
2025년 학생 태블릿 추천: iPad Air M3 vs Galaxy Tab S10 FE vs Pixel Tablet 신학기 완벽 비교
8월 14, 2025
Roland Cloud 2025년 8월: GALAXIAS 1.7 MultiVerb V2부터 Jupiter-8 Legendary v2까지 총정리
8월 15, 2025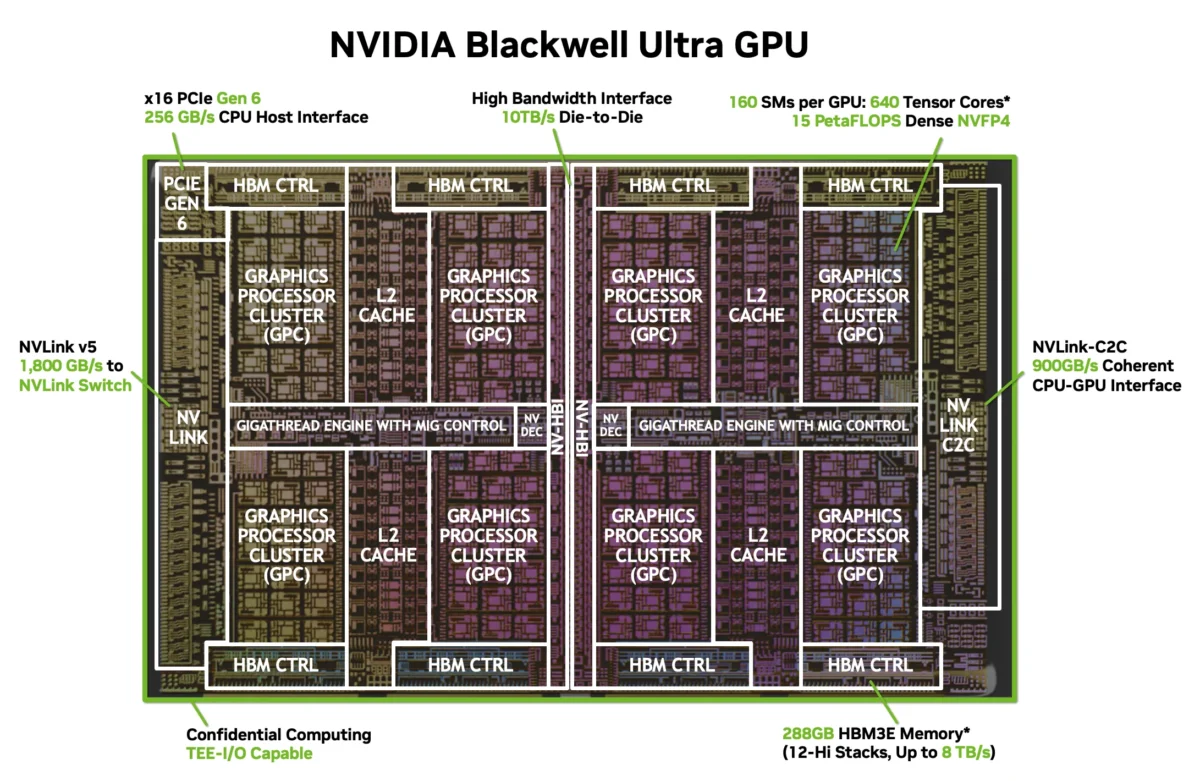
NVIDIA Blackwell Ultra가 드디어 Hot Chips 2025에서 그 전모를 드러냈습니다. 2080억 개의 트랜지스터, 15페타플롭스의 NVFP4 연산 처리량, 최대 1,400W의 전력 소모 — 이 숫자들만 봐도 단순한 세대 교체가 아니라는 것을 알 수 있습니다. 스탠포드에서 열린 이번 컨퍼런스에서 NVIDIA가 공개한 GB300 아키텍처의 모든 것을 분석합니다.
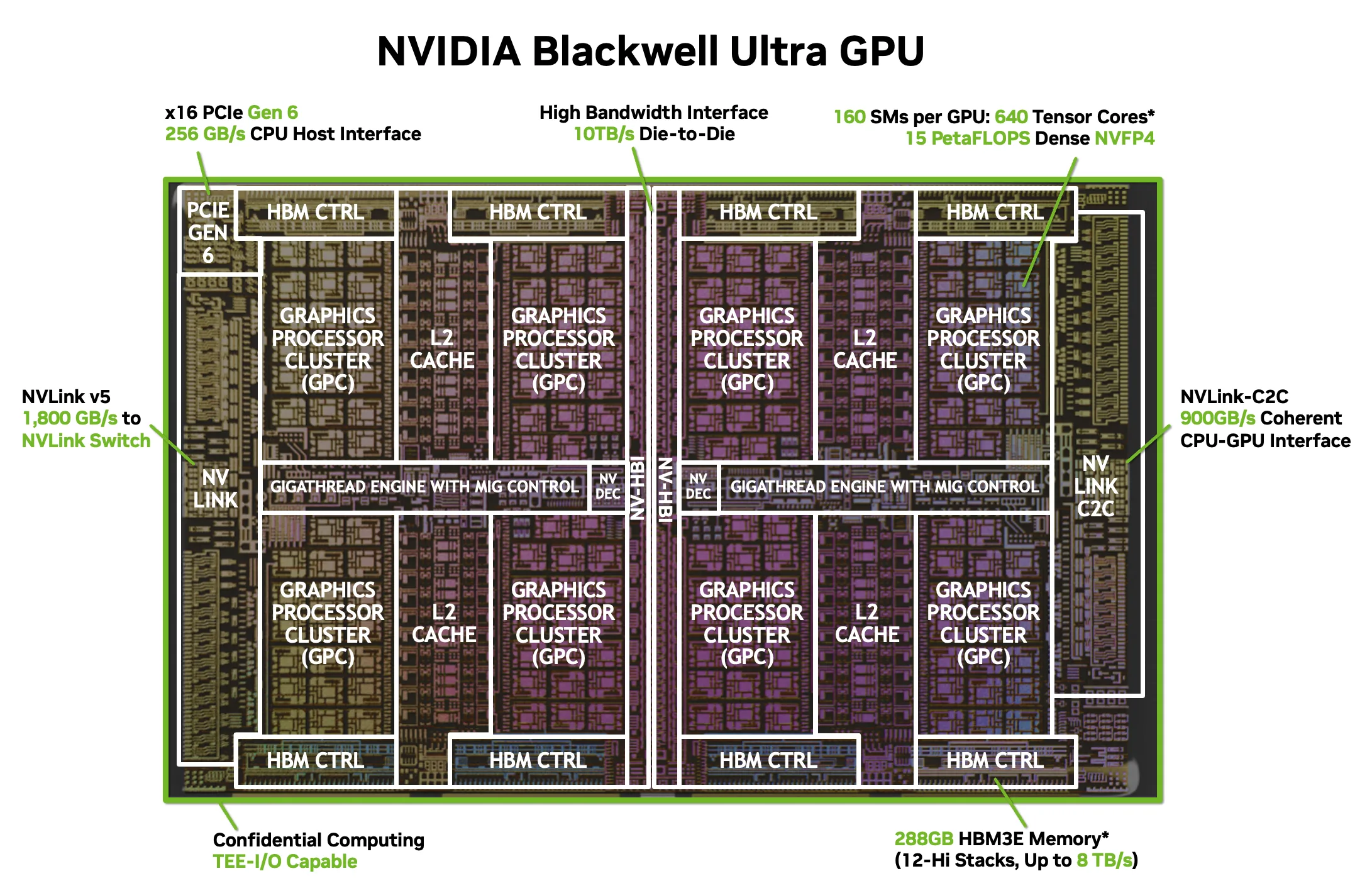
NVIDIA Blackwell Ultra 아키텍처: 듀얼 레티클의 괴물
GB300 GPU의 핵심은 TSMC 4NP 공정으로 제조된 듀얼 레티클 다이입니다. 두 개의 거대한 실리콘 다이가 NVIDIA 독자 기술인 NV-HBI(High Bandwidth Interface)로 연결되어 있으며, 이 인터페이스의 대역폭은 무려 10 TB/s에 달합니다. 사실상 하나의 모놀리식 칩처럼 작동하면서도, 현재 리소그래피의 레티클 한계를 우회하는 영리한 설계입니다.
스펙을 살펴보면 AI 컴퓨팅 엔지니어의 위시리스트 그 자체입니다. 160개의 스트리밍 멀티프로세서(SM)에 20,480개의 CUDA 코어, 640개의 5세대 텐서 코어가 탑재되어 있습니다. 텐서 코어는 NVIDIA의 새로운 NVFP4 포맷에서 15페타플롭스, FP8 밀집 연산에서 5페타플롭스, FP8 희소 연산에서 10페타플롭스를 달성합니다. 기존 Blackwell 아키텍처 대비 밀집 NVFP4 처리량은 1.5배, 어텐션 연산은 2배 향상된 수치입니다.
NVFP4: AI 추론의 경제학을 바꾸는 새로운 정밀도 포맷
이번 아키텍처에서 가장 주목할 혁신은 NVFP4(4비트 부동소수점) 포맷의 도입입니다. 단순히 클록당 더 많은 연산을 수행하는 것이 아니라, 대규모 언어 모델 추론의 메모리 경제학 자체를 바꾸는 기술입니다. NVFP4는 FP8 대비 메모리 사용량을 1.8배 줄여, 기존에 여러 GPU가 필요했던 모델을 단일 Blackwell Ultra에서 구동할 수 있게 합니다.
실질적 영향은 상당합니다. 700억 파라미터 모델의 경우 NVFP4에서 약 35GB의 메모리만 소모하는데, FP8에서는 63GB가 필요합니다. GB300의 288GB HBM3e 용량 안에 여유 있게 들어가는 수준입니다. AI 추론, 코드 생성, 멀티턴 대화와 같은 추론 중심 워크로드에서 이것은 근본적인 변화입니다. NVIDIA는 GB300 NVL72 시스템이 Hopper 세대 하드웨어 대비 50배의 AI 팩토리 출력을 제공한다고 발표했으며, NVFP4 포맷이 그 핵심 동력입니다.
288GB HBM3e와 8 TB/s: 연산을 따라잡는 메모리
Blackwell Ultra는 8개의 12-Hi HBM3e 스택으로 총 288GB의 메모리를 탑재하며, 통합 대역폭은 8 TB/s에 달합니다. AI 추론 워크로드를 괴롭히던 메모리 벽(Memory Wall) 문제를 정면으로 해결하는 수치입니다. MoE(Mixture-of-Experts) 모델을 실행하거나 수천 개의 동시 추론 요청을 처리할 때, 병목은 보통 연산력이 아니라 메모리 대역폭이기 때문입니다.
288GB 용량은 새로운 MIG(Multi-Instance GPU) 구성도 가능하게 합니다: 2x 140GB, 4x 70GB, 또는 7x 34GB 인스턴스로 분할할 수 있습니다. 단일 GPU를 여러 테넌트에 나누면서도 격리와 성능 예측성을 유지해야 하는 클라우드 서비스 제공자에게 핵심적인 유연성입니다.
NVLink 5와 576-GPU 패브릭
NVIDIA의 NVLink 인터커넥트가 Blackwell Ultra와 함께 5세대에 진입했습니다. GPU당 18개의 NVLink 5 링크가 각각 100 GB/s로 작동하여 양방향 총 1.8 TB/s의 대역폭을 제공합니다. 칩 간 NVLink 연결은 900 GB/s이며, 호스트 연결을 위한 PCIe Gen 6 x16도 256 GB/s를 지원합니다.
진정한 강점은 토폴로지에 있습니다. NVLink 5는 최대 576개의 GPU를 논블로킹 패브릭으로 연결할 수 있습니다. 576개의 Blackwell Ultra GPU가 혼잡 없이 풀 대역폭으로 통신하는 것 — 차세대 프론티어 모델 훈련에 필요한 바로 그 규모입니다.
GB300 NVL72: 랙 스케일 AI 슈퍼컴퓨터
GB300 NVL72는 이 모든 구성 요소가 하나의 랙 스케일 시스템으로 통합된 결과물입니다. 72개의 Blackwell Ultra GPU와 36개의 Grace CPU가 130 TB/s NVLink 대역폭으로 연결되어, 밀집 FP4 기준 1.1엑사플롭스의 연산을 제공합니다. 전체 시스템은 완전한 수냉식이며, Tom’s Hardware에 따르면 냉각 시스템만 랙당 약 5만 달러가 소요되며, 차세대 NVL144 랙은 5만 6천 달러까지 올라갈 것으로 예상됩니다.
성능을 맥락에서 보면, 단일 NVL72 랙이 불과 3년 전 데이터센터 전체 층보다 더 많은 AI 연산을 제공합니다. NVIDIA는 이를 ‘AI 팩토리’ — 훈련된 모델과 추론 용량을 생산하는 전용 시설 — 의 핵심 빌딩 블록으로 포지셔닝하고 있습니다.

어텐션 가속기: 가장 중요한 곳에서 2배 성능
상대적으로 덜 언급되지만 결정적으로 중요한 개선 사항은 향상된 어텐션 가속기입니다. Blackwell Ultra는 기존 Blackwell 대비 2배의 어텐션 성능을 제공하며, 10.7 테라엑스포넨셜/초로 평가됩니다. 트랜스포머 기반 모델이 지배하는 현재, 어텐션 메커니즘은 모든 LLM 추론 패스의 연산 병목입니다. 이 개선은 더 빠른 토큰 생성과 실시간 AI 애플리케이션의 지연 시간 감소로 직결됩니다.
NVFP4 포맷, 확장된 HBM3e 용량과 결합되어, 어텐션 가속은 Blackwell Ultra를 OpenAI의 o-시리즈, Google의 Gemini와 같은 추론형 모델에 특히 적합하게 만듭니다. 이러한 모델들은 기존 LLM보다 쿼리당 훨씬 더 많은 연산을 수행하므로, 메모리 대역폭과 어텐션 처리량 모두에 극도로 민감합니다.
Hot Chips 2025: GPU를 넘어서
NVIDIA의 Hot Chips 2025 참가는 Blackwell Ultra 공개를 넘어 광범위했습니다. ConnectX-8 SuperNIC, 실리콘 포토닉스를 활용한 코패키지드 옵틱스, AI 슈퍼팩토리를 위한 Spectrum-XGS 이더넷 플랫폼도 함께 발표했습니다. 데스크톱급 AI 시스템인 DGX Spark GB10 아키텍처와 Blackwell 실리콘에서 구동되는 뉴럴 렌더링 기능에 대한 세션도 진행되었습니다.
올해 Hot Chips에서 인상적인 점은 총체적 접근법입니다. NVIDIA는 단순히 더 빠른 GPU를 만드는 것이 아니라, 칩에서 랙, 네트워크 패브릭, 소프트웨어 스택에 이르는 전체 생태계를 구축하고 있습니다. 개별 부품에서 격차를 좁히더라도 시스템 수준에서 경쟁자가 따라잡기 점점 더 어려워지는 수직 통합의 수준입니다.
Blackwell Ultra vs. Hopper vs. Blackwell: 세대별 비교
세 세대의 핵심 지표를 비교해 보겠습니다:
- NVFP4 처리량: Blackwell Ultra는 Hopper 대비 7.5배 (Hopper는 FP4 네이티브 미지원)
- 밀집 NVFP4 vs. Blackwell: 세대 대 세대 1.5배 향상
- 어텐션 성능: 기존 Blackwell 대비 2배
- 메모리: 288GB HBM3e, 8 TB/s (Blackwell의 192GB에서 증가)
- AI 팩토리 출력: Hopper 기반 시스템 대비 50배 (NVIDIA 벤치마크)
- TDP: 최대 1,400W (NVL72 배치 시 수냉 필수)
Hopper 대비 50배 AI 팩토리 향상은 맥락이 필요합니다. 이것은 단일 칩 지표가 아니라 NVFP4 정밀도, NVLink 5 대역폭, NVL72 랙 아키텍처가 함께 작동하는 시스템 수준 비교입니다. 개별 칩의 추론 워크로드 개선은 약 7-8배에 가까우며, 이것만으로도 대단한 세대별 향상입니다.
AI 인프라 시장에 미치는 영향
NVIDIA Blackwell Ultra 아키텍처는 명확한 메시지를 전달합니다: AI 인프라 군비 경쟁은 둔화되는 것이 아니라 가속되고 있다는 것입니다. AWS, Azure, GCP, Oracle 등 모든 주요 클라우드 제공자가 GB300 NVL72 할당을 확보하기 위해 경쟁하고 있으며, Hopper와 Blackwell 시대를 특징지었던 공급 제약이 반복될 가능성이 높습니다.
AI 인프라 배치를 계획하는 조직에게 Hot Chips 2025의 핵심 교훈은 이것입니다: Blackwell Ultra는 단순히 더 빠른 것이 아니라, 새로운 워크로드 카테고리를 가능하게 하는 아키텍처적으로 다른 칩입니다. NVFP4 정밀도, 2배 향상된 어텐션 성능, 랙 스케일 NVLink 패브릭의 조합은 Hopper에서는 경제적으로 비실용적이었던 워크로드를 Blackwell Ultra에서 실현 가능하게 만듭니다. 그리고 이 변화가 아직 상상조차 하지 못한 차세대 AI 애플리케이션의 물결을 이끌 것입니다.
AI 인프라 결정 — GPU 선택부터 배포 아키텍처까지 — 깊은 기술 이해가 필요합니다. AI 하드웨어 전략에 대한 전문가 가이드가 필요하시다면 상담을 요청해 주세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}