
애플 맥북 프로 M5 Pro vs M5 Max: 어떤 구성을 선택해야 할까?
10월 31, 2025
블랙 프라이데이 2025 플러그인 딜 총정리: 뮤직 프로듀서를 위한 완벽 구매 가이드
11월 3, 2025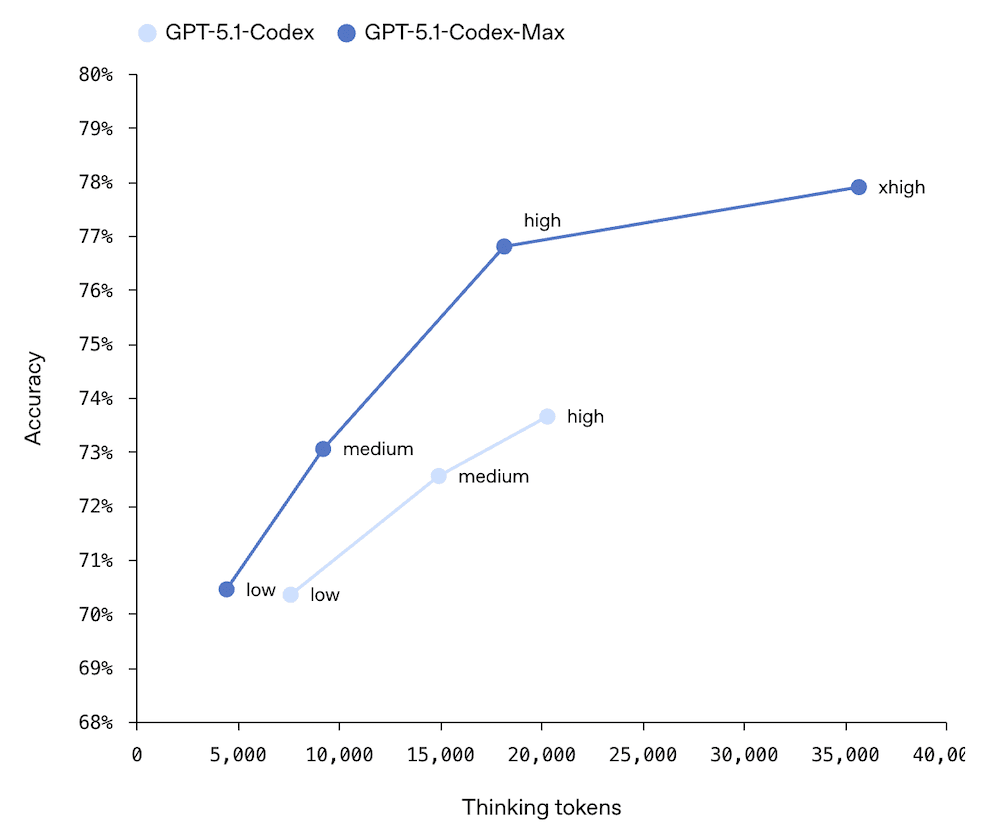
450밀리초. GPT-5.1 출시 이후 API 응답 중간값(p50)입니다. GPT-5 대비 83%나 빨라졌습니다. 블랙프라이데이를 앞두고 2026년 AI 스택을 고민하는 개발자라면, 이 숫자가 의미하는 바를 정확히 알아야 합니다.
2025년 11월 12일, OpenAI가 GPT-5.1을 정식 출시했습니다. 단순한 버전 업이 아닙니다. Instant, Thinking, Codex-Max 세 가지 변형 모델, 적응형 추론 파라미터, 24시간 확장 프롬프트 캐싱까지 — 이번 업데이트는 “프로덕션 환경에서 실제로 쓸 수 있는 AI”를 정면으로 겨냥하고 있습니다. 제가 직접 API를 테스트하면서 확인한 핵심 변화들을 정리합니다.
GPT-5.1 출시 핵심: 세 가지 모델 변형
GPT-5.1은 하나의 모델이 아닙니다. 용도에 따라 최적화된 세 가지 변형이 동시에 출시되었습니다. 기존 GPT-5가 범용 단일 모델이었다면, GPT-5.1은 워크로드별 전문화 전략으로 방향을 전환한 것입니다.
GPT-5.1 Instant는 빠른 응답이 필요한 실시간 서비스용입니다. 적응형 추론(adaptive reasoning)으로 요청의 복잡도에 따라 자동으로 연산 리소스를 조절합니다. 단순한 “날씨 알려줘” 같은 요청에는 최소한의 리소스만 사용하고, 복잡한 분석이 필요한 질문에는 더 많은 연산을 투입합니다. 챗봇, 고객 상담 에이전트, 실시간 추천 시스템 등에서 비용 효율성과 응답 속도를 동시에 확보할 수 있습니다.
GPT-5.1 Thinking은 심층 추론이 필요한 작업에 특화되었습니다. reasoning_effort 파라미터를 xhigh 레벨까지 올릴 수 있으며, 복잡한 수학·과학 문제, 다단계 논리 추론에서 압도적 성능을 보여줍니다. AIME 2025 수학 올림피아드에서 94.0%를 기록한 것이 이 모델의 성능을 단적으로 보여줍니다.
GPT-5.1 Codex-Max는 코딩 전용 모델입니다. 에이전틱 워크플로우를 위한 apply_patch와 shell 도구가 내장되어 있어, 코드 수정과 터미널 명령 실행을 모델이 직접 수행합니다. GitHub 이슈를 받아서 코드를 수정하고, 테스트를 실행하고, PR을 생성하는 전 과정을 자동화할 수 있는 수준입니다.
특히 주목할 점은 모드 간 자동 라우팅(auto-routing) 기능입니다. 개발자가 직접 모델을 선택하지 않아도 요청의 복잡도에 따라 최적의 변형을 자동 배정합니다. 하나의 API 엔드포인트로 다양한 워크로드를 처리할 수 있어, 프로덕션 환경에서의 운영 부담이 크게 줄어드는 부분입니다.

지연시간 83% 감소 — 숫자로 보는 GPT-5.1 성능 혁신
프로덕션 API에서 지연시간(latency)은 사용자 경험을 좌우하는 핵심 지표입니다. GPT-5.1의 지연시간 벤치마크는 놀라운 수준입니다.
- p50 (중간값): 450ms — GPT-5 대비 83% 감소
- p95 (상위 5%): 1.2초 — 안정적인 꼬리 지연시간(tail latency)
- 투기적 디코딩(speculative decoding): 기본 성능 위에 추가 2배 속도 향상
이 수치가 왜 중요한지 구체적으로 생각해보겠습니다. AI 에이전트가 하나의 사용자 요청을 처리하면서 10번의 순차적 도구 호출을 한다고 가정합니다. GPT-5 기준으로는 호출당 약 2.6초, 총 26초가 걸렸습니다. GPT-5.1에서는 호출당 450ms, 총 4.5초로 줄어듭니다. 사용자 체감 속도가 완전히 다른 차원입니다.
실제 사례도 나왔습니다. AI 고객 서비스 플랫폼 Sierra는 GPT-5.1 도입 후 저지연 도구 호출(low-latency tool calling)에서 20% 개선을 달성했습니다. 챗봇이나 실시간 에이전트를 운영하는 팀이라면, 이 수치는 직접적인 비용 절감과 사용자 만족도 향상으로 이어집니다. 특히 고객 이탈률이 응답 지연과 직결되는 SaaS 서비스에서는 체감 효과가 큽니다.
적응형 추론과 24시간 프롬프트 캐싱 — 비용 최적화의 핵심
GPT-5.1 출시에서 가장 실용적인 두 가지 기능이 바로 적응형 추론(adaptive reasoning)과 확장 프롬프트 캐싱입니다. 둘 다 프로덕션 비용에 직접적인 영향을 주는 기능입니다.
적응형 reasoning_effort 파라미터
reasoning_effort 파라미터는 none, low, medium, high, xhigh 다섯 단계로 모델의 추론 깊이를 직접 제어할 수 있게 해줍니다. 실제 프로덕션 파이프라인을 예로 들면 이렇습니다.
- 고객 문의 분류 (스팸/일반/긴급) → reasoning_effort: low
- 일반 응답 생성 (FAQ 기반) → reasoning_effort: medium
- 복잡한 기술 지원 (코드 디버깅 가이드) → reasoning_effort: high
- 법률/규정 관련 답변 (정확성 최우선) → reasoning_effort: xhigh
GPT-5에서는 모든 요청에 동일한 연산을 투입해야 했습니다. GPT-5.1에서는 요청별로 비용과 속도를 세밀하게 최적화할 수 있어, 대량 처리 환경에서 40-60% 수준의 비용 절감이 가능합니다.
24시간 확장 프롬프트 캐싱
프롬프트 캐싱은 반복적인 시스템 프롬프트나 컨텍스트를 24시간 동안 캐싱하여, 캐시 히트 시 입력 토큰 비용을 대폭 줄여줍니다.
- 미캐시 입력: 100만 토큰당 $1.25
- 캐시 히트 입력: 100만 토큰당 $0.125 — 90% 절감
구체적인 비용 절감 시나리오를 계산해보겠습니다. 하루 10만 건의 API 호출을 처리하는 서비스에서 시스템 프롬프트가 2,000토큰이라면, 미캐시 기준 시스템 프롬프트 비용만 하루 $250입니다. 캐싱을 활용하면 $25로 줄어듭니다. 월 기준으로 약 $6,750의 차이가 발생합니다. 시스템 프롬프트를 표준화하고 캐시 히트율을 극대화하는 것만으로도 상당한 비용 절감이 가능합니다.
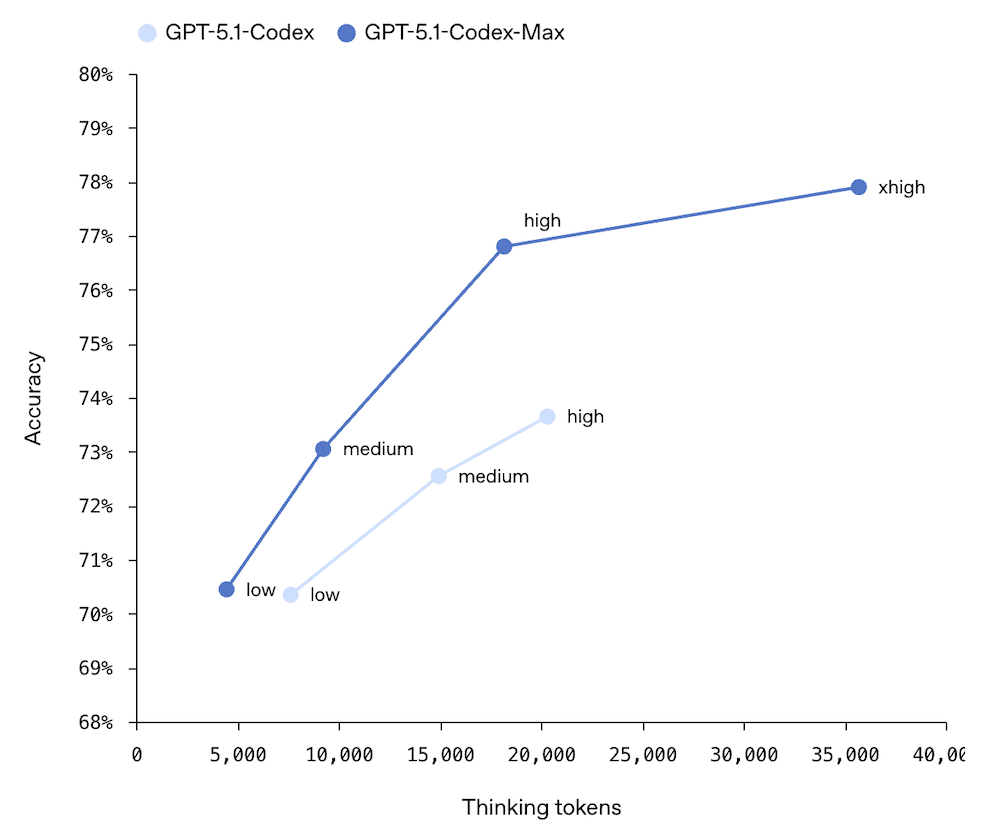
벤치마크와 컨텍스트 윈도우: GPT-5 대비 구체적 향상
주요 벤치마크 결과를 정리하면 다음과 같습니다.
- SWE-bench: 76.3% (GPT-5: 72.8%) — 소프트웨어 엔지니어링 작업에서 3.5%p 향상
- GPQA Diamond: 88.1% — 대학원 수준 과학 질문 정확도
- AIME 2025: 94.0% — 수학 올림피아드급 문제 해결력
벤치마크 점수 자체는 GPT-5 대비 소폭 상승이지만, SWE-bench 3.5%p 향상은 실제 GitHub 이슈 해결 능력의 개선을 의미하므로 실무에서 체감되는 차이가 큽니다. Codex-Max의 apply_patch와 shell 도구와 결합하면, 코드 에이전트로서의 실용성이 한 단계 올라갑니다.
컨텍스트 윈도우는 400K 토큰으로 확장되었고, 최대 출력은 128K 토큰까지 지원합니다. 장시간 실행되는 에이전틱 작업에서는 compaction(압축) 기능이 자동으로 오래된 컨텍스트를 요약하여 윈도우를 효율적으로 관리합니다. 기존에 긴 대화나 대규모 코드베이스 분석에서 겪던 컨텍스트 초과 문제가 상당 부분 해소되는 셈입니다.
또한 response styles 커스터마이징 기능이 추가되어, 모델의 출력 스타일을 더 세밀하게 제어할 수 있습니다. 기술 문서와 마케팅 카피를 같은 모델로 생성하되 톤과 형식을 다르게 지정할 수 있어, 멀티 채널 콘텐츠 생성 파이프라인에서 유용합니다.
가격 정책과 블랙프라이데이 시즌 개발자 전략
GPT-5.1의 API 가격은 입력 100만 토큰당 $1.25, 출력 100만 토큰당 $10입니다. 프롬프트 캐싱을 활용하면 반복 입력은 $0.125까지 내려갑니다.
블랙프라이데이 시즌을 맞아 많은 개발 팀이 2026년 AI 인프라를 재검토하고 있습니다. 클라우드 크레딧 할인과 연말 예산 집행 시기가 겹치는 지금, GPT-5.1 도입을 평가하기에 최적의 타이밍입니다.
구체적인 실행 전략을 정리하면 다음과 같습니다.
- 기존 GPT-5 파이프라인 A/B 테스트: 83% 지연시간 감소가 실제 워크로드에서 어떻게 반영되는지 측정. 특히 순차 도구 호출이 많은 에이전트 워크플로우에서 효과가 극대화됩니다.
- reasoning_effort 최적화 맵 작성: 모든 API 호출 유형을 분류하고, 각각에 적절한 reasoning_effort 레벨을 매핑. medium을 기본값으로 시작하여 품질 메트릭 기반으로 조정합니다.
- 프롬프트 캐싱 전략 수립: 시스템 프롬프트를 표준화하고 캐시 히트율을 추적. 동일한 시스템 프롬프트를 여러 요청 유형에서 재활용할 수 있도록 프롬프트 아키텍처를 재설계합니다.
- Codex-Max 에이전트 프로토타입: apply_patch + shell 기반의 자동화 워크플로우를 CI/CD 파이프라인에 통합하는 PoC를 구축합니다.
- 자동 라우팅 vs 수동 라우팅 비교: 1주일간 자동 라우팅을 사용한 후 비용과 품질을 수동 라우팅과 비교하여 최적 전략을 결정합니다.
GPT-5.1은 “더 똑똑한 AI”보다 “더 쓸 수 있는 AI”에 초점을 맞춘 업데이트입니다. 벤치마크 점수의 소폭 상승보다는, 지연시간 83% 감소·적응형 비용 최적화·24시간 캐싱·에이전틱 도구 같은 프로덕션 기능에서 본질적인 차이가 나타납니다. 2026년을 준비하는 개발 팀이라면 지금이 평가를 시작할 적기입니다.
AI API 통합, 자동화 파이프라인 구축, 또는 프로덕션 환경 최적화에 대한 기술 컨설팅이 필요하시다면 편하게 연락 주세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}