
블랙프라이데이 2025: 게이밍 PC 부품 최고 할인 총정리 — GPU, CPU, SSD 지금 사야 할 것들
11월 6, 2025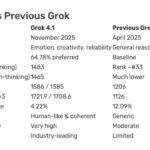
xAI Grok 4.1 — 환각률 65% 감소, LM Arena 1위 달성한 진짜 실력
11월 10, 2025
11월이 되자 AI 업계가 폭발했습니다. 9월 말 Anthropic의 Claude Sonnet 4.5가 코딩 벤치마크를 갈아치우더니, 11월 12일 OpenAI가 GPT-5.1로 응수했고, 불과 6일 뒤 Google이 Gemini 3 Pro로 역대 최고 Elo 1501점을 찍었습니다. Gemini 3 vs GPT-5.1 vs Claude Sonnet 4.5 비교 — 이 세 모델이 단 50일 안에 쏟아진 건 전례 없는 일입니다.
이 글에서는 벤치마크, 가격, 실제 코딩 성능, 그리고 실무 활용 관점에서 세 모델을 낱낱이 비교합니다. 어떤 모델이 당신에게 맞는지, 숫자와 경험으로 결론을 내려 보겠습니다.

Gemini 3 vs GPT-5.1 vs Claude Sonnet 4.5: 벤치마크 대격돌
먼저 핵심 벤치마크 수치부터 비교합니다. 이 세 모델은 거의 모든 주요 평가에서 1~2% 이내로 붙어있어, “압도적 1위”를 가리기가 어렵습니다.
코딩 벤치마크: SWE-bench Verified
실제 GitHub 이슈를 자동으로 해결하는 SWE-bench Verified에서 Claude Sonnet 4.5가 77.2%로 최고점을 기록했습니다. GPT-5.1이 76.3%, Gemini 3 Pro가 76.2%로 뒤를 이었습니다. 차이는 1%p에 불과하지만, 실무에서 이 1%는 500건의 이슈 중 5건의 추가 자동 해결을 의미합니다.
특히 Claude Sonnet 4.5의 경우, 코드 에디터 Replit에서 오류율이 9%에서 0%로 떨어졌다는 실제 사례가 인상적입니다. 386개의 GitHub 이슈를 자율적으로 해결했다는 서드파티 검증 결과도 있습니다.
학술/추론: GPQA Diamond & MMMLU
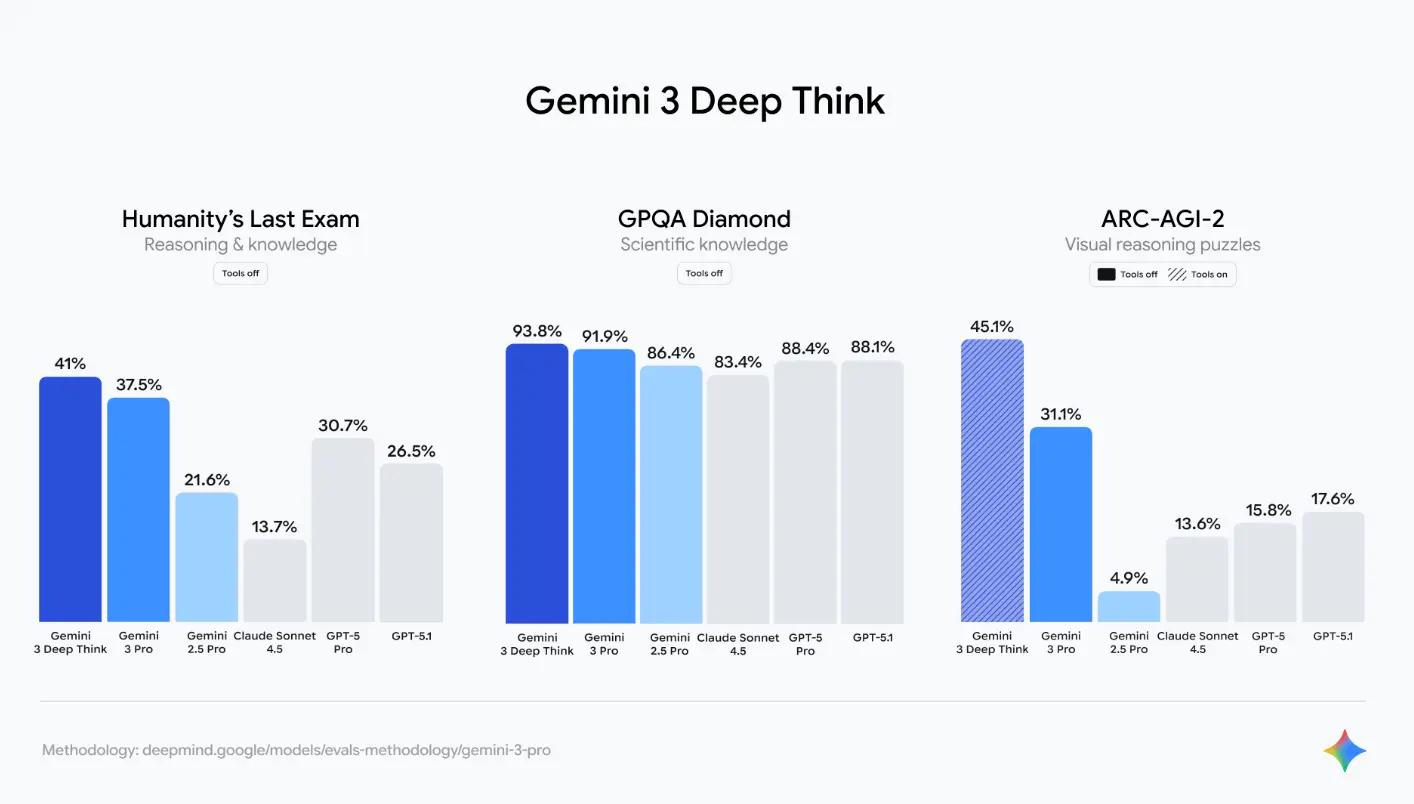
대학원 수준 과학 질의응답 벤치마크인 GPQA Diamond에서는 Gemini 3 Pro가 91.9%로 압도적 1위, Deep Think 모드를 쓰면 93.8%까지 올라갑니다. GPT-5가 85.7%, Claude Sonnet 4.5는 83.4%로, 이 영역에서는 Google이 확실한 우위를 보입니다.
다국어 종합 평가 MMMLU에서도 Gemini 3 Pro(91.8%)가 GPT-5와 Claude Sonnet 4.5(각각 89.1%)를 앞섭니다. Google의 학술 분야 강세가 돋보이는 결과입니다.
수학: AIME 2025
미국 수학경시대회(AIME) 2025 문제에서 Gemini 3 Pro는 도구 사용 시 100%, 단독으로 95%를 달성했습니다. Claude Sonnet 4.5도 Python과 결합하면 100%를 기록합니다. 수학 추론 능력에서는 두 모델 모두 최정상급입니다.
가격 비교: 성능 대비 가성비의 승자는?
벤치마크 점수가 비슷하다면, 결국 가격이 선택을 좌우합니다. 세 모델의 API 가격을 직접 비교해 보겠습니다.
- Gemini 3 Pro: 입력 $1.25/M토큰, 출력 $5/M토큰, 컨텍스트 1M 토큰
- GPT-5.1: 입력 $2.50/M토큰, 출력 $10/M토큰, 컨텍스트 128K 토큰
- Claude Sonnet 4.5: 입력 $3/M토큰, 출력 $15/M토큰, 컨텍스트 200K 토큰
가격 차이가 극명합니다. Gemini 3 Pro는 Claude Sonnet 4.5 대비 출력 비용이 3분의 1에 불과하며, 컨텍스트 윈도우는 5배입니다. 대량 API 호출이 필요한 프로덕션 환경에서 이 가격 차이는 월 수백~수천 달러의 비용 절감을 의미합니다.
다만 단순 가격 비교만으로는 충분하지 않습니다. Claude Sonnet 4.5는 코딩 특화 작업에서 더 적은 반복으로 정확한 결과를 내놓는 경우가 많아, 총 토큰 사용량이 오히려 줄어들 수 있습니다. GPT-5.1은 Instant 모드와 Thinking 모드를 나눠 비용을 최적화할 수 있는 유연성이 장점입니다.
실무 활용: 어떤 모델을 어디에 쓸 것인가
벤치마크와 가격을 넘어, 실제로 각 모델이 빛나는 영역을 정리합니다.
코딩/소프트웨어 개발: Claude Sonnet 4.5 우세
SWE-bench 77.2% 최고점, OSWorld 61.4%(이전 모델 대비 +45%), Replit 오류율 0% — 코딩 작업이라면 Claude Sonnet 4.5가 현재 가장 신뢰할 수 있는 선택입니다. 특히 복잡한 코드베이스 디버깅, 대규모 리팩토링, 자동화 스크립트 생성에서 두각을 나타냅니다.
학술/연구/추론: Gemini 3 Pro 압도
GPQA Diamond 91.9%, Deep Think 모드로 HLE(Humanity’s Last Exam) 40% 돌파 — 기존 모델들이 20% 수준에 머물던 난제 시험에서 두 배의 성과를 보여줬습니다. 과학 논문 분석, 복잡한 수학 증명, 연구 보조 작업에는 Gemini 3가 최적입니다. 게다가 100만 토큰 컨텍스트는 긴 논문이나 코드베이스 전체를 한 번에 처리할 수 있게 해줍니다.
일반 사용/대화/쇼핑: GPT-5.1이 가장 자연스러움
GPT-5.1은 Instant 모드로 빠른 응답, Thinking 모드로 깊은 분석을 사용자가 선택할 수 있습니다. 쇼핑 리서치 기능, 멀티모달 입력, 맞춤형 성격 설정까지 — 일상적인 AI 어시스턴트로서의 완성도가 가장 높습니다. 블랙프라이데이 시즌에 쇼핑 비교를 도와줄 AI를 찾는다면 GPT-5.1이 제격입니다.
에이전틱(Agentic) 작업: Gemini 3의 새 영역
Vending-Bench에서 GPT-5.1 대비 272% 높은 점수를 기록한 Gemini 3 Pro는 자율 에이전트 작업에서 독보적입니다. 새롭게 출시된 Antigravity 코딩 IDE와 결합하면, 단순 코드 생성을 넘어 프로젝트 전체를 관리하는 AI 에이전트 구축이 가능해집니다.
11월 AI 전쟁의 진짜 의미
2025년 11월의 AI 모델 3파전이 보여주는 가장 중요한 트렌드는 “범용 1위”의 시대가 끝났다는 것입니다. 코딩은 Claude, 추론은 Gemini, 사용자 경험은 GPT — 각 모델이 자신만의 영역에서 최강자가 되었습니다.
실무적으로 이것은 “하나만 쓰면 된다”는 생각을 버려야 한다는 뜻입니다. 개발팀이라면 코딩에 Claude Sonnet 4.5, 리서치에 Gemini 3 Pro, 고객 대면 챗봇에 GPT-5.1을 조합하는 멀티모델 전략이 2025년 말의 정답입니다.
가격 경쟁도 주목할 포인트입니다. Gemini 3 Pro가 출력 토큰당 $5로 가격을 내리면서, OpenAI와 Anthropic도 조만간 가격 인하 압박을 받을 가능성이 높습니다. 블랙프라이데이 시즌답게, AI 모델 시장에도 가격 전쟁이 시작될 조짐입니다.
결론적으로, 세 모델 모두 각자의 강점이 분명합니다. 가장 현명한 전략은 용도에 따라 모델을 선택하는 것입니다. 코딩 자동화가 핵심이라면 Claude Sonnet 4.5, 대규모 데이터 분석과 추론이 필요하다면 Gemini 3 Pro, 자연스러운 대화형 AI 경험이 중요하다면 GPT-5.1이 최적의 선택입니다.
AI 모델 선택부터 자동화 파이프라인 구축까지, 기술 컨설팅이 필요하시다면 Sean에게 문의하세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}