Google Pixel 10 Pro 리뷰: Tensor G5 카메라·AI 기능 7가지 실전 테스트 결과
6월 11, 2025
그래뉼러 신스 앰비언트 음악: 몰입감 있는 사운드 디자인 완전 가이드
6월 12, 2025
드디어 오픈소스 AI가 폐쇄형 모델과 정면 승부를 벌일 수 있게 됐습니다. 2024년 7월 23일, Meta가 공개한 Llama 3.1 405B는 4050억 개의 파라미터를 가진 역대 최대 규모의 공개 AI 모델입니다. 16,000대의 H100 GPU로 학습된 이 모델은 여러 벤치마크에서 GPT-4o를 능가하며, AI 업계의 판도를 근본적으로 뒤흔들고 있습니다.
Meta Llama 3.1 405B 벤치마크: 숫자가 말해주는 실력
오픈소스 모델이 정말로 GPT-4o, Claude 3.5 Sonnet과 경쟁할 수 있을까요? 벤치마크 결과는 명확하게 ‘그렇다’고 답합니다.
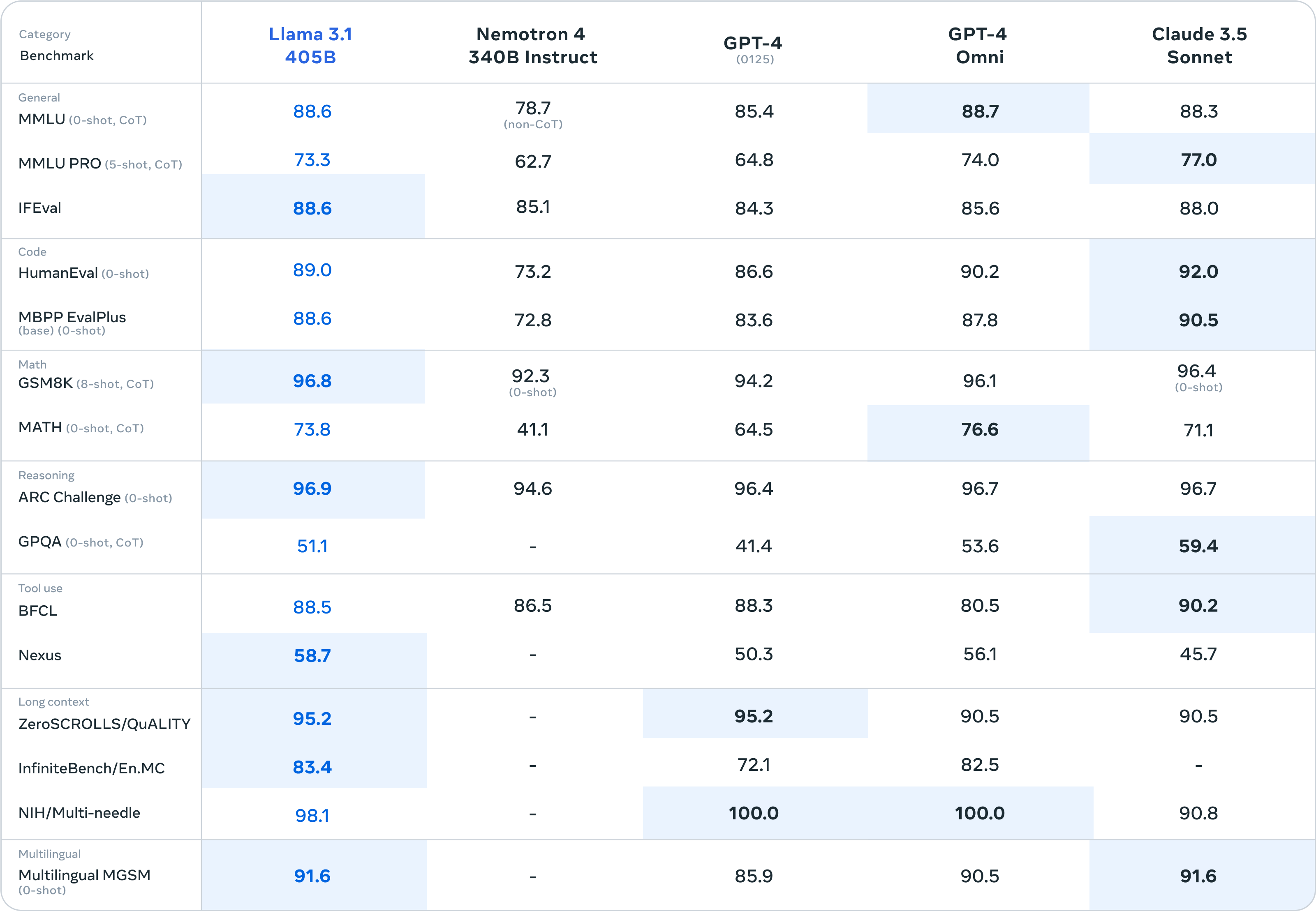
DROP 독해 벤치마크에서 Llama 3.1 405B는 84.8점을 기록하며 GPT-4o(83.4)와 Claude 3 Opus(83.1)를 모두 앞질렀습니다. 수학 추론(MATH 0-shot CoT)에서는 73.8%로 GPT-4o의 76.6%에는 살짝 못 미쳤지만, GPT-4 Turbo(72.6%)와 Claude 3.5 Sonnet(71.1%)을 넘어섰습니다. HumanEval 코딩 테스트에서는 89.0%, MMLU 학술 벤치마크에서는 87.3%를 달성했습니다.
이것은 특정 벤치마크만 골라낸 결과가 아닙니다. Meta는 150개 이상의 벤치마크 데이터셋에서 평가를 수행했으며, 결론은 분명합니다. Llama 3.1 405B는 최초로 프론티어 폐쇄형 시스템과 진정한 동등 수준에 도달한 공개 모델입니다.

4050억 파라미터: 아키텍처 심층 분석
기술적으로 가장 흥미로운 점은 Meta가 MoE(Mixture of Experts) 대신 Dense Transformer 아키텍처를 선택했다는 것입니다. Mixtral 같은 MoE 모델이 추론 시 파라미터의 일부만 활성화하는 반면, Meta는 매 추론마다 4050억 개의 파라미터 전부를 사용하는 표준 디코더 전용 트랜스포머를 채택했습니다. 이유는 전례 없는 규모에서의 학습 안정성 확보입니다.
학습 규모는 경이적입니다. 15조 개 이상의 토큰 데이터로 학습했으며, 이는 미국 의회 도서관의 모든 책을 약 15,000번 읽는 것에 해당합니다. 16,000대의 NVIDIA H100 GPU로 구성된 커스텀 클러스터에서 학습이 진행되었으며, AI 역사상 최대 규모의 학습 중 하나입니다. 컨텍스트 윈도우는 Llama 3의 8K에서 128K로 확장되어, GPT-4o 엔터프라이즈 버전과 동일한 수준입니다.
후속 학습(Post-training)에서는 SFT(Supervised Fine-Tuning)와 DPO(Direct Preference Optimization)를 반복 적용했으며, 합성 데이터 생성을 통해 지시 따르기 능력을 개선했습니다. 최종 모델은 BF16에서 FP8로 양자화하여 추론 컴퓨팅 비용을 줄이면서도 품질 저하를 최소화했습니다.
왜 Meta는 프론티어 AI를 무료로 공개했나
수억 달러를 투자해 만든 역대 최대 AI 모델을 왜 무료로 풀었을까요? OpenAI와 Google 경영진이 밤잠을 설치는 질문입니다.
마크 저커버그의 전략은 점점 명확해지고 있습니다. AI 레이어를 상품화(commoditize)하면, 경쟁 우위는 배포와 애플리케이션으로 이동합니다. Facebook, Instagram, WhatsApp을 통해 일일 활성 사용자 30억 명 이상을 보유한 Meta가 압도적으로 유리한 영역입니다. 최고의 AI 모델이 무료라면, 기업들이 OpenAI나 Google에 프리미엄 비용을 지불할 이유가 사라집니다.
라이선스 변경도 중요합니다. 이전 Llama 버전과 달리, 개발자들이 Llama 3.1의 출력을 다른 모델 학습에 활용할 수 있게 되었습니다. 이 단 하나의 변경이 대규모 합성 데이터 생성, 모델 증류, 파인튜닝 워크플로우를 가능하게 만들었습니다. 사실상 405B가 전체 오픈소스 AI 커뮤니티의 ‘교사 모델’이 된 것입니다.
엔터프라이즈 임팩트: 25개 파트너, 50% 비용 절감
기업들의 반응은 즉각적이고 압도적이었습니다. 출시 당일 AWS, NVIDIA, Databricks, Groq, Dell, Microsoft Azure, Google Cloud, Snowflake를 포함한 25개 이상의 파트너가 Llama 3.1 지원을 발표했습니다. 주요 클라우드 제공업체 기준, 월간 Llama 사용량은 2024년 1월부터 7월까지 10배 증가했으며, 고유 사용자 수가 가장 많은 모델은 바로 405B 변형이었습니다.
스타트업과 중견 기업에게 재정적 영향은 막대합니다. 데이터 프라이버시, 커스터마이징, 비용에 대한 완전한 통제권을 가지면서 프론티어급 AI 모델을 자체 인프라에서 운영하는 것이 이제 가능해졌습니다. 자체 인프라를 관리할 역량이 있는 조직은 API 기반 폐쇄형 대안 대비 약 50%의 비용 절감이 가능합니다.
Hugging Face에서 Llama 기반 파생 모델은 6만 개를 넘었습니다. 의료 진단부터 법률 문서 분석까지, 다양한 용도로 파인튜닝된 이 생태계는 어떤 폐쇄형 모델도 복제할 수 없는 것입니다.
8개 언어, 128K 컨텍스트: 다국어 지원의 의미
Llama 3.1은 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어 등 8개 언어를 기본 지원합니다. 공식 지원 목록에 한국어, 일본어, 중국어가 빠져 있지만, 오픈소스 특성상 커뮤니티가 추가 언어로 파인튜닝할 수 있으며 — 이미 많은 팀이 진행 중입니다.
128K 컨텍스트 윈도우는 엔터프라이즈 활용에 획기적입니다. 법무팀은 전체 계약서를 한 번에 분석할 수 있고, 개발팀은 전체 코드베이스를 리뷰에 넣을 수 있으며, 연구팀은 긴 논문을 전체 맥락을 유지하며 처리할 수 있습니다. 이로써 폐쇄형 모델이 가지고 있던 마지막 기술적 우위 중 하나가 사라졌습니다.
AI 업계에 미치는 영향: ‘AI의 리눅스 모먼트’
Llama 3.1 405B의 공개는 많은 이들이 ‘AI의 리눅스 모먼트’라고 부르는 것을 상징합니다. 리눅스가 서버 운영체제를 상품화하고 클라우드 컴퓨팅의 기반이 된 것처럼, Llama 3.1 405B는 AI의 파운데이션 모델 레이어를 상품화할 수 있습니다.
개발자에게는 전례 없는 선택지가 주어졌습니다. 경량 애플리케이션에는 8B, 대부분의 프로덕션에는 70B, 프론티어급 지능이 필요한 작업에는 405B를 사용할 수 있습니다. API 사용량 제한, 사용 요금, 데이터 프라이버시 우려 없이 말이죠. 기업에게는 AI의 ‘구축 vs 구매’ 계산법이 근본적으로 바뀌었음을 의미합니다.
OpenAI와 Google에 대한 경쟁 압력은 현실적입니다. 최고의 모델이 무료이고 공개되어 있다면, API 접근에 비용을 지불하는 가치 제안은 정당화하기 어려워집니다. 폐쇄형 모델이 사라지지는 않겠지만 — 사용 편의성, 생태계 통합, 특화 역량에서 경쟁하게 될 것입니다. 하지만 모든 이의 기준선이 높아졌습니다.
AI 기반 애플리케이션을 구축하든, 엔터프라이즈 LLM 도입을 검토하든, 업계 방향을 파악하려는 것이든, Llama 3.1 405B는 2024년 가장 중요한 AI 릴리스입니다. 오픈소스 AI가 프론티어에서 경쟁하는 시대는 오고 있는 것이 아니라 — 이미 여기에 와 있습니다.
오픈소스 AI 모델 도입이나 맞춤형 자동화 시스템 구축에 관심이 있으시다면, 무엇이 가능한지 함께 이야기해 보겠습니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}