3월 19, 2026Published by Sean Kim on 3월 19, 2026Categories 테크 & 하드웨어NVIDIA Groq 3 LPU 완전 분석: 칩당 500MB SRAM, 150 TB/s 대역폭으로 AI 추론 판도를 바꾼다칩 하나에 500MB SRAM. GPU가 아닌 전용 추론 프로세서가 NVIDIA 플랫폼에 합류했습니다. GTC 2026에서 공개된 NVIDIA Groq 3 LPU는 지금까지 우리가 알던 AI 추론의 공식을 완전히 […]
3월 3, 2026Published by Sean Kim on 3월 3, 2026Categories AI 도구 & 서비스NVIDIA GTC 2026 프리뷰: NIM 마이크로서비스와 NemoClaw가 엔터프라이즈 AI를 바꾸는 5가지 이유추론 비용이 10분의 1로 떨어진다고요? NVIDIA GTC 2026이 3월 16일부터 산호세에서 열립니다. 올해 핵심은 하드웨어가 아닙니다 — NIM 마이크로서비스, NemoClaw 에이전트 플랫폼, 그리고 AI Enterprise 5.0이 […]
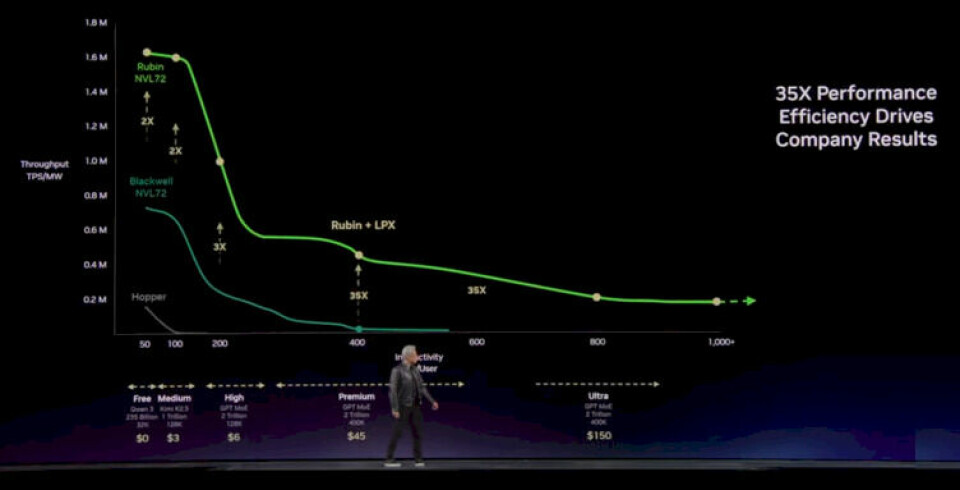
3월 2, 2026Published by Sean Kim on 3월 2, 2026Categories 테크 & 하드웨어NVIDIA 베라 루빈 아키텍처: 3,360억 트랜지스터로 블랙웰을 5배 뛰어넘다 — GTC 2026 프리뷰3,360억 개의 트랜지스터. 50 PFLOPS 추론 성능. 추론 토큰 비용 10분의 1. NVIDIA 베라 루빈 아키텍처가 CES 2026에서 공개된 순간, AI 반도체의 기준이 완전히 바뀌었습니다. 블랙웰이 […]
10월 29, 2025Published by Sean Kim on 10월 29, 2025Categories 테크 & 하드웨어M4 Max AI 추론 벤치마크: Llama 70B 20 tok/s, 로컬 AI의 새로운 기준을 세우다700억 파라미터 언어 모델을 노트북에서 초당 20토큰으로 돌린다 — 클라우드 없이, GPU 서버랙 없이, 천만 원짜리 NVIDIA 카드 없이. M4 Max 맥북 프로가 실제 벤치마크에서 보여준 […]
7월 29, 2025Published by Sean Kim on 7월 29, 2025Categories 프로그래밍 & 개발Modal Labs GPU 클라우드: 서버리스 AI 추론으로 AWS 대비 50% 비용 절감숫자 하나만 보겠습니다. 추론 요청 100건, 각 2초, 총 비용 $0.06. 같은 작업을 AWS에서 돌리면? $1.10입니다. GPU가 일하든 놀든 시간 단위로 과금되니까요. Modal Labs GPU 클라우드는 […]
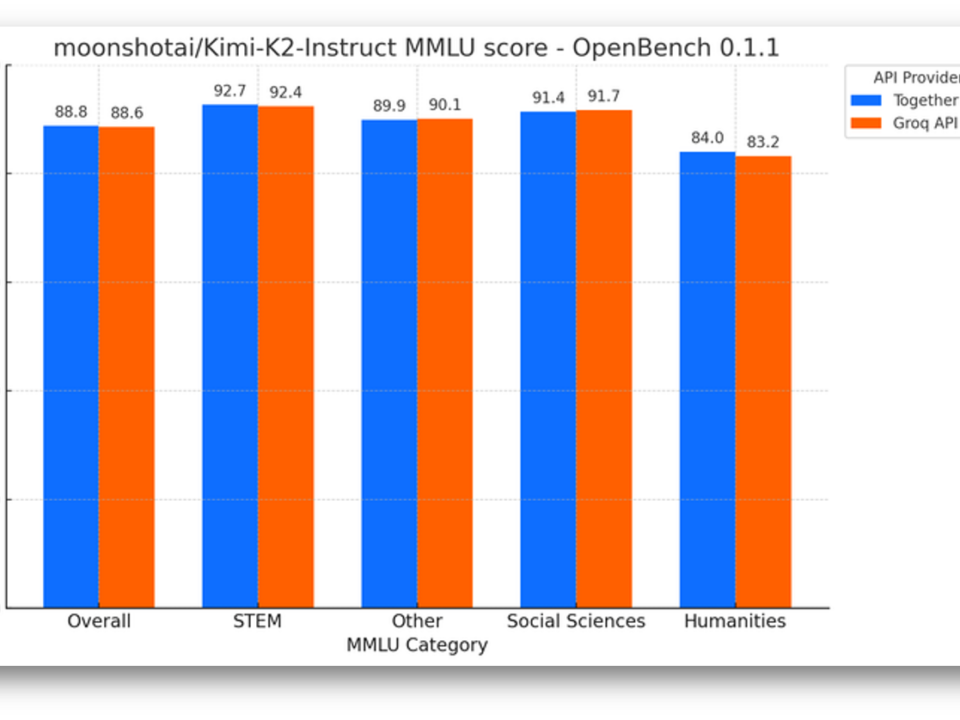
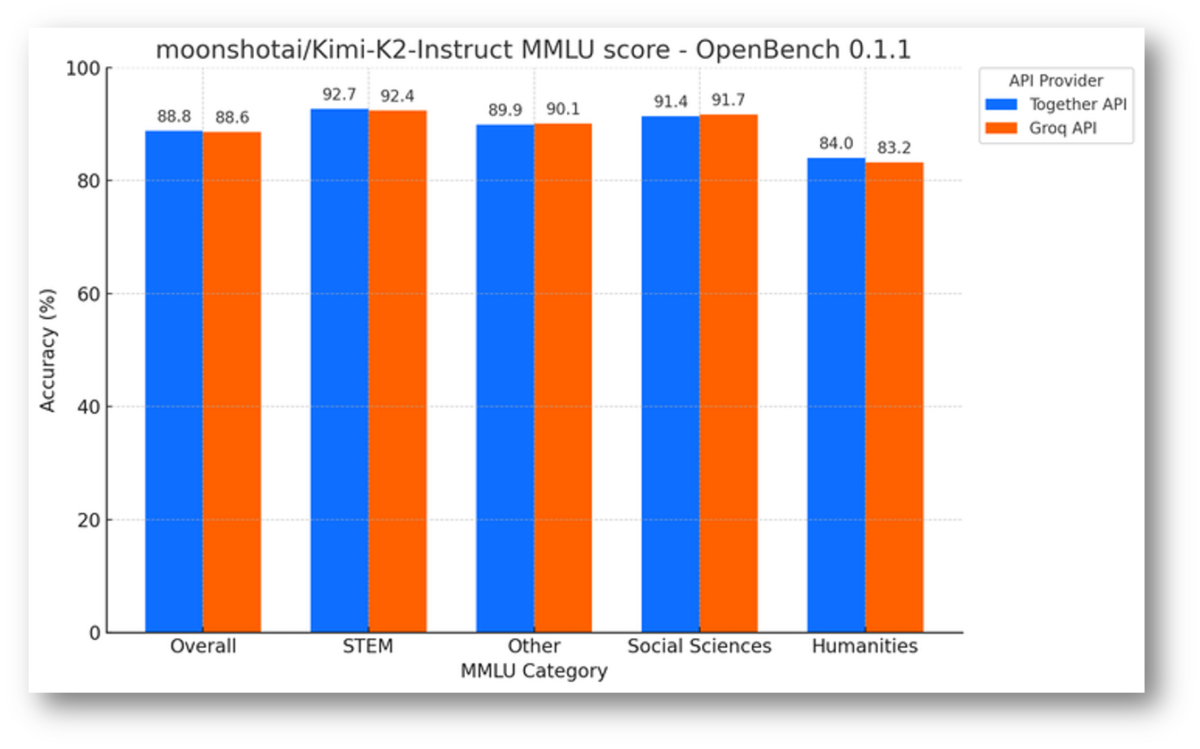
5월 27, 2025Published by Sean Kim on 5월 27, 2025Categories 산업 뉴스Groq LPU 추론, 초당 500 토큰 돌파: NVIDIA GPU 독점에 도전하는 추론 전용 칩의 부상초당 625 토큰. 오타가 아닙니다. 이름 없는 연구실의 합성 벤치마크도 아닙니다. Meta의 Llama 모델을 프로덕션 환경에서 돌리는 Groq LPU 추론 엔진의 실제 수치입니다. NVIDIA의 최신 H100 […]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}