
Intel Lunar Lake NUC 미니 PC 리뷰: 가정과 사무실을 위한 컴팩트 데스크톱
8월 6, 2025
GarageBand AI 드러머, 2025년 8월 iOS 업데이트로 더 똑똑해졌습니다 — 공간 오디오까지 지원
8월 7, 2025
SWE-Bench 74.9%, Aider Polyglot 88%, 멀티파일 리팩토링 91%. 오늘 출시된 GPT-5의 코딩 벤치마크 숫자만 보면, OpenAI가 드디어 AI 코딩의 새 시대를 열어젖힌 것 같습니다. 그런데 독립 평가 기관 16x Engineer의 실전 테스트 결과는 충격적입니다 — GPT-5 SWE-Bench coding performance와 실제 개발 현장 성능 사이에 거대한 간극이 존재합니다. GPT-5는 7.46/10, Claude Opus 4는 8.92/10. 이 숫자의 의미를 파헤쳐보겠습니다.
GPT-5 SWE-Bench Coding Performance: 숫자로 보는 도약
2025년 8월 7일, OpenAI는 LIVE5TREAM 이벤트를 통해 GPT-5를 공식 출시했습니다. 400K 컨텍스트 윈도우(272K 입력 + 128K 출력)는 이전 세대 대비 획기적인 확장입니다. API 가격은 입력 토큰 $1.25/M, 출력 토큰 $10/M으로 책정되었습니다. 사실 오류율은 이전 모델 대비 80% 감소했고, 환각(hallucination) 비율은 오픈소스 프롬프트 기준 1% 미만입니다. 스펙시트만 놓고 보면 상당한 진보가 분명합니다.
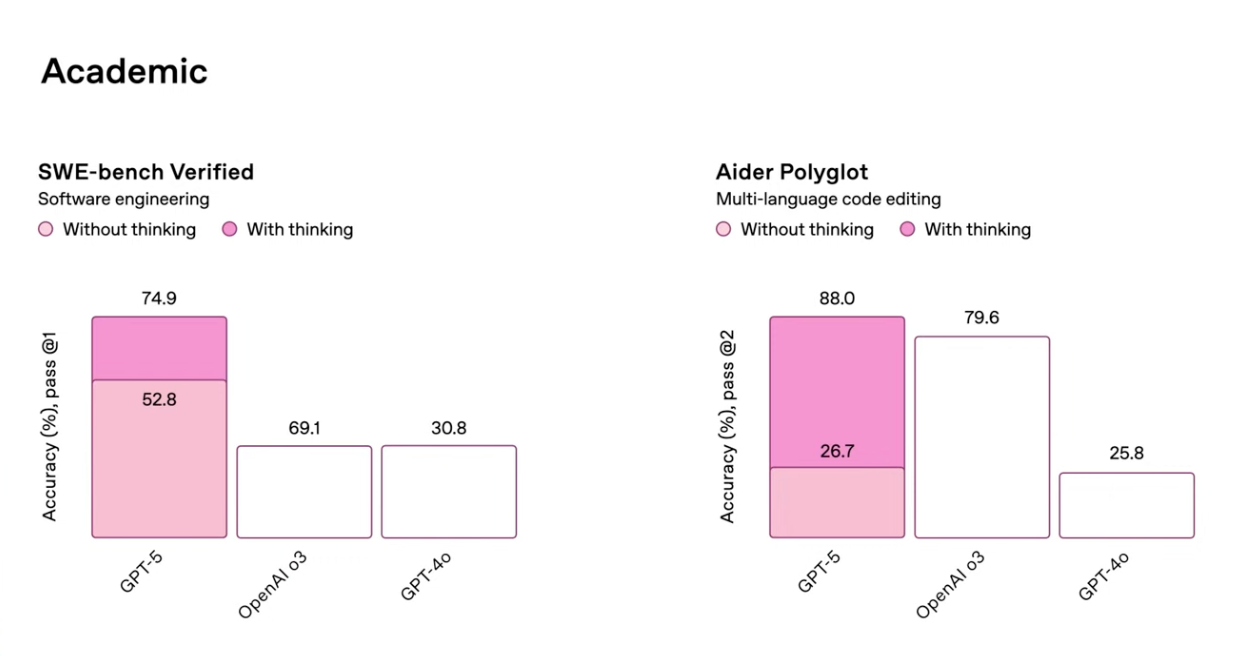
하지만 개발자들이 가장 주목한 건 역시 코딩 벤치마크였습니다. Cursor IDE의 분석에 따르면, GPT-5는 SWE-Bench Verified에서 74.9%를 기록하며 전작 GPT-4의 54.6%를 무려 20.3포인트 차이로 앞질렀습니다. o3의 69.1%도 가볍게 넘어섰습니다. 이 수치는 실제 소프트웨어 엔지니어링 작업 — GitHub 이슈 해결, 버그 수정, 기능 구현 — 에서의 성공률을 측정한 것이라 의미가 큽니다.
Aider Polyglot 벤치마크에서는 88%를 달성했고, Thinking 모드를 켜면 94%까지 올라갑니다. 이 벤치마크는 여러 프로그래밍 언어를 넘나들며 코드를 수정하는 능력을 측정하는데, 88%라는 숫자는 실무에서 쓸 만한 수준을 넘어 상당히 신뢰할 수 있는 영역에 진입했다는 뜻입니다.
언어별 정확도도 인상적입니다. Python 96%, JavaScript/TypeScript 94%, Go/Rust 92%. 멀티파일 리팩토링에서 91%(GPT-4는 67%), 테스트 생성에서 93%(GPT-4는 58%)를 기록했습니다. Vellum AI의 벤치마크 정리에 의하면 Thinking 모드 활성화 시 SWE-Bench에서 +22.1포인트, Aider Polyglot에서 +61.3포인트가 추가 상승합니다. 수학 벤치마크인 AIME 2025에서도 94.6%(도구 없이), Python 도구 사용 시 100%를 달성했습니다.
독립 실전 평가: 16x Engineer가 밝힌 불편한 진실
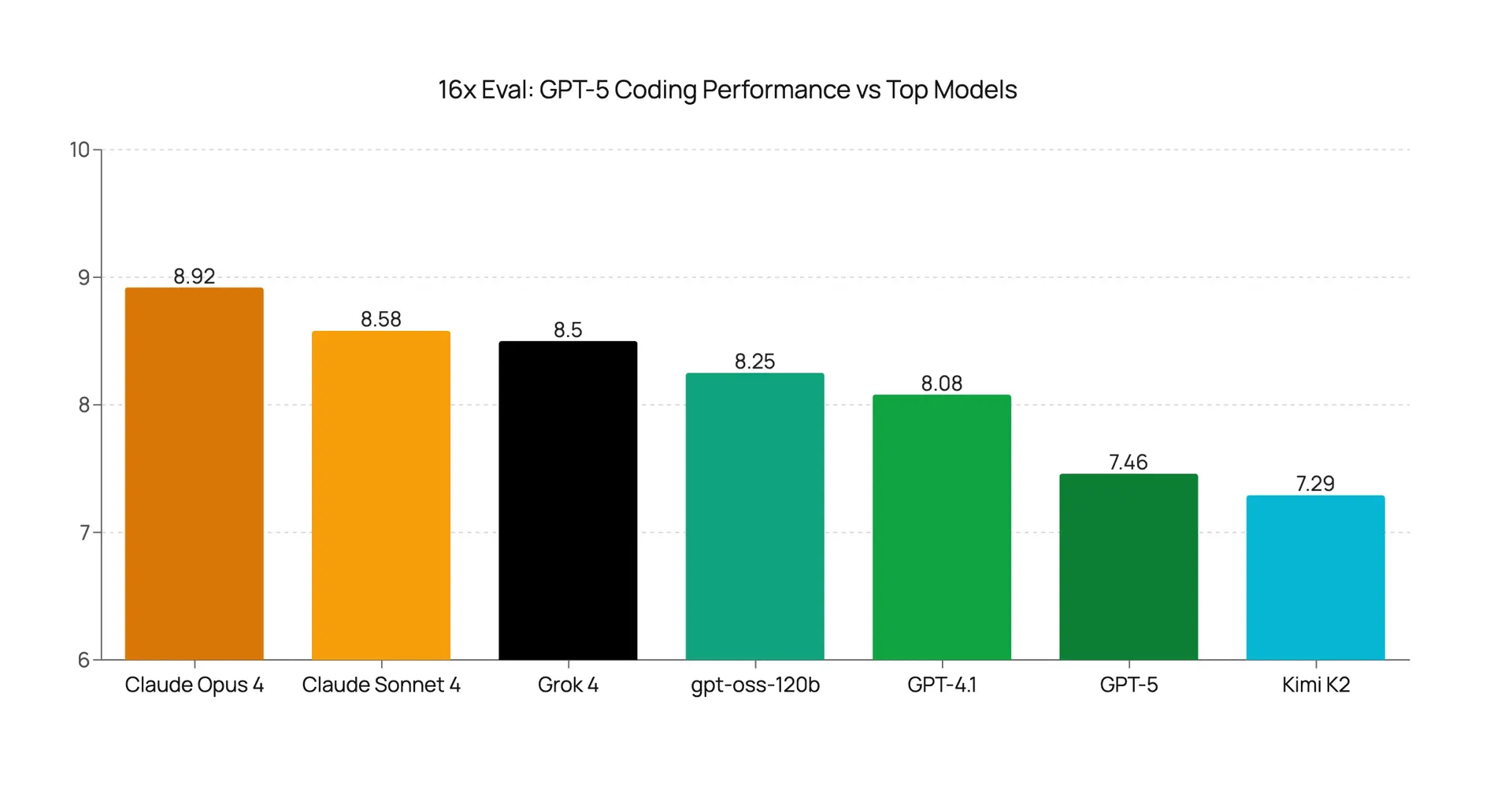
벤치마크 숫자가 화려할수록, 독립 평가의 가치는 더 커집니다. 16x Engineer는 GPT-5 출시 직후 실전 코딩 작업으로 종합 평가를 진행했는데, 결과는 기대와 크게 달랐습니다. 이 평가가 중요한 이유는 SWE-Bench 같은 표준화된 벤치마크가 아니라, 실제 개발 환경에서 마주하는 다양한 유형의 코딩 작업을 테스트했기 때문입니다.
GPT-5의 평균 코딩 점수는 10점 만점에 7.46점. Claude Opus 4가 8.92점, Claude Sonnet 4가 8.58점을 받은 것과 비교하면 상당한 격차입니다. 단순히 점수 차이만 보는 게 아니라, 이 격차가 의미하는 바를 생각해야 합니다. Claude Opus 4 대비 1.46점 차이는 코드 리뷰에서 추가 수정이 필요한 횟수, 디버깅에 소요되는 시간, 최종 코드 품질에 직접적으로 영향을 미칩니다.
가장 충격적인 결과는 TypeScript 타입 내로잉(narrowing) 작업이었습니다. GPT-5가 1/10을 받은 반면, 이전 모델인 GPT-4.1은 6/10을 기록했습니다. 신형 모델이 구형보다 특정 작업에서 5배나 뒤처진 겁니다. TypeScript의 타입 시스템을 정확하게 이해하고 활용하는 능력은 현대 웹 개발에서 핵심적인데, 이 영역에서의 퇴보는 무시할 수 없는 문제입니다.
물론 GPT-5가 강점을 보인 영역도 있었습니다. Next.js 관련 작업에서 9.5/10, 벤치마크 시각화에서 8.5/10을 기록했습니다. 하지만 전체적으로 보면 16x Engineer의 결론은 명확했습니다 — “혁신적(revolutionary)이 아니라 점진적(incremental)”이라는 것. OpenAI의 마케팅이 전달하는 메시지와 개발자가 실제로 경험하는 성능 사이에 분명한 괴리가 있습니다.
PR 리뷰부터 풀스택 앱까지: 작업별 성능 해부
Qodo의 PR Benchmark 테스트는 100개 이상의 리포지토리에서 가져온 400개 실제 풀 리퀘스트로 GPT-5를 평가했습니다. 이 테스트가 특히 가치 있는 이유는 합성 데이터가 아닌 실제 오픈소스 프로젝트의 PR을 사용했기 때문입니다. 결과적으로 GPT-5 medium-budget이 72.2점으로 최고 성능을 기록했습니다.
GPT-5의 코드 리뷰 강점은 구체적이었습니다. 기존 모델들이 놓치던 범위의 버그를 탐지하는 능력, 문제를 찾은 후 제시하는 코드 패치의 정밀도, 프로젝트별 코딩 규칙 준수 능력이 눈에 띄었습니다. 반면 약점도 분명했습니다. 거짓 양성(false positive) 비율이 높아서 “문제가 아닌 것을 문제로 지적하는” 경향이 있었고, 버그 심각도 레이블링이 일관적이지 못했습니다. 자동화된 코드 리뷰 파이프라인에서 이런 불일치는 개발팀의 신뢰를 떨어뜨리는 요인이 됩니다.
한편 Latent Space의 핸즈온 리뷰는 GPT-5를 “지금까지 AGI에 가장 가까운 모델”이라고 평가했습니다. 특히 Vercel AI SDK v5와 Zod 4 의존성 충돌을 o3와 Claude Opus가 해결하지 못한 상황에서 GPT-5만이 정확히 풀어냈다는 사례가 주목받았습니다. 이런 복잡한 의존성 해결은 실제 프로덕션 환경에서 자주 마주하는 문제이기 때문에 상당히 의미 있는 결과입니다.
단일 프롬프트로 프로덕션급 풀스택 앱을 생성하는 능력도 인상적이었습니다. 병렬 도구 호출을 통한 에이전트 성능은 GPT-5를 단순한 코드 생성기가 아닌 개발 파트너로 포지셔닝할 수 있는 잠재력을 보여줍니다. o3 대비 45% 적은 도구 호출로 더 나은 결과를 달성한다는 Final Round AI의 분석도 에이전트 효율성 측면에서 주목할 만합니다.
하지만 같은 Latent Space 리뷰에서 글쓰기 품질은 GPT-4.5보다 떨어진다는 지적도 나왔습니다. “LinkedIn 스팸” 스타일의 콘텐츠를 생성하는 경향이 있다는 것입니다. 코딩 최적화와 자연어 품질 최적화가 서로 다른 방향으로 이루어졌다는 점을 시사합니다.
Cursor에서의 현실: 개발자들의 날것의 반응
유명 개발자 Theo는 GPT-5 출시 직후 “놀라운 성능”이라고 칭찬했다가, 실제로 Cursor IDE에서 써본 뒤 “Cursor에서는 기대만큼 좋지 않다”고 입장을 번복했습니다. 이 에피소드는 벤치마크와 실전 사이의 괴리를 상징적으로 보여줍니다. 벤치마크는 통제된 환경에서의 성능을 측정하지만, 개발자의 실제 워크플로우는 불완전한 프롬프트, 맥락 부족, 레거시 코드와의 상호작용 등 훨씬 복잡한 조건에서 이루어집니다.
Leon Furze는 출시 다음 날(8월 8일) 리뷰에서 GPT-5가 “더 간결한 o3” 같다고 평가했습니다. 무료 버전과 Pro(Thinking 모드) 버전의 코딩 성능 차이가 상당하다는 점은 가격 대비 성능을 고려해야 하는 개발팀에게 중요한 정보입니다. CSV 내보내기 같은 기본적인 실용 기능이 여전히 실패한다는 점도 지적했습니다. 결론은 명확했습니다 — 마케팅 하이프에 휩쓸리지 말고, 직접 써보고 판단하라는 것이었습니다.
종합하면, T2-bench 텔레콤 분야에서 96.7%로 다른 모델들의 49% 미만과 압도적 격차를 보인 것처럼 특정 도메인에서는 GPT-5가 독보적입니다. 하지만 범용 코딩 어시스턴트로서의 포지션은 아직 Claude 제품군에 미치지 못한다는 것이 데이터가 말하는 현실입니다. GPQA Diamond(PhD 수준 과학)에서 85.7%, Humanity’s Last Exam에서 42%를 달성한 것을 보면 코딩 외 영역에서의 지능 자체는 확실히 향상되었지만, 그것이 곧 코딩 실전 성능으로 직결되지는 않습니다.
벤치마크와 현실 사이: 개발자가 알아야 할 것
이번 GPT-5 출시가 보여주는 가장 중요한 교훈은, 벤치마크 점수와 실전 개발 경험이 반드시 일치하지는 않는다는 것입니다. SWE-Bench 74.9%는 분명 인상적이고, GPT-4 대비 20포인트 이상의 도약은 실질적인 발전입니다. 하지만 16x Engineer의 7.46/10은 “아직 Claude Opus 4를 대체할 수준은 아니다”라는 메시지를 명확히 전달합니다.
실전에서 GPT-5를 활용하려는 개발자에게 몇 가지 제안을 드립니다. 첫째, Next.js나 풀스택 앱 생성처럼 GPT-5가 강점을 보이는 영역에서 활용하세요. 둘째, TypeScript 타입 시스템 같은 정밀한 작업에서는 여전히 Claude Opus 4나 Sonnet 4가 더 신뢰할 수 있습니다. 셋째, Thinking 모드(Pro)와 일반 모드의 성능 차이가 크므로, 복잡한 코딩 작업에서는 반드시 Thinking 모드를 사용하세요. 넷째, 에이전트 모드(병렬 도구 호출)에서 GPT-5의 진가가 발휘되므로, 단독 코드 생성보다는 에이전트 파이프라인에 통합하는 방식을 고려해보세요.
AI 코딩 도구의 경쟁은 이제 벤치마크 점수 경쟁을 넘어 “실전에서 얼마나 안정적으로 작동하는가”의 영역으로 넘어가고 있습니다. GPT-5는 확실한 발전이지만, 혁명이라고 부르기에는 아직 이릅니다. 가장 현명한 접근법은 작업 특성에 따라 GPT-5, Claude Opus 4, Claude Sonnet 4를 적절히 조합하는 멀티모델 전략일 것입니다.
AI 코딩 도구 도입이나 개발 워크플로우 자동화 구축이 필요하시다면, 기술 컨설팅을 통해 최적의 솔루션을 찾아드립니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}