
Steinberg Dorico 6 리뷰: AI 교정 패널이 바꿔놓은 악보 제작의 기준 — 100개 이상의 오류를 자동 감지
2월 9, 2026
NVIDIA Blackwell B300 양산 본격화: 288GB HBM3e로 AI 서버 시장 판도가 바뀐다
2월 10, 2026
GPU 1장에 올라가는 17B 파라미터 모델이 GPT급 성능을 낸다면 믿으시겠습니까? Meta Llama 4 Scout가 정확히 그 일을 해냈습니다. 2025년 4월 출시 이후 불과 10개월, 엔터프라이즈 오픈소스 AI 채택률이 23%에서 67%로 치솟았고, 기업들은 독점 API 대비 최대 80%의 비용을 절감하고 있습니다.
Meta Llama 4 Scout가 게임 체인저인 이유
Meta Llama 4 Scout의 핵심은 Mixture-of-Experts(MoE) 아키텍처에 있습니다. 전체 파라미터는 109B이지만, 실제 추론 시 활성화되는 파라미터는 17B에 불과합니다. 16개 전문가 네트워크 중 필요한 것만 선택적으로 가동하는 방식이죠. 이 설계 덕분에 INT4 양자화 적용 시 약 55GB VRAM만으로 단일 NVIDIA H100 GPU 한 장에서 구동이 가능합니다.
더 놀라운 것은 컨텍스트 윈도우입니다. Meta Llama 4 Scout는 오픈소스 모델 최초로 1000만(10M) 토큰 컨텍스트 윈도우를 지원합니다. 800만 토큰까지 95% 이상의 검색 정확도를 유지하고, 1000만 토큰에서도 needle-in-a-haystack 테스트에서 89%의 정확도를 기록했습니다. 이는 수천 페이지의 법률 문서, 재무 보고서, 의료 기록을 한 번에 처리할 수 있다는 의미입니다.
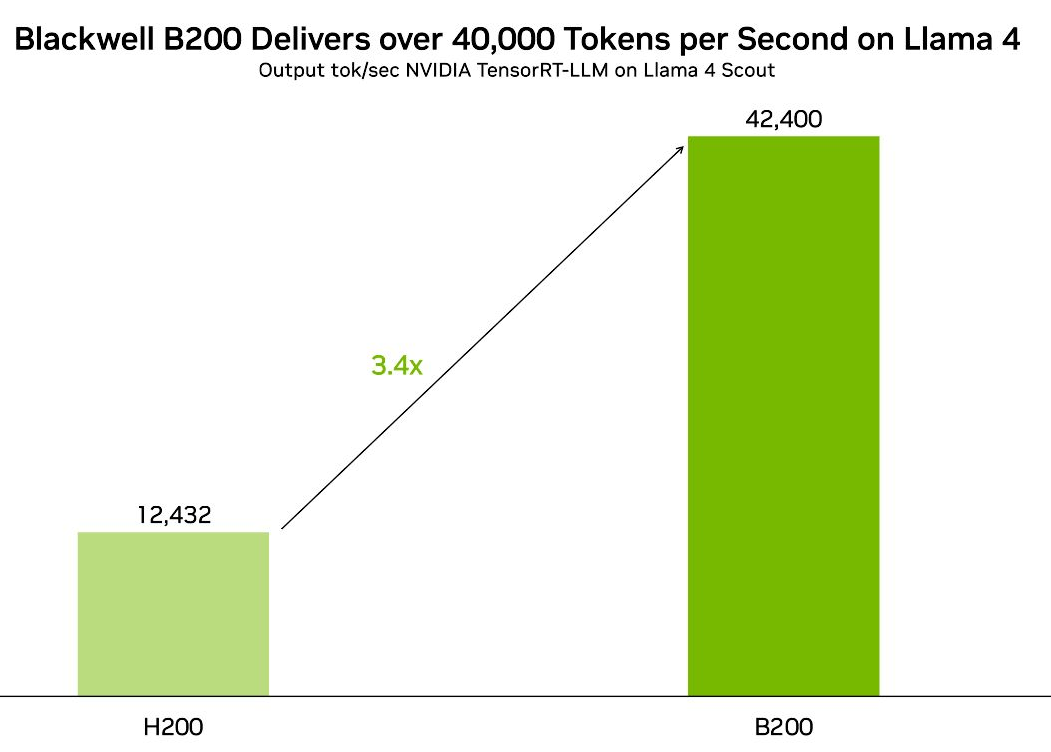
벤치마크로 본 Meta Llama 4 Scout 실력
숫자는 거짓말을 하지 않습니다. Llama 4 Scout는 MMLU-Pro에서 74.3%, HumanEval에서 79.6%를 달성했습니다. 이는 같은 파라미터 규모의 경쟁 모델들을 크게 앞서는 수치이며, 일부 벤치마크에서는 GPT-5.3이나 Claude Opus 4.6과 같은 독점 모델에 근접하는 성능을 보여줍니다. MoE 아키텍처가 효율성과 성능 사이의 트레이드오프를 극적으로 줄인 결과입니다.
특히 산업별 성능 향상이 두드러집니다. 법률 분야에서는 조항 추출 정확도가 22% 향상되었고, 금융 분야에서는 엔티티 추출 성능이 25% 개선되었습니다. 의료 분야에서는 HIPAA 컴플라이언스를 유지하면서 의료 엔티티 인식 정확도가 19% 높아졌습니다. 이러한 수치는 단순한 범용 벤치마크가 아니라, 실제 엔터프라이즈 워크로드에서 검증된 결과라는 점에서 의미가 큽니다.
비용 경제학: 왜 기업들이 움직이는가
엔터프라이즈 AI 도입의 가장 큰 장벽은 항상 비용이었습니다. 월 5억 토큰 이상을 처리하는 기업 기준으로, Meta Llama 4 Scout 자체 호스팅은 독점 API 대비 60-80%의 비용 절감을 실현합니다. 클라우드 추론 서비스를 이용하더라도 비용 이점은 확실합니다. Together AI는 입력 $0.10/M, 출력 $0.30/M, Fireworks AI는 입력 $0.12/M, 출력 $0.35/M으로 서비스를 제공하며, AWS Bedrock에서도 온디맨드로 이용 가능합니다.
파인튜닝 비용도 혁신적입니다. LoRA 기법을 활용하면 $50-200의 비용으로 15-25%의 정확도 향상을 달성할 수 있습니다. 기존에 수만 달러가 소요되던 커스텀 모델 구축이 이제는 스타트업도 감당할 수 있는 수준이 된 것입니다. 이것이 오픈소스 AI 시장이 전년 대비 340% 성장한 배경입니다.
구체적인 비용을 비교해 보겠습니다. 월 10억 토큰을 처리하는 기업이 독점 API를 사용하면 월 $15,000-$30,000 수준의 비용이 발생합니다. 같은 워크로드를 Together AI의 Scout 엔드포인트로 처리하면 $1,500-$3,000으로 줄어듭니다. 자체 호스팅의 경우 초기 인프라 투자를 상각하면 비용은 더욱 낮아집니다. 이러한 비용 구조의 변화가 10개월 만에 엔터프라이즈 오픈소스 AI 채택률을 23%에서 67%로 끌어올린 근본적인 동력입니다.
실전 배포 전략: 단일 GPU에서 하이브리드까지
Meta Llama 4 Scout의 가장 매력적인 점은 배포 유연성입니다. 단일 H100 GPU에서 INT4 양자화로 초당 55-75 토큰의 추론 속도를 달성합니다. NVIDIA의 TensorRT-LLM 최적화와 NIM 통합을 활용하면 프로덕션 환경에서의 배포도 검증된 베스트 프랙티스를 따를 수 있습니다.
현재 업계에서 주목받는 배포 패턴은 하이브리드 접근법입니다. 전체 쿼리의 90-95%는 Scout로 처리하고, 복잡한 추론이 필요한 5-10%만 독점 API(GPT, Claude 등)로 라우팅하는 방식입니다. 이 전략으로 비용은 자체 호스팅 수준으로 유지하면서, 엣지 케이스에서의 품질도 보장할 수 있습니다.
- Tier 1 (엣지/디바이스): Scout INT4 — 단일 GPU, 낮은 레이턴시, 데이터 보안
- Tier 2 (복잡한 추론): Maverick 또는 독점 API — 고난이도 작업 전담
- Tier 3 (대규모 배치): Scout 클러스터 — 대량 문서 처리, 데이터 파이프라인

Meta의 빅 픽처: 1.5M GPU와 MTIA v3
Meta Llama 4 Scout의 성공은 단독 이벤트가 아닙니다. Meta는 2026년 초까지 150만 GPU 유닛 이상을 확보했고, 3nm 공정의 자체 AI 칩 MTIA v3도 투입했습니다. 이는 Meta가 ‘AI의 Linux’를 자처하며 오픈소스 생태계를 장기적으로 키우겠다는 전략의 일환입니다. 2조 파라미터 규모의 Llama 4 Behemoth MoE 모델은 아직 프리뷰 단계이지만, 출시되면 또 한 번 판도를 바꿀 것으로 예상됩니다.
독점 AI 제공업체들은 이미 가격 인하 압박을 받고 있습니다. 오픈소스가 네이티브 멀티모달까지 지원하면서, 독점 모델의 가격 프리미엄을 정당화하기가 점점 어려워지고 있습니다. 기업 입장에서는 이제 ‘오픈소스냐 독점이냐’가 아니라, ‘어떤 비율로 섞을 것이냐’가 핵심 질문이 되었습니다.
결론: 10개월이 바꾼 AI 경제의 공식
Meta Llama 4 Scout가 증명한 것은 명확합니다. 오픈소스 AI가 더 이상 ‘저렴하지만 부족한’ 대안이 아니라, 엔터프라이즈급 성능과 경제성을 동시에 갖춘 주류 선택지가 되었다는 것입니다. 17B 활성 파라미터, 1000만 토큰 컨텍스트, 단일 GPU 배포 — 이 세 가지 조합이 만들어낸 비용 구조의 변화는 되돌릴 수 없습니다.
기업의 AI 전략을 수립하거나 기존 파이프라인의 비용 최적화를 고민하고 계시다면, 오픈소스 모델 기반의 하이브리드 아키텍처가 2026년의 정답일 수 있습니다. 자체 호스팅 LLM 구축부터 클라우드 추론 서비스 비교까지, 실전 도입에 필요한 기술적 판단이 필요한 시점입니다.
AI 인프라 구축, LLM 배포 최적화, 자동화 파이프라인 설계가 필요하시다면 Sean Kim에게 문의해 주세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}