
Framework Laptop 16 AMD Radeon Edition 리뷰: 모듈형 게이밍 노트북의 새로운 기준
6월 25, 2025
여름 프로덕션 챌린지: 1시간 안에 곡 완성하기 — 템플릿, 워크플로우 팁, 60분 법칙
6월 26, 2025
매달 AI API에 20만 원 이상 지출하고 계신가요? 2025년 6월, 오픈소스 LLM 셀프호스팅 2025는 완전히 새로운 국면에 접어들었습니다. Meta의 Llama 4 Scout는 GPU 한 장에 1,000만 토큰 컨텍스트 윈도우를 제공하고, DeepSeek R1은 MIT 라이선스로 OpenAI o1급 추론 능력을 무료로 쓸 수 있게 해주며, Microsoft의 14B Phi-4는 자기보다 5배 큰 모델을 이깁니다. 이제 AI 인텔리전스를 빌려 쓰는 시대는 선택사항이 되었습니다.
비용 절감만이 이유가 아닙니다. 셀프호스팅은 데이터가 서버를 떠나지 않는다는 뜻입니다. 프롬프트가 다른 회사의 모델을 훈련시키지 않습니다. 레이턴시는 API 큐 대기 시간 없이 밀리초 단위로 줄어듭니다. Ollama와 vLLM 같은 도구들이 빠르게 성숙하면서, 프로덕션급 LLM을 구동하는 데 몇 달이 아니라 몇 분이면 충분합니다.
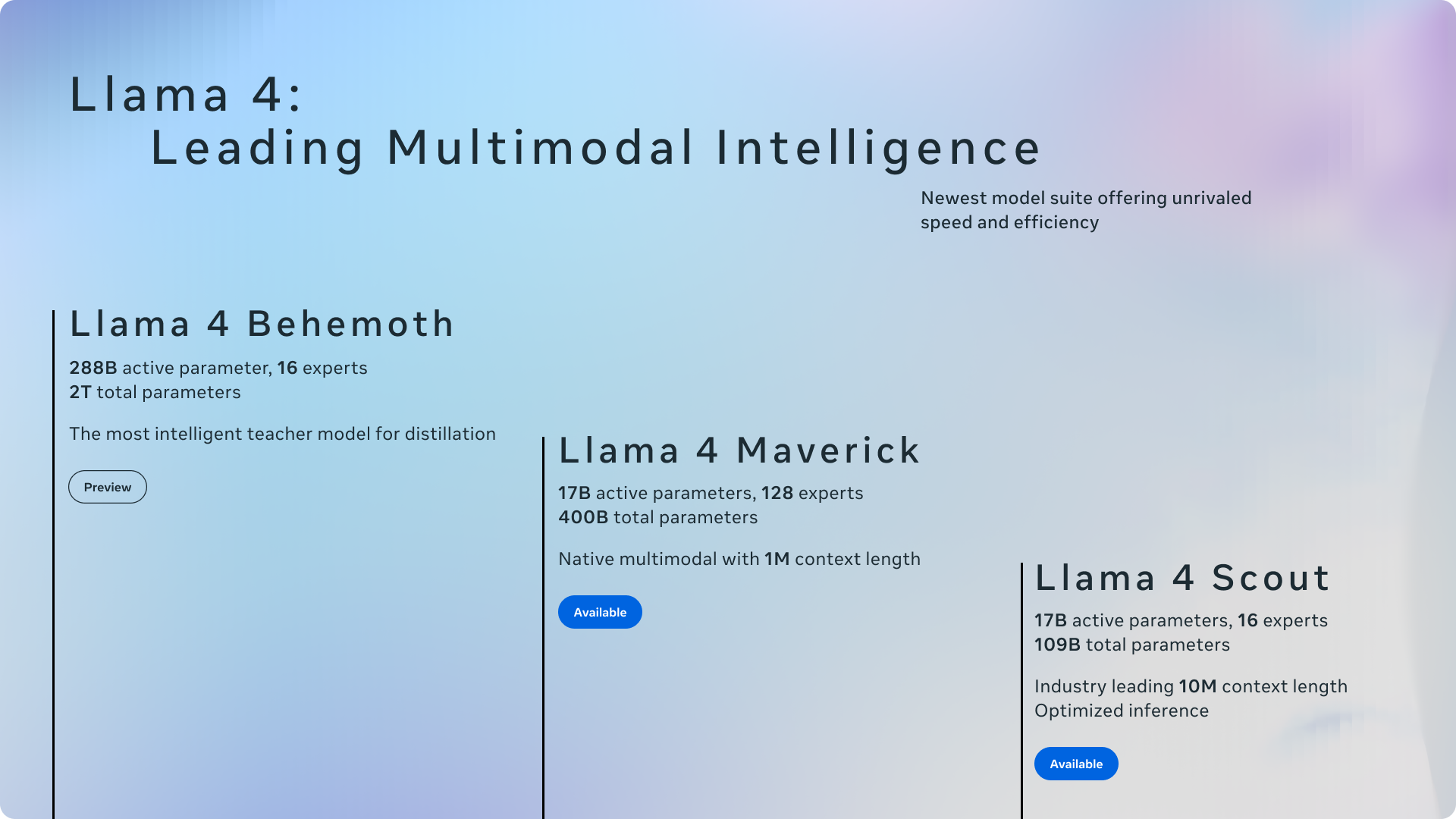
2025년 6월 기준, 셀프호스팅을 위한 최고의 오픈소스 모델 7가지를 성능, 접근성, 실제 배포 준비도 순으로 정리했습니다.
1. Meta Llama 4 Scout — 업계 최고의 MoE 모델
2025년 4월에 출시된 Llama 4 Scout는 오픈 웨이트 모델의 기준을 다시 세웠습니다. 총 1,090억 개의 파라미터가 16개의 MoE(Mixture of Experts) 모듈에 분산되어 있으며, 추론 시에는 170억 개만 활성화됩니다. 결과적으로 GPT-4o급 성능을 H100 GPU 한 장에서 구현할 수 있습니다.
가장 주목할 특징은 1,000만 토큰 컨텍스트 윈도우입니다. 현재 오픈 웨이트 모델 중 가장 긴 컨텍스트를 제공합니다. Meta AI에 따르면 Scout는 Gemma 3와 Gemini 2.0 Flash-Lite를 다수의 벤치마크에서 능가하며, 텍스트와 이미지를 동시에 처리하는 멀티모달 기능도 네이티브로 지원합니다.
- 파라미터: 총 1,090억 (활성 170억), 16-전문가 MoE
- 컨텍스트 윈도우: 1,000만 토큰
- 라이선스: Llama Community License
- 필요 VRAM: 80GB (H100 또는 A100 단일 GPU)
- 추천 용도: 대규모 컨텍스트와 프론티어급 성능이 필요한 전담 인프라 팀
2. DeepSeek R1 — MIT 라이선스의 o1급 추론 모델
2025년 1월 출시된 DeepSeek R1은 업계에서 ‘딥시크 모먼트’라 불리는 충격을 일으켰습니다. 총 6,710억 파라미터(활성 370억)의 MoE 모델로, OpenAI o1과 동등한 수학적 추론과 복잡한 코딩 능력을 보여줍니다. 셀프호스팅 시 비용은 약 95% 절감됩니다. MIT 라이선스이므로 상업적 사용에 제한이 전혀 없습니다.
체인 오브 소트(Chain-of-Thought) 추론, 고급 수학, 코드 생성이 필요한 조직이라면 DeepSeek R1이 현재 가장 강력한 오픈소스 선택지입니다. Ollama를 통해 다양한 양자화 버전을 다운로드할 수 있어 멀티 GPU 소비자급 환경에서도 접근 가능합니다.
- 파라미터: 총 6,710억 (활성 370억), MoE 아키텍처
- 컨텍스트 윈도우: 32K 토큰 (확장 시 128K)
- 라이선스: MIT (완전 허용)
- 필요 VRAM: 양자화 버전 48-80GB, 풀 정밀도는 멀티 GPU 필요
- 추천 용도: 연구팀, 코딩 어시스턴트, 수학 집약적 애플리케이션
3. Qwen 2.5 72B — Dense 모델의 최적 밸런스
MoE 모델이 인프라에 부담스럽다면, Qwen 2.5 72B가 현재 셀프호스팅 가능한 최고의 Dense 모델입니다. 알리바바가 Apache 2.0 라이선스로 공개했으며 — 이 리스트에서 가장 관대한 라이선스입니다 — 29개 언어를 지원하고 Llama 외부에서 가장 큰 파인튜닝 커뮤니티를 보유하고 있습니다.
128K 컨텍스트 윈도우는 엔터프라이즈급 문서 처리에 충분하며, 양자화 버전(Q4)은 NVIDIA A6000 같은 48GB VRAM 카드에서 실행됩니다. 벤치마크 분석에 따르면 Qwen 2.5 72B는 다국어 작업에서 Llama 3.1 70B를 일관되게 능가하면서 영어 성능도 경쟁력을 유지합니다. Hugging Face 생태계의 방대한 파인튜닝 변형 모델들도 큰 장점입니다.
- 파라미터: 72B Dense
- 컨텍스트 윈도우: 128K 토큰
- 라이선스: Apache 2.0 (완전 허용)
- 필요 VRAM: 48GB (Q4 양자화), 80GB+ (풀 정밀도)
- 추천 용도: 다국어 엔터프라이즈 배포, RAG 파이프라인, 파인튜닝 유연성이 필요한 팀
4. Google Gemma 3 27B — 소비자 GPU의 챔피언
Gemma 3는 Google의 오픈소스 전략의 핵심이며, 27B 모델은 소비자용 GPU 단일 장으로 실행할 수 있는 최고의 모델입니다. 2025년 3월 출시되었고, 양자화하면 24GB RTX 4090에서 동작하면서 LMArena 리더보드에서 자기 체급을 훨씬 뛰어넘는 성능을 보여줍니다.
Gemini 2.0 연구를 기반으로 제작되었으며, 140개 이상의 언어를 네이티브로 지원하고 텍스트와 이미지 모두 이해하는 멀티모달 기능을 갖추고 있습니다. 이미 보유한 게이밍 하드웨어에서 로컬 AI 어시스턴트를 구축하려는 개발자에게 현재 가장 뛰어난 가성비를 제공합니다.
- 파라미터: 27B Dense
- 컨텍스트 윈도우: 128K 토큰
- 라이선스: Gemma License (허용적, 상업 사용 가능)
- 필요 VRAM: 24GB (Q4 양자화, RTX 4090/3090)
- 추천 용도: 소비자 하드웨어 개발자, 로컬 AI 어시스턴트, 다국어 애플리케이션

5. Microsoft Phi-4 Reasoning — 작지만 강력한 추론 전문가
Phi-4 Reasoning은 파라미터 수가 전부가 아니라는 것을 증명합니다. 불과 140억 파라미터로 Microsoft가 만든 이 MIT 라이선스 모델은 자기보다 5배 큰 DeepSeek-R1-Distill-70B를 추론 벤치마크에서 이깁니다. 비결은 OpenAI o3-mini에서 증류(distillation)한 체인 오브 소트 추론 능력입니다.
셀프호스팅 관점에서 시사점이 큽니다. Phi-4는 16GB VRAM에서 실행됩니다. RTX 4080이나 M2 Pro MacBook이면 됩니다. 100만 원 미만의 하드웨어에서 진정한 추론 능력을 얻을 수 있습니다. 엣지 배포나 개발 워크플로우에 빠르고 가벼운 스마트 모델이 필요하다면, 이 클래스에서 Phi-4가 확실한 승자입니다.
- 파라미터: 14B Dense
- 컨텍스트 윈도우: 16K 토큰
- 라이선스: MIT (완전 허용)
- 필요 VRAM: 16GB (RTX 4080, M2 Pro에서 실행)
- 추천 용도: 엣지 배포, 개발자 도구, 저예산 하드웨어에서의 추론 작업
6. Mistral Small 3 (24B) — 프로덕션 워크호스
Mistral은 프로덕션 환경에서 안정적으로 작동하는 모델을 만드는 것으로 정평이 나 있으며, Mistral Small 3도 그 전통을 이어갑니다. Apache 2.0 라이선스의 24B 파라미터 모델로, 응답 시간 밀리초 하나가 중요한 엣지 디바이스와 프로덕션 서버를 위해 설계되었습니다.
Mistral Small 3가 빛나는 분야는 명령어 수행과 코드 생성입니다. 구조화된 출력을 안정적으로 처리하고, 복잡한 다단계 명령어를 환각 없이 따르며, 기존 OpenAI 호환 API와 원활하게 통합됩니다. 일관되고 예측 가능한 행동이 필요한 고객 대면 AI 기능을 배포하는 팀에 이상적입니다.
- 파라미터: 24B Dense
- 컨텍스트 윈도우: 32K 토큰
- 라이선스: Apache 2.0 (완전 허용)
- 필요 VRAM: 24GB (Q4 양자화)
- 추천 용도: 프로덕션 API, 고객 대면 애플리케이션, 저지연 추론
7. Cohere Command R+ (104B) — RAG 전문가
Command R+는 다른 오픈 모델이 잘 채우지 못하는 니치를 담당합니다: 검색 증강 생성(RAG)입니다. 총 1,040억 파라미터(MoE로 160억 활성) 규모로, 환각이 아닌 문서 기반의 근거 있는 답변 생성에 특화되어 있습니다. 엔터프라이즈 검색, 지식 베이스, 문서 Q&A 시스템을 구축한다면 Command R+가 정확히 그 목적에 맞게 설계되었습니다.
10개 이상의 언어를 네이티브로 지원하며, 내장된 도구 사용(tool-use) 기능으로 외부 API 호출, 데이터베이스 검색, 액션 체이닝을 프롬프트 엔지니어링 없이 수행합니다. CC-BY-NC 라이선스로 연구와 내부 사용은 무료이며, 상업 배포에는 Cohere와 별도 계약이 필요합니다.
- 파라미터: 총 1,040억 (활성 160억), MoE
- 컨텍스트 윈도우: 128K 토큰
- 라이선스: CC-BY-NC 4.0 (비상업 무료, 상업 배포 시 라이선스 필요)
- 필요 VRAM: 48-80GB
- 추천 용도: 엔터프라이즈 RAG, 문서 검색, 근거 기반 Q&A 시스템
오픈소스 LLM 셀프호스팅 2025: 필수 배포 도구
훌륭한 모델을 갖추는 것은 절반에 불과합니다. 올바른 인프라가 있어야 합니다. 2025년 6월 기준으로 중요한 네 가지 도구를 소개합니다.
Ollama — LLM의 Docker
Ollama는 로컬에서 모델을 가장 빠르게 실행하는 방법입니다. ollama run llama4-scout 한 줄이면 localhost에서 OpenAI 호환 API 엔드포인트가 구동됩니다. 내부적으로 llama.cpp를 번들하고 자동 양자화를 처리하며, macOS, Linux, Windows를 모두 지원합니다. 개발, 개인 사용, 빠른 프로토타이핑에 최적입니다.
vLLM — 프로덕션급 추론 엔진
Ollama로 부족할 때 vLLM이 답입니다. PagedAttention 알고리즘은 기본 추론 대비 최대 19배 높은 처리량을 제공하며, 연속 배칭과 투기적 디코딩으로 GPU 활용률을 90% 이상 유지합니다. 동시 사용자를 처리하거나 실제 트래픽을 감당할 내부 API를 구축한다면 vLLM이 프로덕션 표준입니다.
llama.cpp — 범용 기반 엔진
로컬 LLM 혁명을 시작한 C/C++ 추론 엔진입니다. 의존성 없이 데이터센터 GPU부터 스마트폰까지 모든 곳에서 실행됩니다. Ollama가 llama.cpp 위에 구축되었지만, 직접 사용하면 양자화 형식, 메모리 관리, 하드웨어별 최적화에 대한 최대한의 제어권을 얻을 수 있습니다.
Hugging Face TGI — 엔터프라이즈 통합
Hugging Face의 Text Generation Inference는 HF 모델 허브와 직접 통합되어, 이미 Hugging Face 생태계를 사용하는 조직에 가장 쉬운 옵션입니다. 모니터링과 스케일링 기능이 우수한 엔터프라이즈급 솔루션입니다.
GPU VRAM 가이드: 실제로 필요한 사양
셀프호스팅에서 가장 많이 받는 질문은 “어떤 GPU가 필요한가요?”입니다. 2025년 6월 기준 실제 가이드입니다:
- 8GB VRAM (RTX 4060, M1 MacBook): Q4 양자화 7B 모델 — Phi-4-mini, Gemma 3 1B. 실험용으로 적합하며 프로덕션에는 부적합합니다.
- 16GB VRAM (RTX 4080, M2 Pro): Q4-Q8 13-14B 모델 — Phi-4 Reasoning, Qwen 2.5 14B. 개인 생산성 도구의 스위트 스폿입니다.
- 24GB VRAM (RTX 4090, RTX 3090): Q4 27-30B 모델 — Gemma 3 27B, Mistral Small 3. 본격적인 로컬 AI 역량을 갖출 수 있습니다.
- 48GB VRAM (A6000, 듀얼 GPU 구성): 양자화 70B+ 모델 — Qwen 2.5 72B Q4. 워크스테이션 하드웨어의 엔터프라이즈급 성능입니다.
- 80GB VRAM (H100, A100): 풀 정밀도 70B+ 모델, Llama 4 Scout 단일 카드 운영. 데이터센터 영역입니다.
실전 팁: 시작한다면 RTX 4090(24GB)을 구매하고 Ollama로 Gemma 3 27B 또는 Mistral Small 3를 실행해 보십시오. 대부분의 작업에서 클라우드 API에 필적하는 로컬 AI 어시스턴트를 하드웨어 투자 이후 추가 비용 없이 운영할 수 있습니다.
결론
2025년 6월은 LLM 셀프호스팅이 취미 프로젝트에서 진정한 비즈니스 전략으로 전환되는 시점입니다. 모델의 성능은 충분하고, 도구는 충분히 성숙했으며, 하드웨어는 충분히 접근 가능합니다. 게이밍 GPU를 가진 개인 개발자든, 전용 인프라를 보유한 엔터프라이즈 팀이든, 이 리스트에서 자신에게 맞는 오픈소스 모델을 찾을 수 있습니다.
가장 현명한 접근법은 작게 시작하는 것입니다. Ollama를 설치하고, Phi-4나 Gemma 3를 내려받아 실제 유스케이스에 테스트해 보십시오. 품질이 기준을 충족하면 vLLM과 더 큰 모델로 스케일업하면 됩니다. API 의존에서 AI 독립으로 가는 길이며, 그 길이 지금처럼 짧았던 적은 없습니다.
셀프호스팅 LLM 구축, AI 파이프라인 설계, 인프라 자동화가 필요하시다면 편하게 연락 주세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}