
Next.js 16.2 심층 분석: 개발 서버 87% 빠른 시작, Agent DevTools, 200+ Turbopack 수정
3월 25, 2026
아틀라시안 감원 AI 전환: 1,600명 해고, CTO 2명 체제로 전격 개편한 이유
3월 25, 2026
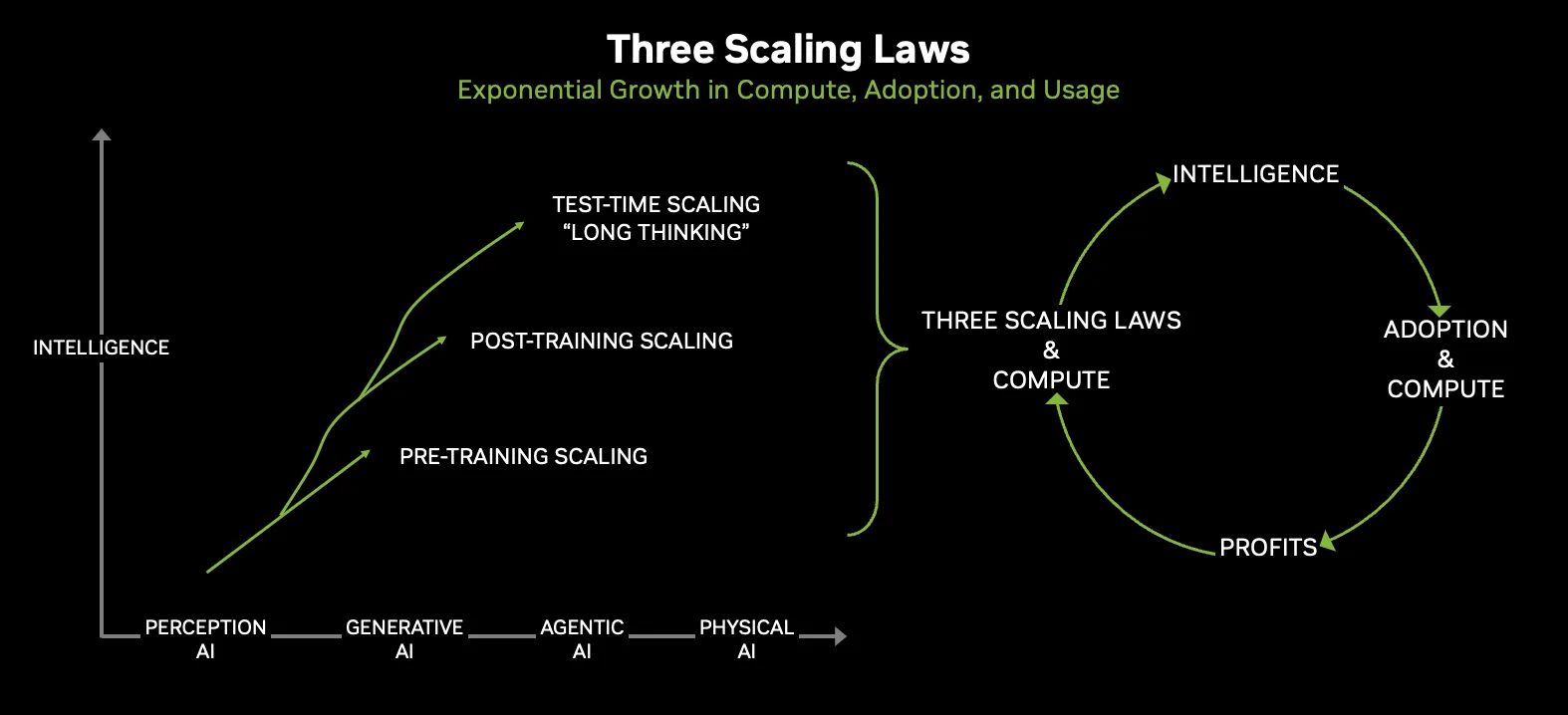
GPU 1개에 50 PFLOPS — NVIDIA가 GTC 2026에서 보여준 숫자는 현실감이 없습니다. 트랜지스터 336B개, 메모리 대역폭 22 TB/s, 그리고 이 모든 것을 72개 묶은 랙은 인터넷 전체보다 넓은 대역폭을 제공합니다. NVIDIA Vera Rubin 플랫폼, 2026년 AI 인프라의 새로운 기준입니다.
NVIDIA Vera Rubin — 6개 칩이 하나의 슈퍼컴퓨터를 이루다
2026년 3월 16일, 산호세 SAP 센터에서 열린 GTC 2026 키노트에서 젠슨 황 CEO는 “Vera Rubin은 세대적 도약”이라고 선언했습니다. 그의 말 그대로, 이 플랫폼은 7개의 혁신적인 칩, 5개의 랙 시스템, 하나의 거대한 슈퍼컴퓨터로 구성됩니다. 핵심 6개 칩은 Rubin GPU, Vera CPU, NVLink 6 스위치, ConnectX-9 SuperNIC, BlueField-4 DPU, 그리고 Spectrum-6 이더넷 스위치입니다.
여기에 GTC 2026에서 추가된 7번째 칩, NVIDIA Groq 3 LPU(Language Processing Unit)까지 — NVIDIA가 200억 달러 규모로 인수한 Groq의 기술이 플랫폼에 통합되었습니다.

Rubin GPU — 336B 트랜지스터, 50 PFLOPS의 괴물
NVIDIA Vera Rubin의 핵심인 Rubin GPU는 TSMC 3nm 공정으로 제조된 듀얼 다이 설계입니다. 두 개의 레티클 크기 컴퓨트 칩렛이 합쳐져 336B(3,360억) 개의 트랜지스터를 담고 있으며, 이는 Blackwell의 208B 대비 1.6배 증가한 수치입니다.
성능 수치도 압도적입니다. NVFP4 추론 성능 50 PFLOPS, 훈련 성능 35 PFLOPS. FP32 벡터 연산 130 TFLOPS, FP32 매트릭스 연산 400 TFLOPS, FP64 벡터 연산 33 TFLOPS, FP64 매트릭스 연산 200 TFLOPS — 과학 시뮬레이션부터 AI 추론까지 전 영역을 커버합니다.
메모리도 혁신적입니다. GPU당 288GB HBM4 메모리를 탑재하여 22 TB/s의 대역폭을 제공하는데, 이는 Blackwell의 HBM3e(8 TB/s) 대비 2.8배 향상된 수치입니다. 5세대 텐서 코어 224개가 저정밀 연산에 최적화되어 있어 대규모 MoE(Mixture of Experts) 모델 훈련과 추론에서 획기적인 효율을 달성합니다.
Vera CPU — 88코어 커스텀 Olympus 아키텍처
NVIDIA가 자체 설계한 Vera CPU는 88개의 커스텀 Olympus 코어를 탑재했습니다. Arm v9.2 호환 아키텍처로, 공간 멀티스레딩을 통해 176개 스레드를 동시 처리합니다. 코어당 2MB L2 캐시, 통합 162MB L3 캐시를 갖추고 있으며, 최대 1.5TB LPDDR5X 메모리를 지원합니다.
주목할 점은 메모리 대역폭입니다. 코어당 기준으로 x86 CPU 대비 3배 높은 메모리 대역폭과 2배의 에너지 효율을 제공합니다. NVLink-C2C 연결을 통해 GPU와 1.8 TB/s 양방향 대역폭으로 통신하며, PCIe Gen 6과 CXL 3.1까지 지원합니다. 이는 CPU-GPU 간 통합 메모리 공간을 구현하여 KV 캐시 오프로드와 멀티모델 실행을 가능하게 합니다.
NVLink 6 — 인터넷보다 넓은 대역폭
6세대 NVLink은 GPU당 3.6 TB/s의 양방향 대역폭을 제공합니다. 이는 Blackwell 대비 2배 향상된 수치로, 특히 MoE 전문가 라우팅에서 요구되는 통신 패턴에서 2배 높은 처리량을 달성합니다.
NVLink 6 스위치 트레이당 28.8 TB/s의 집계 대역폭을 제공하며, FP8 인네트워크 컴퓨트(SHARP) 기능으로 트레이당 14.4 TFLOPS의 연산이 가능합니다. SHARP 기술은 올리듀스 트래픽을 최대 50% 줄이고, 집합 연산 시간을 최대 20% 개선합니다. 72개 GPU 전체가 단일 홉으로 연결되는 풀 올투올 패브릭 구조입니다.
NVIDIA Vera Rubin NVL72 — 3.6 ExaFLOPS 랙
Vera Rubin NVL72는 72개의 Rubin GPU와 36개의 Vera CPU를 하나의 랙에 통합합니다. 18개의 컴퓨트 트레이와 9개의 NVLink 스위치 트레이, 130만 개의 개별 부품, 약 1,300개의 칩이 약 1,800kg(4,000파운드) 무게의 3세대 MGX 랙 하나에 담깁니다.
성능 수치는 충격적입니다. NVFP4 추론 3.6 ExaFLOPS, 훈련 2.52 ExaFLOPS. HBM4 총 용량 20.7TB에 1.6 PB/s 메모리 대역폭, Vera CPU 연결 LPDDR5X 54TB, 그리고 NVLink 6 총 260 TB/s 스케일업 대역폭 — NVIDIA는 이것이 “인터넷 전체 대역폭보다 크다”고 표현합니다.

Blackwell 대비 효율 개선도 극적입니다. 대규모 MoE 모델 훈련 시 GPU 수를 1/4로 줄일 수 있고, 와트당 추론 처리량은 최대 10배, 토큰당 비용은 1/10 수준입니다. Hopper H200 대비로는 와트당 토큰 수가 약 50배 향상되었습니다.
네트워킹과 스토리지 — ConnectX-9, BlueField-4, Spectrum-6
ConnectX-9 SuperNIC은 포트당 800 Gb/s, GPU당 1.6 Tb/s의 네트워크 대역폭을 제공합니다. 프로그래밍 가능한 혼잡 제어와 트래픽 셰이핑, IPsec/PSP 전송 중 암호화를 지원합니다.
NVIDIA에 따르면, BlueField-4 DPU는 64개의 Grace CPU 코어(Neoverse V2)와 128GB LPDDR5X 메모리를 탑재하여 800 Gb/s AES-XTS 암호화, 128K 호스트 클라우드 네트워킹, 2000만 IOPs NVMe 스토리지 분리를 처리합니다. Spectrum-6 이더넷 스위치는 칩당 102.4 Tb/s 총 대역폭과 32개의 실리콘 포토닉스 엔진을 탑재하여 기존 트랜시버 대비 64배 향상된 신호 무결성과 약 5배의 전력 효율을 제공합니다.
Groq 3 LPU — 7번째 칩의 등장
GTC 2026에서 공개된 7번째 칩은 NVIDIA Groq 3 LPU입니다. 256개의 LPU 프로세서를 탑재한 LPX 랙은 128GB 온칩 SRAM, 640 TB/s 스케일업 대역폭을 제공하며, 메가와트당 추론 처리량이 최대 35배 높습니다. 1조 파라미터 모델에서 최대 10배의 수익 기회를 창출한다고 NVIDIA는 밝혔습니다.
Blackwell vs. Vera Rubin — 세대 간 비교
핵심 수치만 정리하면 그 차이가 선명합니다. 추론 처리량 최대 5배, 훈련 처리량 3.5배, 메모리 대역폭 2.8배, NVLink 대역폭 2배, 트랜지스터 수 1.6배. Tom’s Hardware에 따르면, 이는 단순한 성능 향상이 아니라 AI 인프라 경제학 자체를 재정의하는 수준입니다.
특히 주목해야 할 것은 효율 지표입니다. 와트당 성능 10배, 토큰당 비용 1/10이라는 수치는 AI 팩토리 운영 비용 구조를 근본적으로 바꿉니다. 젠슨 황은 2027년까지 Blackwell과 Vera Rubin 시스템에 대한 주문이 “최소 1조 달러”에 이를 것으로 전망했는데, 이는 기존 5,000억 달러 예상치의 두 배 이상입니다.
출시 일정과 업계 반응
NVIDIA Vera Rubin은 현재 풀 프로덕션에 들어갔으며, 파트너사를 통한 제품 출시는 2026년 하반기(Q3-Q4)로 예정되어 있습니다. Vera Rubin Ultra는 144개 GPU를 수직 배치하는 Kyber 디자인으로 2027년 출시 예정입니다.
업계 반응도 즉각적이었습니다. Anthropic CEO 다리오 아모데이는 “NVIDIA의 Vera Rubin 플랫폼은 안전성을 발전시키면서 지속적으로 성과를 낼 수 있는 컴퓨팅, 네트워킹, 시스템 설계를 제공한다”고 평가했고, OpenAI CEO 샘 알트만은 “NVIDIA Vera Rubin으로 더 강력한 모델과 에이전트를 대규모로 실행하고 더 빠른 시스템을 제공할 것”이라고 밝혔습니다.

결국 Vera Rubin은 단순히 더 빠른 GPU가 아닙니다. CPU, GPU, 네트워크, 스토리지, 보안까지 6개(+1) 칩이 수직 통합된 완전한 AI 인프라 플랫폼입니다. 에이전틱 AI, 장기 추론, 조단위 파라미터 모델이 현실화되는 2026-2027년, 이 플랫폼이 AI 팩토리의 표준 단위가 될 가능성이 매우 높습니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.


{kind=link}
{kind=link}