
프로듀서 새해 다짐 2026: 진짜 레벨업을 위한 10가지 방법
12월 29, 2025
2025 최고의 플러그인: VST 및 이펙트 에디터스 초이스 어워드 총정리
12월 31, 2025
파라미터 500억 개짜리 모델이 실제로는 50억 개만 활성화하면서 GPT급 성능을 낸다면 믿으시겠습니까? 2025년 12월 15일, NVIDIA가 공개한 NVIDIA Nemotron 3 패밀리가 정확히 그 약속을 현실로 만들었습니다. Nano 30B, Super 100B, Ultra 500B 세 가지 모델 라인업과 함께 학습 데이터 3조 토큰, 학습 레시피까지 전부 오픈소스로 풀어버린 이번 발표는 2025년 AI 업계의 피날레를 장식하기에 충분합니다.
NVIDIA Nemotron 3 패밀리: 세 가지 모델, 하나의 철학
젠슨 황 CEO는 “오픈 혁신이야말로 AI 발전의 기반”이라고 선언했습니다. 이번에 공개된 세 모델은 크기만 다른 것이 아니라, 각각 명확한 용도를 가지고 설계되었습니다.
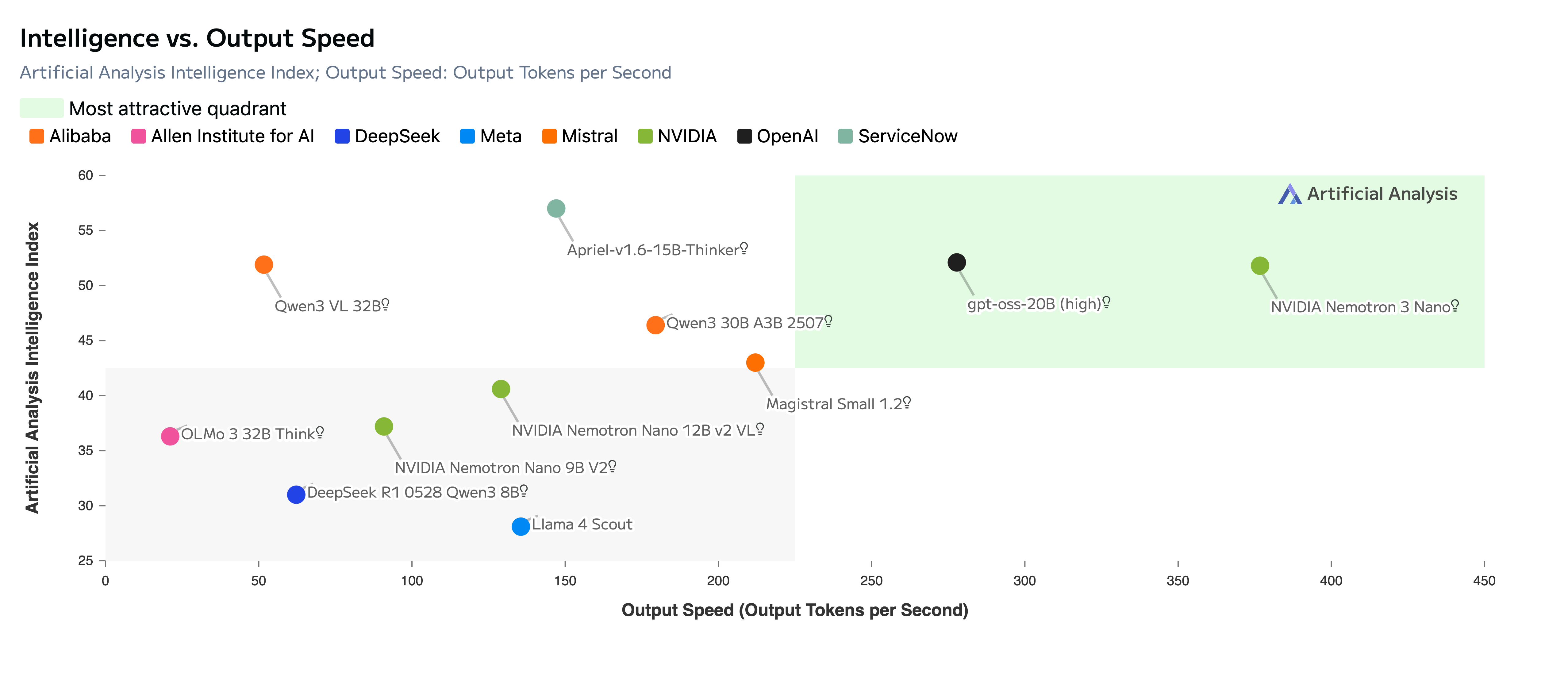
Nano (30B 파라미터 / 3B 활성화) — 엣지 디바이스부터 클라우드까지 범용 추론에 최적화된 모델입니다. 이미 즉시 사용 가능하며, 이전 세대 Nemotron 2 Nano 대비 4배 높은 처리량과 60% 적은 추론 토큰 소모를 자랑합니다. arXiv 논문(2512.20856)에 따르면 23개의 Mamba-2/MoE 레이어와 6개의 Attention 레이어로 구성되며, MoE 레이어당 128개 전문가 + 1개 공유 전문가 중 토큰당 6개만 활성화합니다.
Super (~100B 파라미터 / 10B 활성화) — 복잡한 에이전틱 워크플로우와 멀티 에이전트 시스템을 위한 중간 모델입니다. Multi-Token Prediction 레이어가 추가되어 더 정교한 추론이 가능합니다. 2026년 상반기 출시 예정입니다.
Ultra (~500B 파라미터 / 50B 활성화) — 최고 수준의 추론 성능을 요구하는 엔터프라이즈 시나리오를 위한 플래그십 모델입니다. 역시 Multi-Token Prediction을 탑재하며, 2026년 상반기에 공개됩니다.
하이브리드 Mamba-Transformer MoE: NVIDIA Nemotron 3의 핵심 아키텍처
Nemotron 3가 경쟁 모델들을 압도하는 효율성을 달성할 수 있었던 비결은 하이브리드 Mamba-2 + Transformer MoE 아키텍처에 있습니다. 기존 Transformer 기반 모델들이 시퀀스 길이에 따라 연산 비용이 제곱으로 증가하는 문제를 안고 있었다면, Mamba-2의 상태 공간 모델(SSM) 레이어는 선형 복잡도로 긴 컨텍스트를 처리합니다.
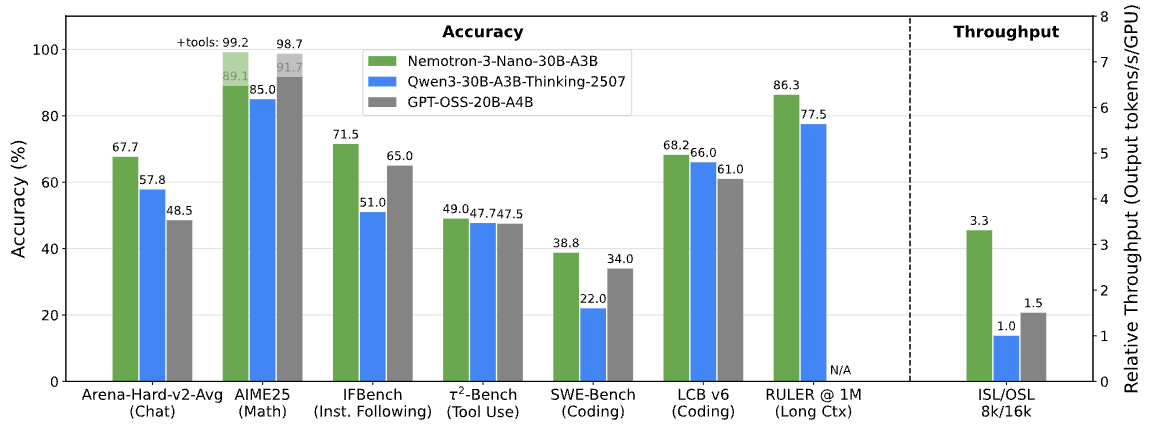
여기에 Mixture of Experts(MoE) 구조를 결합해 전체 파라미터의 10%만 활성화하면서도 전체 모델급 성능을 유지합니다. 이것이 Nano 모델이 30B 파라미터를 가지면서도 실제 추론 시 3B만 사용하는 비결입니다. NVIDIA 기술 블로그에서 공개한 LatentMoE 설계는 라우팅 오버헤드까지 최소화하여, Qwen3-30B-A3B 대비 3.3배, GPT-OSS-20B 대비 2.2배 높은 처리량을 기록했습니다.
특히 주목할 점은 100만 토큰 컨텍스트 윈도우입니다. RULER 벤치마크에서 다양한 컨텍스트 길이에 걸쳐 GPT-OSS-20B와 Qwen3-30B-A3B를 모두 능가하는 성능을 보여줬습니다. 이는 대규모 코드베이스 분석, 장편 문서 처리, 복잡한 멀티턴 에이전트 대화 등에서 실질적인 차별화 요소가 됩니다.
NVFP4와 Blackwell: 하드웨어-소프트웨어 통합 전략
NVIDIA가 단순히 모델만 공개한 것이 아닙니다. Nemotron 3는 NVFP4라는 4비트 부동소수점 학습 포맷을 도입했으며, 이는 Blackwell GPU 아키텍처에 최적화되어 있습니다. 기존 FP8이나 INT8 양자화와 달리, NVFP4는 학습 단계부터 4비트 정밀도를 활용해 메모리 사용량과 연산 비용을 극적으로 줄입니다.
이것은 NVIDIA만이 할 수 있는 수직 통합 전략입니다. GPU 하드웨어(Blackwell), 양자화 포맷(NVFP4), 모델 아키텍처(Nemotron 3), 학습 프레임워크(NeMo)까지 전부 자체 생태계 안에서 최적화한 것입니다. 오픈소스로 모델을 풀면서도 NVIDIA GPU에서 가장 잘 돌아가게 만든 셈이니, 이것이야말로 2025년 가장 영리한 비즈니스 전략이라 할 수 있습니다.
에이전틱 AI 시대를 위한 설계: 왜 Nemotron 3인가
SiliconANGLE의 분석에 따르면, AI 업계의 경쟁 축이 “더 큰 모델”에서 “더 효율적인 오케스트레이션”으로 이동하고 있습니다. Nemotron 3는 이 변화를 정확히 겨냥합니다. 단일 모델의 최대 추론 성능보다 시스템 수준의 멀티 에이전트 효율성에 최적화된 것입니다.
실제로 이미 쟁쟁한 엔터프라이즈 파트너들이 Nemotron 3를 채택하고 있습니다. Accenture, CrowdStrike, Oracle, Palantir, Perplexity, ServiceNow, Siemens, Zoom 등이 초기 채택 기업으로 이름을 올렸습니다. Perplexity의 CEO는 에이전트 라우터 통합에 Nemotron 3를 활용하고 있다고 밝혔습니다.
또한 NVIDIA는 NeMo Gym과 NeMo RL 라이브러리를 함께 공개했습니다. 이를 통해 개발자들은 멀티 환경 강화학습(Multi-environment RL) 기반의 후학습(post-training)을 직접 수행할 수 있습니다. 추론 시 추론 예산(reasoning budget)을 세밀하게 제어하는 기능까지 제공되어, 에이전트가 상황에 따라 “얼마나 깊이 생각할지”를 조절할 수 있습니다.
오픈소스 AI 경쟁 구도: Llama, Mistral, Qwen과의 차별점
Nemotron 3의 등장으로 오픈소스 AI 모델 경쟁이 한층 치열해졌습니다. Meta의 Llama, Mistral, 그리고 알리바바의 Qwen이 이미 강력한 오픈 모델들을 보유하고 있지만, NVIDIA는 차별화된 접근법을 택했습니다.
- 모델 가중치 + 학습 데이터(3조 토큰) + 학습 레시피 전부 공개 — 대부분의 경쟁사가 모델 가중치만 공개하는 것과 대조적입니다
- NVIDIA Open Model License — 상업적 사용이 가능하면서도 안전장치 조항을 포함한 균형 잡힌 라이선스
- 하드웨어 최적화 — Blackwell GPU에서 NVFP4로 최대 효율을 뽑아내는 수직 통합
- 에이전트 중심 설계 — 단순 챗봇이 아닌 멀티 에이전트 시스템의 구성 요소로 설계
2025년 연말에 공개된 arXiv 논문(2512.20856)은 아키텍처 상세, 학습 방법론, 벤치마크 결과를 포괄적으로 담고 있어 연구 커뮤니티에서도 큰 주목을 받고 있습니다. 파라미터 수 경쟁에서 효율성과 오케스트레이션 경쟁으로의 전환점을 알리는 논문이라 할 수 있습니다.
2025년을 마무리하며: NVIDIA Nemotron 3가 2026년에 던지는 질문
Nemotron 3 Nano는 이미 사용 가능하고, Super와 Ultra는 2026년 상반기에 출시됩니다. 현재 Nano만으로도 동급 모델들을 처리량과 효율성에서 압도하고 있는 만큼, 나머지 두 모델이 합류하면 오픈소스 AI 생태계의 판도가 상당히 바뀔 가능성이 높습니다.
특히 주목해야 할 것은 Nemotron 3가 단순한 “더 좋은 모델”이 아니라 “더 좋은 시스템을 만들기 위한 구성 요소”로 설계되었다는 점입니다. 에이전틱 AI가 2026년의 핵심 키워드가 될 것이 확실한 지금, NVIDIA는 그 기반을 오픈소스로 깔아버렸습니다. 이 모델들을 어떻게 조합하고 활용할 것인지가 2026년 AI 개발자들에게 가장 중요한 질문이 될 것입니다.
AI 에이전트 시스템 구축이나 오픈소스 모델 기반 파이프라인 설계에 관심이 있으시다면, 기술 컨설팅을 통해 최적의 아키텍처를 함께 설계해 드립니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}