UJAM Groovemate Latigo 리뷰: 자미로콰이 퍼커셔니스트가 녹음한 460개 라틴 프레이즈, $39의 진짜 가치
4월 3, 2026
GitHub Copilot 데이터 훈련, 4월 24일부터 내 코드가 AI 학습에 쓰인다: 지금 당장 Opt-Out 해야 하는 7가지 이유
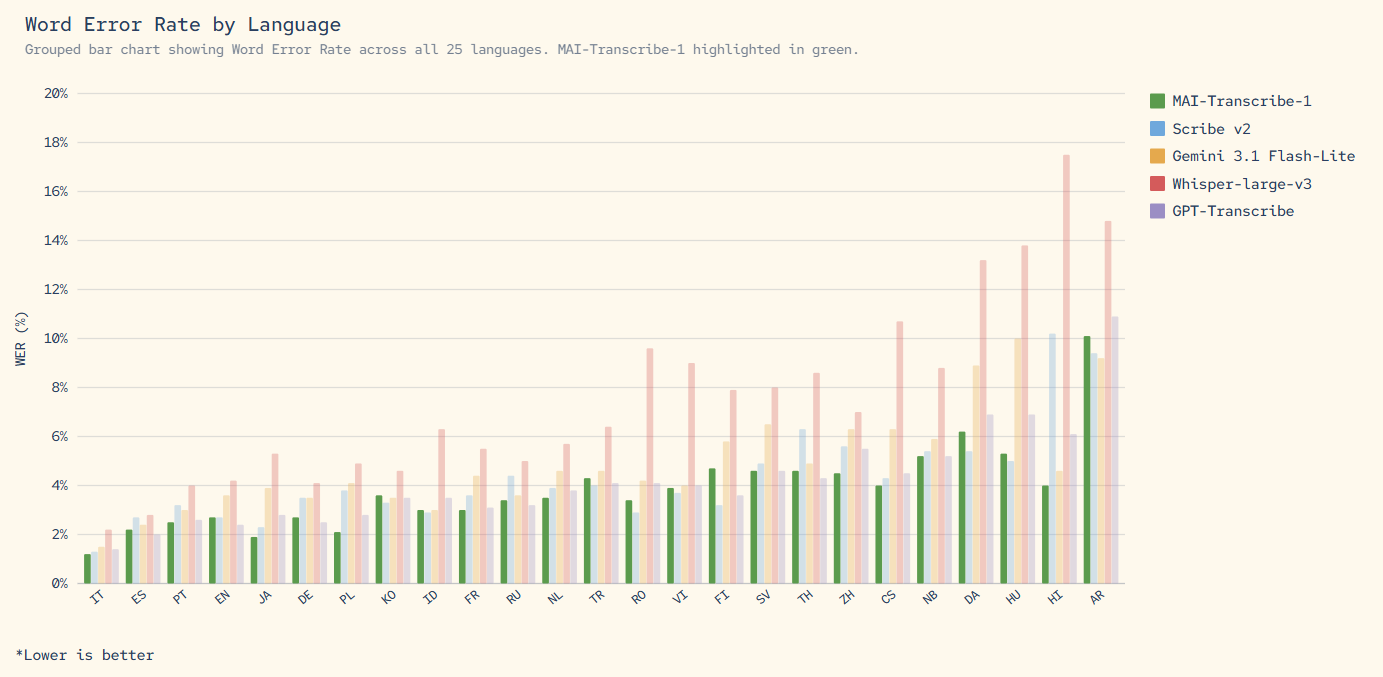
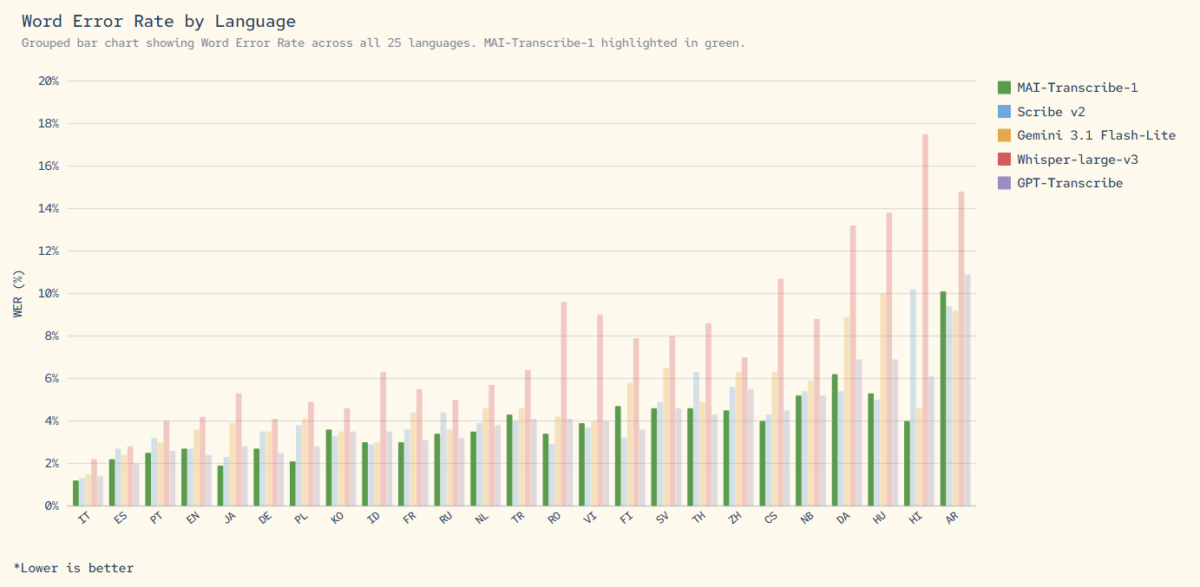
4월 3, 2026OpenAI의 Whisper가 음성 인식의 절대 강자라고 믿고 계셨다면, 어제 그 믿음이 산산조각 났습니다. Microsoft가 2026년 4월 2일, 자체 개발한 Microsoft MAI 모델 3종을 동시에 공개했는데 — MAI-Transcribe-1이 FLEURS 벤치마크 25개 언어 전부에서 Whisper-large-v3를 이긴 겁니다. 전부요.

Microsoft MAI 모델, 왜 지금 나왔나
이번 발표의 핵심은 단순한 신제품 출시가 아닙니다. Microsoft가 OpenAI에 수십억 달러를 투자하면서도 자체 파운데이션 모델 라인업을 구축하겠다는 전략적 선언입니다. VentureBeat가 보도한 것처럼, 이번 출시는 OpenAI와 Google을 겨냥한 ‘직격탄’입니다.
TechCrunch는 이를 Microsoft의 ‘OpenAI 의존도 탈피 전략’의 일환으로 분석했습니다. 파트너에게만 의존하지 않고, 음성·이미지·텍스트 전 영역에서 자체 모델로 서비스를 운영하겠다는 것이죠. 세 모델 모두 Azure AI Foundry와 MAI Playground에서 즉시 사용 가능합니다.
타이밍도 의미심장합니다. Google이 Gemini 3.1 시리즈로 멀티모달 AI 시장을 공격적으로 확장하고 있고, OpenAI는 GPT-5 출시를 앞두고 있는 시점입니다. Microsoft가 이 시기에 음성·이미지 전 영역의 자체 모델을 내놓은 건, 플랫폼 전쟁에서 ‘자체 무기’를 확보하겠다는 의지의 표현입니다. Azure 고객 입장에서는 이제 OpenAI API와 Microsoft MAI 모델을 동일한 인프라에서 비교·선택할 수 있게 되었습니다.
MAI-Transcribe-1: Whisper를 25개 언어에서 압도한 음성 인식
가장 눈에 띄는 모델은 단연 MAI-Transcribe-1입니다. FLEURS 벤치마크에서 25개 언어 평균 WER(Word Error Rate) 3.8%를 기록했습니다. OpenAI의 Whisper-large-v3는 물론, Google의 Gemini 3.1 Flash와 GPT-Transcribe까지 모든 경쟁 모델을 넘어섰습니다. 특히 핵심 11개 언어에서는 1위를 차지했습니다.
성능만 좋은 게 아닙니다. Microsoft 공식 발표에 따르면, 이전 Azure Fast 모델 대비 2.5배 빠르면서도 GPU 비용은 약 50% 절감했습니다. 가격은 시간당 $0.36으로, MP3, WAV, FLAC 파일을 최대 200MB까지 처리할 수 있습니다.
Whisper-large-v3와 직접 비교하면 차이가 더 명확해집니다. Whisper는 영어에서는 강하지만, 아시아·아프리카 언어에서 에러율이 크게 올라가는 문제가 있었습니다. MAI-Transcribe-1은 이런 약점을 정확히 공략해서, 한국어·일본어·아랍어 같은 비라틴 문자 언어에서도 일관된 정확도를 보여줍니다. Google의 Gemini 3.1 Flash가 범용 멀티모달 모델로서 트랜스크립션도 지원하지만, 전용 모델인 MAI-Transcribe-1의 정확도와 속도를 따라가기 어렵습니다.
실제 현장에서 이 모델이 가장 빛날 시나리오를 생각해 보면: 글로벌 미디어 기업의 다국어 콘텐츠 자막 작업, 콜센터의 고객 통화 자동 트랜스크립션, 대학과 온라인 교육 플랫폼의 강의 자막 생성, 법률·의료 분야의 회의록 자동 작성 등이 있습니다. 특히 다국어 팟캐스트나 국제 컨퍼런스 실시간 자막처럼, 여러 언어가 혼재하는 환경에서 일관된 정확도가 필요한 경우 MAI-Transcribe-1의 강점이 극대화됩니다.
MAI-Voice-1: 1초 만에 60초 오디오, 음성 복제까지
텍스트-투-스피치 시장에서 ElevenLabs와 Resemble AI가 주도하고 있었는데, MAI-Voice-1이 판을 흔들 수 있는 수치를 들고 나왔습니다. 단일 GPU에서 1초도 안 걸려 60초 분량의 고품질 오디오를 생성합니다. 수 초 분량의 음성 샘플만으로 커스텀 보이스를 생성하는 음성 복제 기능도 포함되어 있습니다.
가격은 100만 캐릭터당 $22입니다. 긴 콘텐츠에서도 화자의 정체성을 유지하는 것이 특징인데, 이는 오디오북, e러닝, 팟캐스트 제작에서 큰 차별점이 될 수 있습니다.
경쟁사와 비교하면, ElevenLabs의 장점은 감정 표현과 다양한 보이스 라이브러리입니다. Resemble AI는 실시간 음성 변환에 특화되어 있고요. MAI-Voice-1의 차별점은 속도와 비용입니다. 60초 오디오를 1초 이내에 생성하는 건, 대량 콘텐츠를 빠르게 처리해야 하는 엔터프라이즈 고객에게 결정적인 장점입니다. 게다가 Azure 인프라에서 바로 사용할 수 있어서, 이미 Microsoft 생태계를 쓰는 기업이라면 별도의 API 통합 없이 바로 도입할 수 있습니다.
실제 활용 사례를 생각하면: 글로벌 e러닝 플랫폼이 하나의 강의를 20개 언어로 음성 변환하는 로컬라이제이션, 뉴스 미디어가 텍스트 기사를 음성 뉴스로 자동 변환하는 오디오 퍼스트 전략, 게임 개발사가 NPC 대화를 대량으로 생성하는 작업, 접근성을 위한 웹사이트 콘텐츠 음성 변환 등이 바로 적용 가능한 영역입니다.
MAI-Image-2: Arena.ai 3위, DALL-E·Imagen과 직접 경쟁
MAI-Image-2는 텍스트-투-이미지 모델로, Arena.ai 리더보드에서 모델 패밀리 기준 3위를 차지하고 있습니다. 이전 세대 대비 최소 2배 빠른 생성 속도를 제공하며, 가격은 입력 토큰 100만 개당 $5, 출력 토큰 100만 개당 $33입니다.
OpenAI의 DALL-E와 Google의 Imagen을 직접 겨냥한 제품인데, Microsoft Foundry 생태계 안에서 음성 인식·음성 생성·이미지 생성을 한 곳에서 처리할 수 있다는 것이 플랫폼 전략의 핵심입니다.
현재 이미지 생성 시장에서 DALL-E 3는 텍스트 렌더링과 프롬프트 충실도에서 강점이 있고, Google Imagen 3는 포토리얼리즘과 디테일에서 앞서고 있습니다. Midjourney는 여전히 아티스틱한 스타일에서 독보적이고요. MAI-Image-2가 Arena.ai 3위를 차지했다는 건, 범용 품질에서는 이미 최상위권이라는 의미입니다. 다만 진짜 경쟁력은 개별 이미지 품질보다 Azure 생태계 통합에 있습니다. 하나의 파이프라인에서 텍스트 생성, 이미지 생성, 음성 합성을 모두 처리할 수 있다면, 콘텐츠 제작 자동화의 효율성이 비약적으로 올라갑니다.
가격 비교: 경쟁 대비 어디에 위치하나
현실적으로 가장 중요한 건 비용입니다. 현재 공개된 가격을 정리하면:
- MAI-Transcribe-1: $0.36/시간 — Whisper API 대비 GPU 비용 약 50% 절감
- MAI-Voice-1: $22/100만 캐릭터 — ElevenLabs의 엔터프라이즈 요금과 경쟁 가능한 수준
- MAI-Image-2: $5/100만 입력 토큰, $33/100만 출력 토큰
특히 Transcribe의 가격 경쟁력이 눈에 띕니다. 대량의 오디오 파일을 처리하는 미디어 기업이나 교육 플랫폼 입장에서 GPU 비용 50% 절감은 연간 수만 달러의 차이를 만들 수 있습니다.
구체적으로 계산해 보겠습니다. 하루 100시간 분량의 오디오를 트랜스크립션하는 미디어 기업이 있다고 가정하면, MAI-Transcribe-1 기준 일 비용은 $36, 월 비용은 약 $1,080입니다. 기존 GPU 기반 Whisper 파이프라인 대비 50% 절감이면 연간 약 $13,000의 비용 차이가 발생합니다. 여기에 2.5배의 속도 향상으로 처리 시간도 단축되니, 인프라 운영 비용까지 고려하면 실질적 절감 효과는 더 클 수 있습니다. ElevenLabs의 엔터프라이즈 TTS 요금이 100만 캐릭터당 약 $24~$30 수준인 점을 감안하면, MAI-Voice-1의 $22는 가격 면에서 확실한 우위를 점하고 있습니다.
Sean’s Take: 28년차 오디오 엔지니어의 관점
28년간 음악과 오디오 업계에서 일하면서, 음성 인식 기술의 변천을 직접 겪어왔습니다. 불과 몇 년 전만 해도 다국어 트랜스크립션은 전문 서비스를 고용하거나 수작업으로 할 수밖에 없었습니다. Whisper가 등장하면서 판이 바뀌었고, 이제 Microsoft MAI 모델이 그 판을 한 단계 더 뒤집고 있습니다.
제가 특히 주목하는 건 MAI-Voice-1의 음성 복제 기능입니다. 스튜디오에서 성우 작업을 할 때, 특정 톤이나 스타일을 유지하면서 대량의 콘텐츠를 생성해야 하는 경우가 많습니다. 수 초 분량의 샘플로 음성 복제가 가능하다면, 로컬라이제이션이나 e러닝 콘텐츠 제작 워크플로우가 근본적으로 달라질 겁니다. 제가 운영하는 오디오 자동화 파이프라인에서도, 기존 ElevenLabs API 대신 MAI-Voice-1을 테스트해볼 계획입니다.
MAI-Transcribe-1에 대해서도 한 마디 하자면, 저는 현재 여러 언어의 오디오 콘텐츠를 자동으로 처리하는 시스템을 구축해서 쓰고 있는데, 한국어·일본어 같은 비라틴 문자 언어에서 Whisper의 에러율이 체감상 높았습니다. MAI-Transcribe-1이 이런 언어에서도 일관된 정확도를 보여준다면, 다국어 콘텐츠 워크플로우의 병목이 하나 해소되는 셈입니다. 벤치마크 수치와 실제 프로덕션 환경의 차이를 직접 확인하는 게 다음 단계입니다.
다만 냉정하게 봐야 할 점도 있습니다. Microsoft가 OpenAI에 투자하면서 동시에 경쟁 모델을 내놓는 건, 파트너십의 복잡한 역학을 보여줍니다. Whisper를 쓰던 기업들이 MAI-Transcribe-1으로 갈아탈 유인은 충분하지만, OpenAI도 가만히 있지 않을 겁니다. 음성 AI 시장의 진짜 승자는 올해 하반기에 결정될 거라고 봅니다. 중요한 건, 이 경쟁 덕분에 개발자와 크리에이터가 더 좋은 도구를 더 낮은 가격에 쓸 수 있게 되었다는 겁니다.
이번 MAI 모델 출시는 단순한 제품 발표가 아니라, AI 업계의 세력 판도를 재편하는 신호탄입니다. 음성 인식, 음성 생성, 이미지 생성 — 세 영역 모두에서 Microsoft가 자체 모델로 경쟁하겠다는 건, 개발자와 크리에이터에게 더 많은 선택지와 더 낮은 비용을 의미합니다. 특히 오디오 업계에서 일하는 사람이라면, MAI-Transcribe-1과 MAI-Voice-1은 당장 테스트해볼 가치가 있습니다.
AI 기반 오디오 파이프라인 구축이나 자동화 시스템 설계에 관심이 있으시다면, 28년 경력의 전문가와 상담해 보세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}
{kind=link}