
SSL Native Bus Compressor 2 리뷰: X 모드와 5개 새 비율이 바꿔놓은 글루 컴프레션의 기준
11월 21, 2025
Xbox Series X 리프레시 vs 차세대 프로젝트 헬릭스: 실제로 중요한 5가지 하드웨어 변화
11월 21, 2025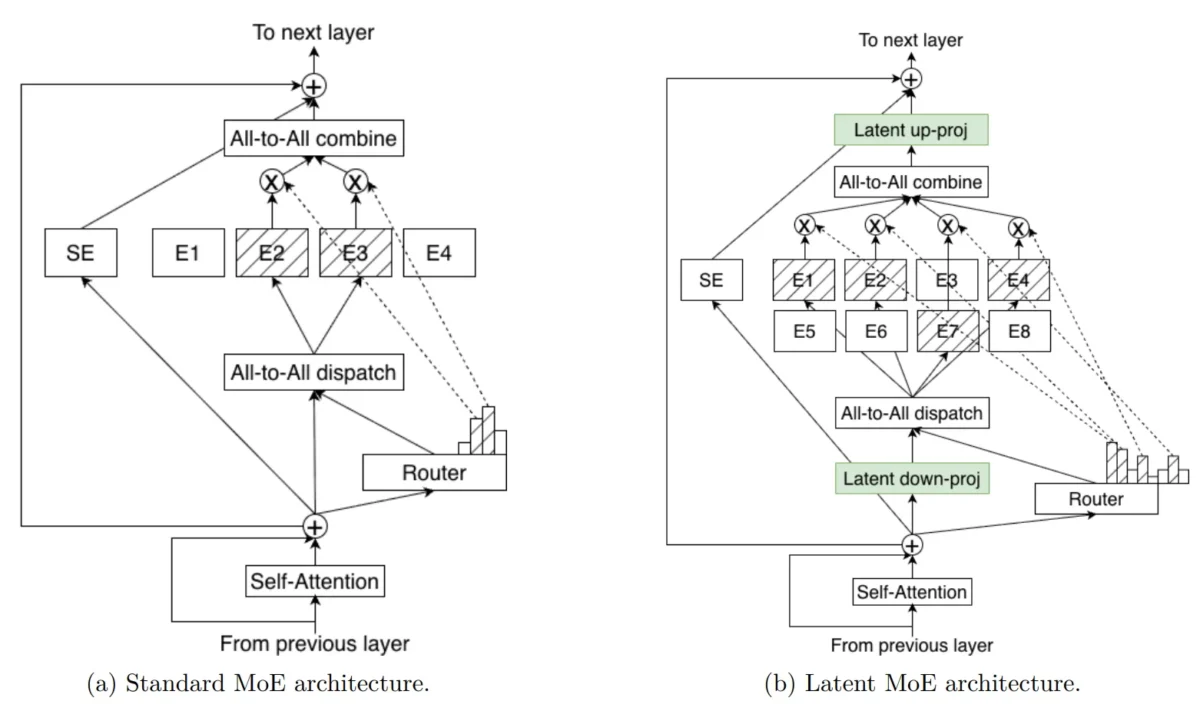
드디어 정확도와 처리량 사이에서 선택을 강요하지 않는 오픈 모델 패밀리가 등장했습니다. NVIDIA Nemotron 3는 하이브리드 Mamba-Transformer MoE 아키텍처로 30B 파라미터 중 토큰당 3B만 활성화하면서도, 벤치마크에서 동급 Dense 모델을 압도하는 성능을 보여줍니다. 에이전틱 AI 시대의 게임 체인저가 될 수 있을까요?
NVIDIA Nemotron 3가 다른 오픈 모델과 다른 점
AI 모델 개발은 그동안 무조건적인 스케일업 경쟁이었습니다. 더 많은 파라미터, 더 많은 컴퓨팅, 더 많은 비용. NVIDIA의 Nemotron 3 패밀리는 정반대의 접근법을 택했습니다. Nano(30B), Super(100B), Ultra(500B) 세 모델 모두 하이브리드 Mamba-Transformer MoE 아키텍처를 통해 전체 파라미터의 일부만 활성화합니다. Nano는 3B, Super는 10B, Ultra는 50B입니다.
그 결과는 놀랍습니다. Nemotron 3 Nano는 전작 Nemotron 2 Nano 대비 4배 높은 처리량을 달성하면서, 동시에 추론 토큰 생성을 최대 60%까지 줄였습니다. 점진적 개선이 아닌, 프로덕션 AI 에이전트 운영의 비용 대비 품질 비율을 근본적으로 바꾸는 수준의 변화입니다.
NVIDIA Nemotron 3 하이브리드 아키텍처: Mamba-2, Transformer, MoE의 협업
대부분의 대규모 언어 모델은 순수 Transformer 기반입니다. 시퀀스 길이에 따라 계산량이 이차 함수적으로 증가하기 때문에, 긴 컨텍스트 처리 비용이 급격히 상승합니다. Nemotron 3는 세 가지 레이어 유형을 정교하게 설계된 패턴으로 인터리빙합니다: Mamba-2/MoE 5쌍 + 어텐션 블록, Mamba-2/MoE 3쌍 + 어텐션 블록, Mamba-2/MoE 4쌍의 구조입니다.
각 구성요소는 명확한 역할을 수행합니다. Mamba-2 레이어는 선형 시간 복잡도로 시퀀스 처리의 대부분을 담당합니다 — 네이티브 100만 토큰 컨텍스트 윈도우의 핵심입니다. Transformer 어텐션 레이어는 전략적 간격으로 배치되어 정확한 연관 검색(associative recall)을 수행합니다. 에이전트의 신뢰성 있는 도구 호출에 필수적인 정밀 매칭이 여기서 이루어집니다. MoE 레이어는 추론 비용을 예측 가능하게 유지하면서 모델의 실효 용량을 확장합니다.
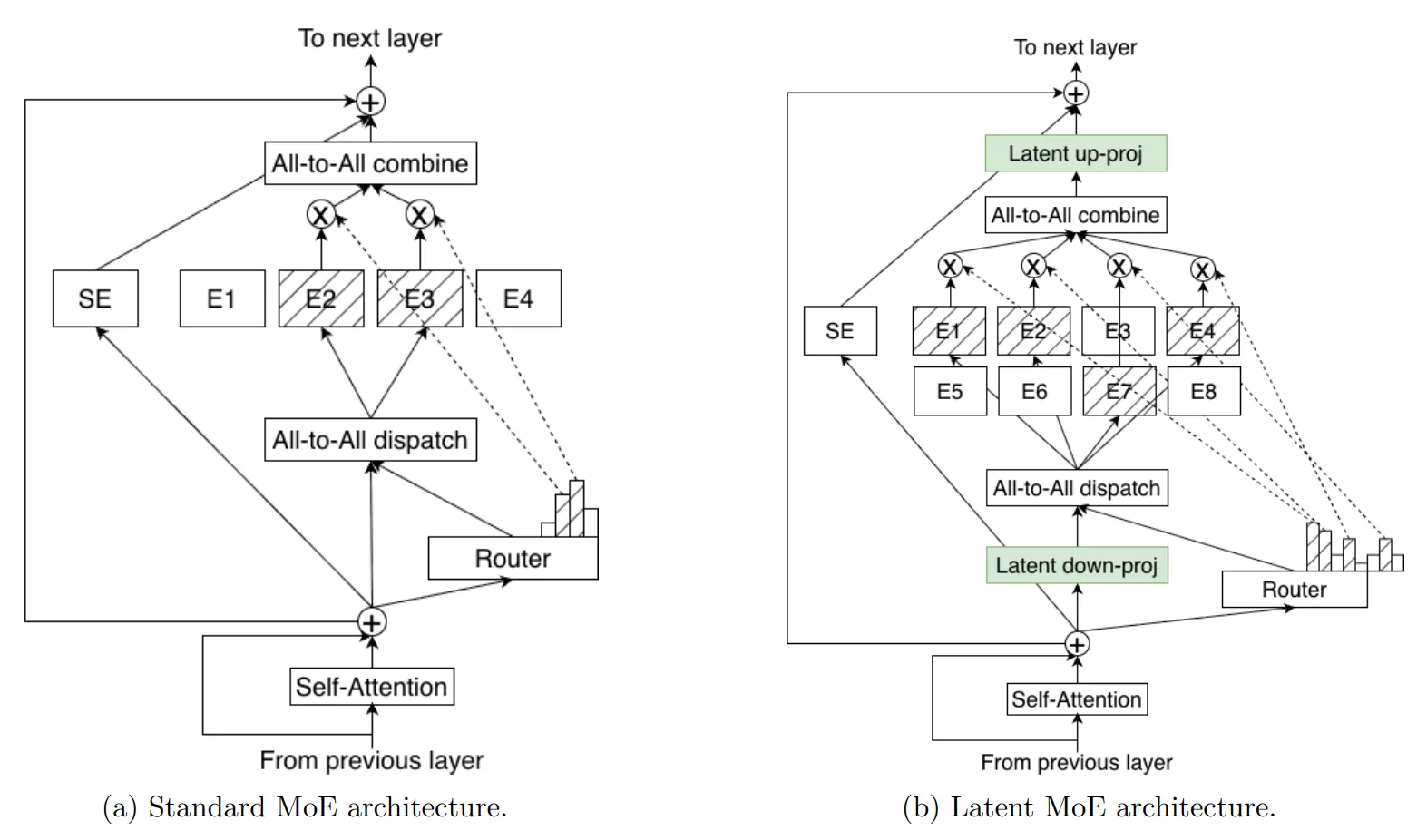
Latent MoE: 같은 비용으로 4배 많은 전문가
가장 주목할 혁신은 NVIDIA의 Latent MoE 기법입니다. 토큰을 전문가(expert)에게 라우팅하기 전에, 토큰 임베딩을 공유 잠재 표현으로 압축합니다. 이 압축-후-라우팅 접근법으로 “동일한 추론 비용으로 4배 많은 전문가 특수화”가 가능해졌습니다. 에이전틱 AI 시스템에 필수적인 다단계 추론(multi-hop reasoning) 작업에서 계산 비용 증가 없이 더 정밀한 특수화를 달성합니다.
Multi-Token Prediction: 구조화된 생성 작업 3배 속도 향상
Nemotron 3는 별도의 드래프트 모델 없이 여러 미래 토큰을 동시에 예측합니다. 이 Multi-Token Prediction(MTP) 방식은 도구 호출, JSON 출력, 코드 생성 같은 구조화된 생성 작업에서 3배의 실시간 속도 향상을 제공하며, 예측 헤드 간 가중치 공유를 통해 훈련 정확도를 약 2.4% 향상시킵니다.
에이전트 관점에서 왜 중요할까요? AI 에이전트가 함수를 호출할 때 구조화된 출력 — 함수명, 파라미터, 닫는 괄호 등 — 을 생성해야 합니다. 기존 오토리그레시브 생성은 토큰 하나씩 처리하지만, MTP는 전체 구조화된 블록을 더 적은 포워드 패스로 예측합니다. 워크플로우당 수백 번의 도구 호출을 실행하는 시스템에서 누적 시간 절감은 상당합니다.
100만 토큰 컨텍스트 윈도우: 마케팅이 아닌 실제 기술
많은 모델이 확장된 컨텍스트 윈도우를 주장하지만, 위치 인코딩 트릭으로 달성하여 긴 범위에서 정확도가 저하됩니다. Nemotron 3의 100만 토큰 컨텍스트는 아키텍처에 네이티브입니다 — Mamba-2 레이어가 선형 시간 복잡도로 긴 시퀀스를 처리하므로, 컨텍스트 길이에 따른 계산 비용이 비례적으로(이차 함수가 아닌) 증가합니다. 실질적으로 에이전트가 약 75만 단어의 컨텍스트를 동시에 유지할 수 있어, 전체 엔터프라이즈 코드베이스 분석, 하루 종일의 대화 히스토리 유지, 수천 페이지 PDF 처리가 RAG 오버헤드 없이 가능합니다.
벤치마크 분석: NVIDIA Nemotron 3의 성능 수치
벤치마크 결과는 설득력이 있습니다. Nemotron 3 Nano는 Artificial Analysis Intelligence Index v3.0에서 52점을 기록하며, 동급 모델 중 최고 처리량 효율을 달성했습니다. Super 변형은 PinchBench에서 85.6%를 기록하여 에이전틱 작업 기준 동급 최고 오픈 모델로 평가받고 있습니다.
진정한 차별화 요소는 정확도만이 아닌 효율성입니다. Nemotron 3 Super는 이전 Nemotron Super 대비 5배 높은 처리량을 제공하며, 총 25조 토큰(고유 10조)으로 훈련되고 21개 환경 구성에서 120만 강화학습 롤아웃을 거쳤습니다.
NVFP4: 네이티브 4비트 훈련이 바꾸는 경제학
Super와 Ultra 변형은 Blackwell 아키텍처에서 NVIDIA의 NVFP4(4비트 부동소수점) 포맷으로 네이티브 훈련됩니다. 사후 양자화가 아닌, 처음부터 4비트 정밀도로 훈련하는 방식으로, H100의 FP8 대비 4배의 메모리 및 컴퓨팅 효율 향상을 달성합니다. 에이전틱 시스템을 대규모로 배포하는 기업에게 이는 이전에 70B Dense 모델도 겨우 구동하던 하드웨어에서 Ultra급(500B 파라미터) 모델을 운영할 수 있다는 의미입니다.
훈련 파이프라인 자체도 방대합니다. 3조 토큰의 사전훈련 데이터셋, 추론·코딩·안전성·다단계 에이전트 작업을 다루는 1,300만 샘플의 사후훈련 데이터. NVIDIA는 다환경 강화학습을 위한 오픈소스 라이브러리인 NeMo Gym과 NeMo RL도 함께 공개했습니다. 이 도구들이 Nemotron 3가 목표 이탈(goal drift) 없이 지속적인 다단계 추론에서 특히 효과적인 이유입니다.
에이전틱 AI 개발에 미치는 영향
에이전틱 AI 분야에는 핵심적인 문제가 있습니다. 대부분의 오픈 모델은 복잡한 다단계 작업에 필요한 정확도를 갖추면 대규모 운영이 비경제적이거나, 빠르고 저렴하면 에이전트에 필수적인 정밀 도구 호출과 장문맥 추론에서 실패합니다. Nemotron 3의 아키텍처는 이 간극을 정면으로 해결합니다.
네이티브 100만 토큰 컨텍스트 윈도우는 에이전트가 전체 코드베이스, 수천 페이지 문서, 확장된 대화 히스토리 등 프로젝트 전체 컨텍스트를 유지할 수 있다는 의미입니다. 컨텍스트 확장 해킹을 사용하는 모델에서 발생하는 정확도 저하 문제가 없습니다. Latent MoE의 전문화된 라우팅과 결합하면, Nemotron 3 기반 에이전트는 기존 오픈 모델보다 더 높은 신뢰도로 복잡한 함수 라이브러리를 탐색할 수 있습니다.
Jensen Huang CEO는 이를 명확히 표현했습니다: “오픈 이노베이션은 AI 발전의 기반입니다. Nemotron을 통해 우리는 개발자들이 투명성과 효율성을 갖추고 대규모 에이전틱 시스템을 구축할 수 있는 오픈 플랫폼을 만들고 있습니다.”
배포 옵션과 엔터프라이즈 생태계
Nemotron 3 Nano는 Hugging Face와 Baseten, DeepInfra, Fireworks AI, Together AI, OpenRouter 등 추론 서비스 제공업체를 통해 즉시 사용 가능합니다. AWS Amazon Bedrock에서 서버리스 배포가 지원되며, Google Cloud, CoreWeave, Crusoe, Microsoft Foundry, Nebius 등이 계획되어 있습니다.
얼리 어답터 명단은 엔터프라이즈 AI의 주요 기업들로 구성됩니다: Accenture, Cadence, CrowdStrike, Cursor, Deloitte, EY, Oracle, Palantir, Perplexity, ServiceNow, Siemens, Synopsys, Zoom. 보안이 민감한 배포 환경에서는 NVIDIA NIM 마이크로서비스 패키징으로 완전한 온프레미스 추론이 가능합니다.
오픈소스 생태계 지원도 충실합니다. vLLM, SGLang, TensorRT-LLM, llama.cpp, LM Studio, Unsloth 모두 호환됩니다. NVIDIA는 모델 가중치와 함께 완전한 사전훈련 레시피, RL 정렬 레시피, 데이터 처리 파이프라인을 공개했습니다.
특히 주목할 것은 오픈 데이터 공약입니다. NVIDIA는 Nemotron 3의 강점이 되는 합성 추론 및 코딩 데이터를 포함한 3조 토큰 규모의 전체 사전훈련 데이터셋을 공개했습니다. 또한 자율 AI 시스템의 안전성과 보안 위험 평가를 위해 설계된 11,000개 워크플로우 트레이스로 구성된 Nemotron Agentic Safety Dataset도 발표했습니다. 에이전트 안전성 감사가 우려되는 기업에게 현재 가용한 가장 포괄적인 오픈 평가 프레임워크입니다.
NeMo Gym 라이브러리도 특별히 주목할 가치가 있습니다. 다단계 도구 호출부터 코드 디버깅, 장기 계획 작업까지 에이전틱 행동 훈련을 위해 특별히 설계된 15개 이상의 강화학습 환경을 제공합니다. NeMo RL과 결합하면 개발자는 커스텀 에이전트 워크플로우에 Nemotron 3 모델을 파인튜닝하고, 기본 모델과 동일한 NIM 마이크로서비스 인프라를 통해 배포할 수 있습니다.
더 큰 그림: NVIDIA의 오픈 모델 전략
Nemotron 3는 단순한 모델 출시가 아닌 전략적 포지셔닝입니다. NVIDIA 하드웨어(Blackwell의 NVFP4)에 최적화된 최첨단 추론 모델을 오픈소스로 공개함으로써, GPU 생태계를 향한 중력장을 형성합니다. 11,000개 트레이스를 포함한 Nemotron Agentic Safety Dataset은 에이전트 시스템 안전성 평가의 참조 표준으로서의 입지를 더욱 공고히 합니다.
에이전틱 AI를 개발하는 기업과 개발자에게 공식은 단순합니다. Nemotron 3는 프로덕션 등급 멀티 에이전트 시스템으로 가는 가장 효율적인 오픈소스 경로를 제공하며, 이를 뒷받침할 아키텍처 혁신(Mamba-Transformer MoE 하이브리드)을 갖추고 있습니다. 이 아키텍처가 중요한지는 이미 답이 나왔습니다 — 문제는 업계의 나머지가 얼마나 빨리 이를 채택하느냐입니다.
AI 기반 자동화 파이프라인 구축이나 에이전틱 AI 워크플로우 통합에 관심이 있으시다면, Sean Kim이 AI 시스템 아키텍처와 자동화 컨설팅을 전문으로 합니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}