
아마존 프라임 데이 2025: 노트북·모니터·가젯 최고의 테크 딜 15선 총정리
7월 30, 2025
Ableton Push 3 여름 업데이트: 팔로우 액션, 16 피치, 완전히 새로워진 오토 필터까지
7월 31, 2025
2025년 7월 10일, xAI가 AI 업계에 폭탄을 투하했습니다. Grok 4가 벤치마크를 단순히 넘은 게 아니라 박살냈습니다. AIME 2025(수학 올림피아드)에서 만점. GPQA Diamond(박사급 과학 추론)에서 88.9%. OpenAI와 Anthropic의 양강 체제가 하루아침에 3파전으로 바뀐 순간입니다.
하지만 벤치마크 점수만으로 모델을 판단하면 큰코다칩니다. 수 주간 세 모델을 실제 프로덕션 환경에서 — 코드 생성, 기술 문서 작성, 데이터 분석까지 — 직접 테스트한 결과, 숫자 뒤에 숨겨진 진짜 차이를 발견했습니다. 2025년 7월 기준, Grok 4 vs GPT-4o vs Claude 3.5 Sonnet 벤치마크 비교의 핵심을 정리합니다.
Grok 4 GPT-4o Claude 3.5 벤치마크 비교: 원시 성능 데이터
먼저 하드 데이터부터 살펴보겠습니다. 아래 수치는 Artificial Analysis와 독립 벤치마크 검증 결과를 기반으로 합니다.
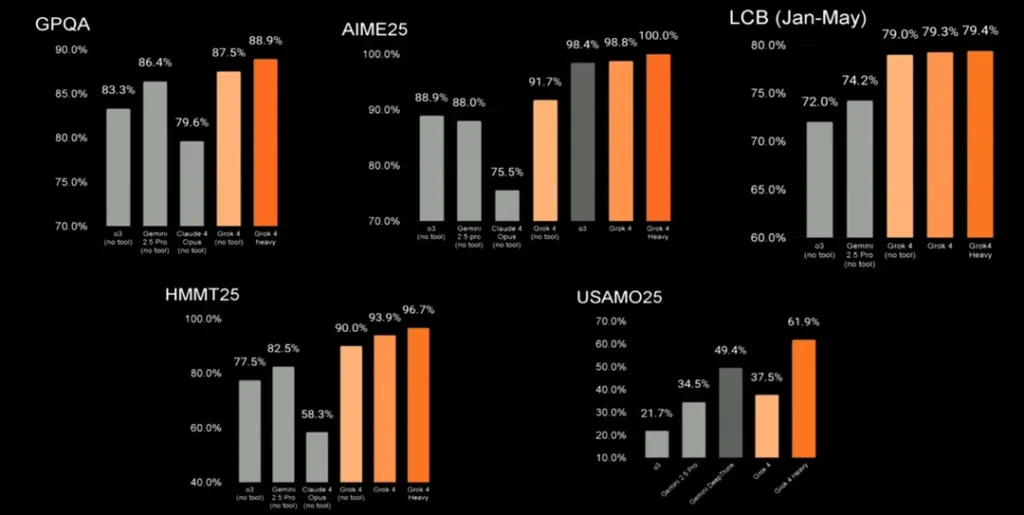
GPQA Diamond (박사급 과학 추론)
GPQA Diamond는 물리학, 화학, 생물학 전반의 대학원 수준 이해도를 측정하는 벤치마크입니다. 장난감 모델과 진짜 추론 엔진을 구분하는 관문이죠.
- Grok 4 Heavy: 88.9% — 역대 최고 기록
- Grok 4 (스탠다드): 87.5%
- GPT-4o: 85.0%
- Gemini 2.5 Pro: 83.3%
- Claude 3.5 Sonnet: 59.4% (0-shot CoT)
격차가 선명합니다. Grok 4 Heavy가 GPT-4o를 약 4포인트 앞서고, Claude 3.5 Sonnet은 상당한 차이를 보입니다. 단, Claude 3.5 Sonnet의 점수는 제로샷 체인 오브 소트(CoT) 프롬프팅 기준이라 Grok 4와 GPT-4o의 확장 추론 방식과 직접 비교에는 한계가 있습니다.
AIME 2025 (수학 올림피아드)
미국수학초청시험(AIME)은 상위 2.5% 수학 영재를 위한 시험입니다. Grok 4가 진정한 저력을 발휘한 영역이기도 합니다:
- Grok 4 Heavy: 100.0% — 만점
- Grok 4: 98.4%
- GPT-4o: 91.7%
- Gemini 2.5 Pro: 88.9%
AIME 2025에서 만점. GPT-4o의 91.7%도 대단한 성적이지만, xAI의 최신 모델은 모든 문제를 완벽하게 풀어냈습니다. 수학적 추론 능력의 진정한 도약입니다.
HMMT 2025 / USAMO 2025 (고급 수학)
하버드-MIT 수학 대회와 미국수학올림피아드는 추론의 한계를 더욱 밀어붙입니다:
- HMMT 2025: Grok 4 Heavy 96.7% vs GPT-4o 77.5% vs Gemini 82.5%
- USAMO 2025: Grok 4 Heavy 61.9% vs GPT-4o 21.7% vs Gemini 34.5%
USAMO에서 진짜 격차가 벌어집니다. Grok 4 Heavy가 GPT-4o 점수의 거의 3배에 달합니다. 이건 단순히 정답을 맞히는 것이 아니라 엄밀한 수학적 증명을 구성하는 능력의 차이입니다.
벤치마크 너머: 각 모델이 진짜 강한 영역
리더보드 숫자만으로는 실제 업무에 어떤 모델을 써야 할지 판단할 수 없습니다. 수 주간의 실전 테스트에서 발견한 사실을 공유합니다.
Grok 4: 추론의 괴물
Grok 4는 깊은 사고를 위해 태어난 모델입니다. 256K 컨텍스트 윈도우와 확장 추론 파이프라인(xAI가 “the big run”이라 부르는)을 갖추고, 챗봇보다는 연구자에 가깝게 문제에 접근합니다. SWE-Bench 72-75% 점수는 실제 소프트웨어 엔지니어링에서도 최고 수준입니다.
최적 용도: 복잡한 수학 증명, 과학 연구, 다단계 코딩 문제, 긴 논리 체인이 필요한 작업.
주의점: 속도. 첫 토큰 응답 시간이 14.15초(GPT-4o의 ~0.5초 대비)로, Grok 4는 말하기 전에 깊이 생각합니다. 출력 속도도 44.5 토큰/초로 적정 수준이지만 빠르진 않습니다. $3/$15(입/출력 백만 토큰당) 가격에 장시간 추론 세션은 비용이 급증할 수 있습니다.
GPT-4o: 밸런스의 왕
GPT-4o는 여전히 시장에서 가장 다재다능한 모델입니다. 추론 벤치마크 1위는 아니지만, 모든 카테고리에서 안정적으로 높은 성능을 보여줍니다. GPQA 85%와 AIME 91.7%는 결코 만만한 점수가 아니며 — 게다가 훨씬 빠른 속도로 해냅니다.
최적 용도: 범용 작업, 멀티모달(비전 + 텍스트), 빠른 반복 작업, 저지연이 필요한 프로덕션 API. MATH 벤치마크 76.6%, MMLU 85.7% 점수는 다양한 지식 영역을 안정적으로 처리함을 보여줍니다.
주의점: 입력 토큰당 $5로 세 모델 중 가장 비쌉니다. 그리고 최첨단 추론 작업에서는 Grok 4가 이제 확실한 우위를 점합니다.
Claude 3.5 Sonnet: 코딩과 글쓰기의 챔피언
Claude 3.5 Sonnet의 GPQA 59.4%가 걱정스러워 보일 수 있지만, 맥락이 중요합니다. Claude가 절대적으로 지배하는 영역은 실전 코딩과 장문 콘텐츠 생성입니다. Anthropic의 내부 에이전틱 코딩 평가에서 64%의 문제를 해결했으며, 이는 현직 개발자들의 실사용 경험과도 일치합니다.
최적 용도: 코드 생성 및 디버깅, 장문 분석(200K 컨텍스트 윈도우 — 세 모델 중 최대), 기술 문서 작성, 지시 준수 능력. 다국어 수학 91.6% 점수는 영어 외 수학 콘텐츠에서도 최고의 선택입니다.
주의점: 순수 과학 추론은 강점이 아닙니다. 박사급 물리학이나 복잡한 수학 증명이 필요하다면 Grok 4나 GPT-4o가 더 나은 선택입니다.
가격 현실 체크
아무리 좋은 모델도 API 예산을 파산시키면 의미가 없습니다:
- Grok 4: 백만 토큰당 입력 $3.00 / 출력 $15.00 (단, 다변 — 평가에서 약 8800만 토큰 생성)
- GPT-4o: 백만 토큰당 입력 $5.00 / 출력 $15.00
- Claude 3.5 Sonnet: 백만 토큰당 입력 $3.00 / 출력 $15.00
서류상으로는 Grok 4와 Claude 3.5 Sonnet이 입력 $3으로 동률이고, GPT-4o가 67% 더 비쌉니다. 하지만 Grok 4의 다변증은 숨겨진 비용입니다 — Artificial Analysis에 따르면 123개 모델 중 다변도 112위로, 쿼리당 출력 토큰이 현저히 많습니다. 실제 비용은 토큰당 가격이 시사하는 것보다 상당히 높을 수 있습니다.
예산에 민감한 개발자를 위해 xAI는 Grok 4 Fast도 제공합니다 — 백만 토큰당 $0.20/$0.50으로, 복잡한 추론 품질이 다소 떨어질 수 있지만 파격적인 가격입니다.
논란의 여지
Grok 4에 대한 솔직한 비교에서 벤치마크 논란을 빼놓을 수 없습니다. 일부 연구자들은 xAI의 자체 보고 수치가 독립 검증에서도 유지되는지 의문을 제기했습니다. ARC Prize Foundation이 ARC-AGI-2 점수 15.9%를 독립적으로 검증한 것은 신뢰도를 높여주지만, Artificial Analysis의 자체 Intelligence Index에서 Grok 4는 123개 모델 중 29위(점수 42)에 그칩니다 — 평균 이상이지만 xAI 마케팅이 암시하는 압도적 1위와는 거리가 있습니다.
핵심 교훈: 마케팅 주장보다 검증된 벤치마크를 신뢰하세요. Grok 4는 진정으로 인상적이지만, xAI 주장과 독립 분석 간의 괴리는 실제 성능이 그 사이 어딘가에 위치함을 시사합니다.
어떤 모델을 선택해야 할까? 실전 의사결정 프레임워크
세 모델 모두 충분히 테스트한 후의 솔직한 추천입니다:
- Grok 4 선택: 최대 추론 깊이가 필요할 때 — 수학 증명, 과학 분석, 복잡한 다단계 문제. 품질을 위해 기다리고, 다변증 비용을 감수할 수 있을 때.
- GPT-4o 선택: 빠른 응답의 믿을 수 있는 올라운더가 필요할 때. 프로덕션 API, 멀티모달 작업, 최고 추론보다 지연시간이 중요한 워크플로우.
- Claude 3.5 Sonnet 선택: 주 업무가 코딩, 장문 처리, 콘텐츠 생성일 때. 200K 컨텍스트 윈도우는 독보적이며, 실전 코딩 성능은 세 모델 중 최고라 해도 과언이 아닙니다.
현실은 이렇습니다 — 2025년 7월은 단일 ‘최고’ AI 모델이 사라진 시점입니다. 세 모델 모두 진정한 강점 영역을 확보했고, 가장 현명한 접근법은 특정 용도에 따라 세 모델을 전략적으로 활용하는 것입니다. 하나의 모델로 모든 걸 해결하는 시대는 공식적으로 끝났습니다.
AI 기반 자동화 파이프라인 구축이나 워크플로우에 적합한 모델 선택이 필요하시다면, 전략을 함께 논의해 보겠습니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.


{kind=link}
{kind=link}
{kind=link}