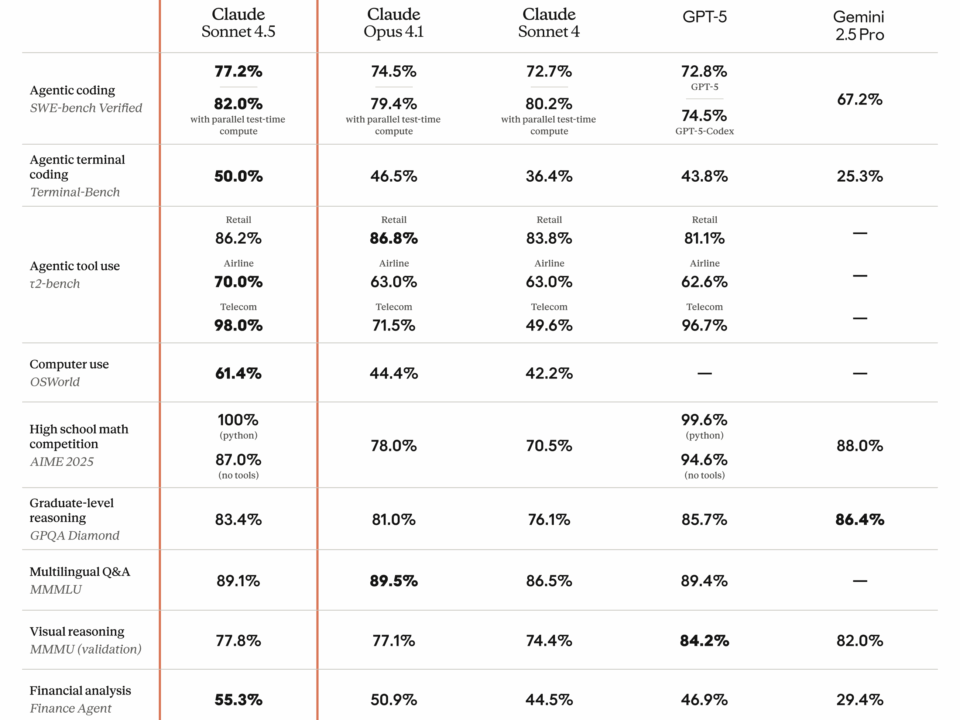
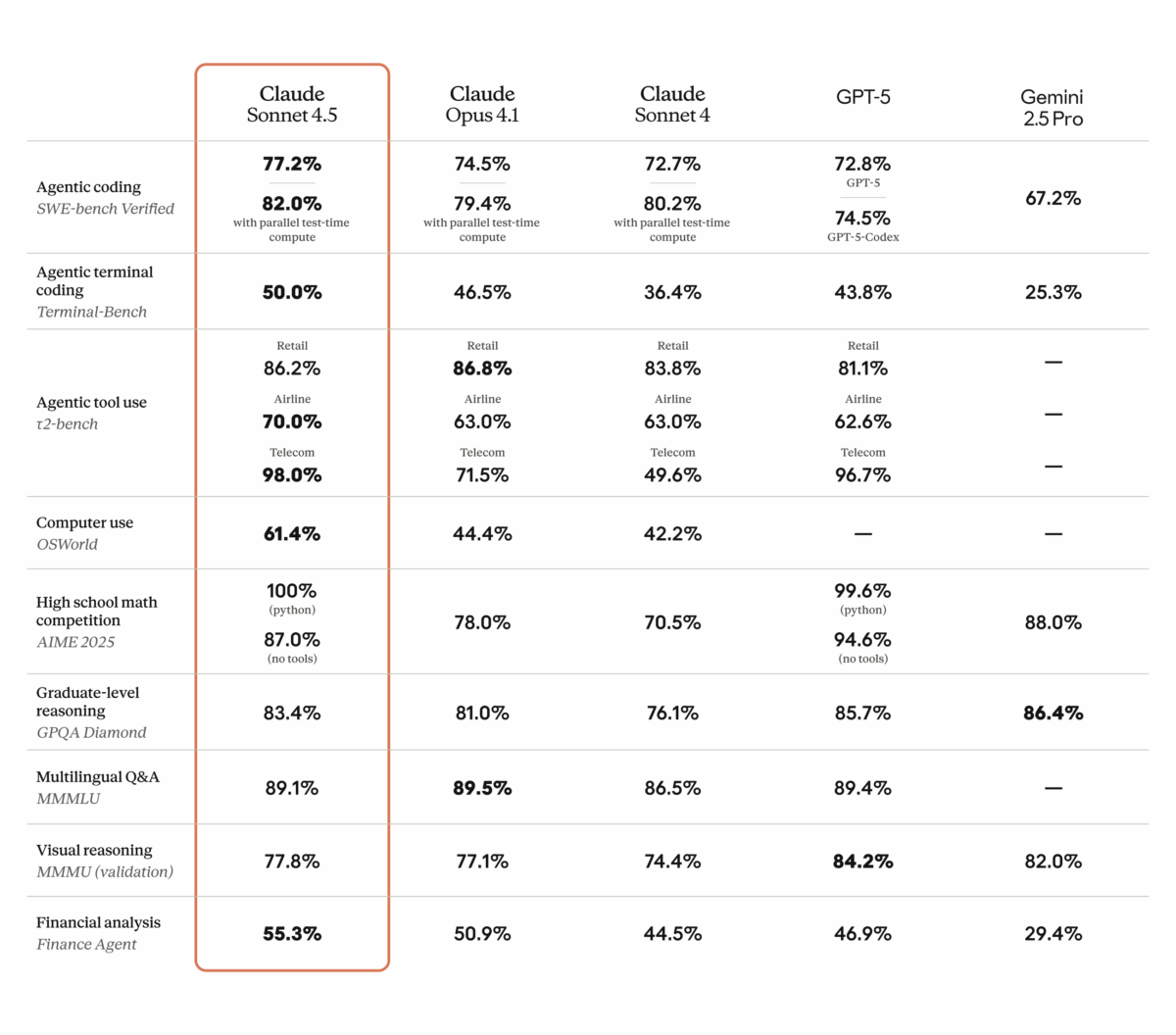
9월 2, 2025Published by Sean Kim on 9월 2, 2025Categories AI 도구 & 서비스Claude Sonnet 4.5 벤치마크 심층 분석: SWE-bench 77.2%로 GPT-5를 넘었다SWE-bench 77.2%. 이 숫자 하나가 2025년 AI 코딩 모델 시장의 판도를 완전히 뒤집었습니다. Anthropic이 내놓은 Claude Sonnet 4.5 벤치마크 결과는 단순한 업그레이드가 아니라, 미드티어 모델이 플래그십을 […]
8월 8, 2025Published by Sean Kim on 8월 8, 2025Categories AI 도구 & 서비스Claude Opus 4.1: SWE-bench 74.5% 달성, Anthropic 최강의 코딩 모델 분석3일 전, Anthropic이 플래그십 모델의 칼날을 한 번 더 갈았습니다. Claude Opus 4.1 — SWE-bench Verified 74.5%, 확장 사고 64K 토큰, 멀티파일 리팩토링 정밀도 향상. 숫자만 […]

{kind=link}
{kind=link}