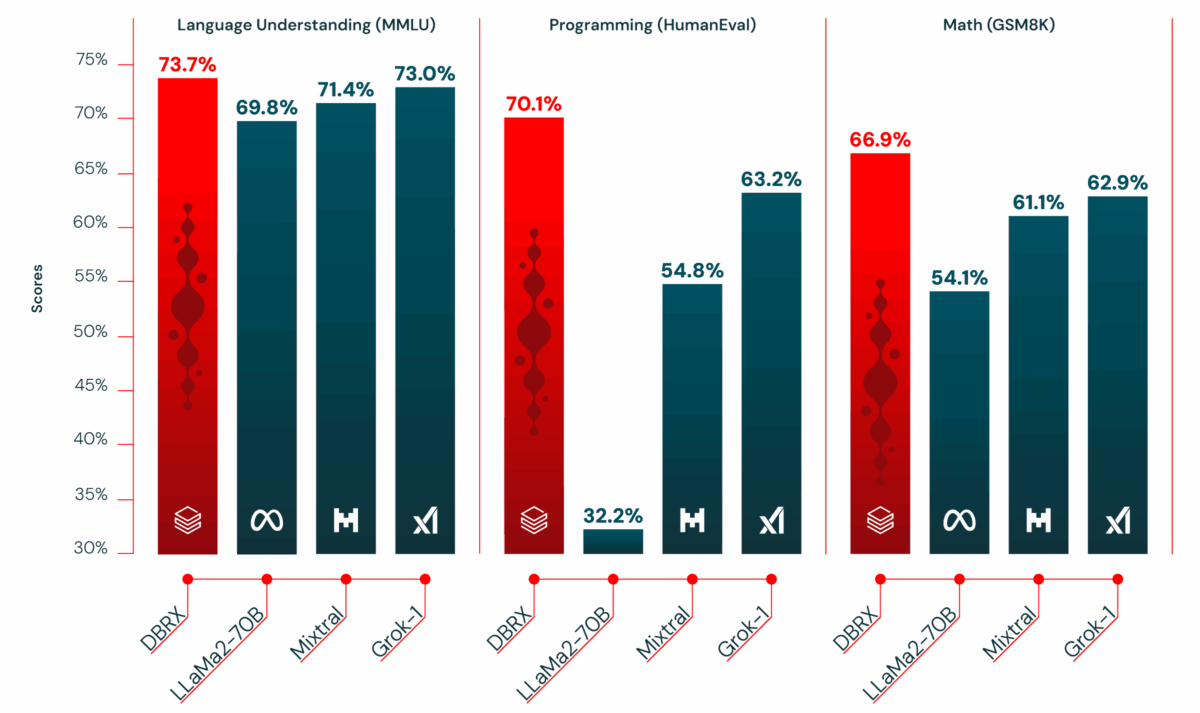
5월 28, 2025Published by Sean Kim on 5월 28, 2025Categories AI 도구 & 서비스Databricks DBRX: 36B 활성 파라미터로 70B 모델을 압도한 132B MoE의 진짜 실력132B 파라미터 모델이 36B만 켜고도 70B 모델을 이긴다면 믿으시겠습니까? Databricks DBRX가 정확히 그 일을 해냈습니다. 2024년 3월 출시 이후 1년이 지난 지금, 이 모델이 엔터프라이즈 AI […]
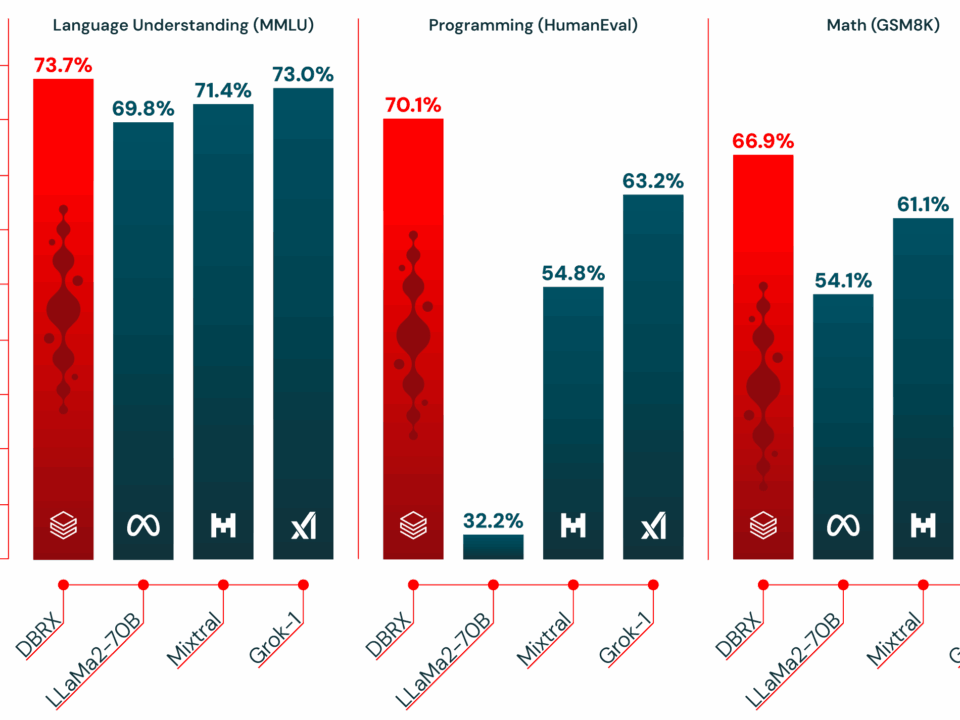
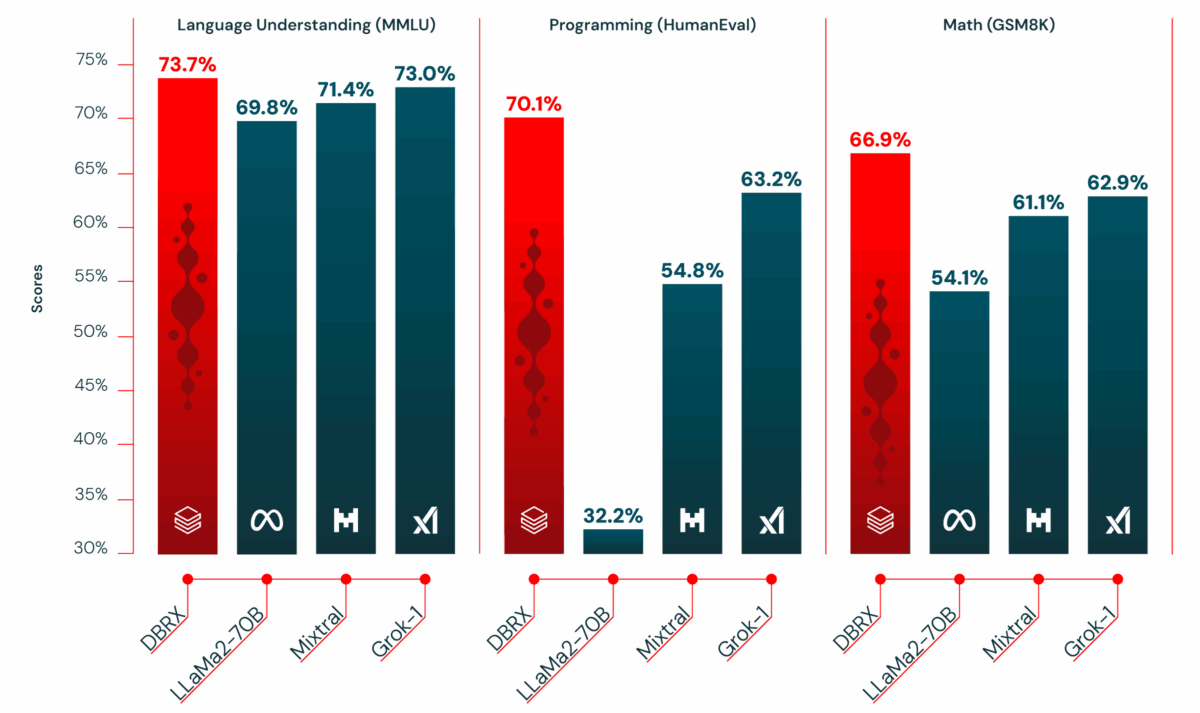
5월 28, 2025Published by Sean Kim on 5월 28, 2025Categories AI 도구 & 서비스Databricks DBRX: 36B 활성 파라미터로 70B 모델을 압도한 132B MoE의 진짜 실력132B 파라미터 모델이 36B만 켜고도 70B 모델을 이긴다면 믿으시겠습니까? Databricks DBRX가 정확히 그 일을 해냈습니다. 2024년 3월 출시 이후 1년이 지난 지금, 이 모델이 엔터프라이즈 AI […]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}