Databricks DBRX: 36B 활성 파라미터로 70B 모델을 압도한 132B MoE의 진짜 실력
5월 28, 2025
초보자 믹싱 실수 5가지: 흔한 EQ와 컴프레서 오류 총정리
5월 28, 2025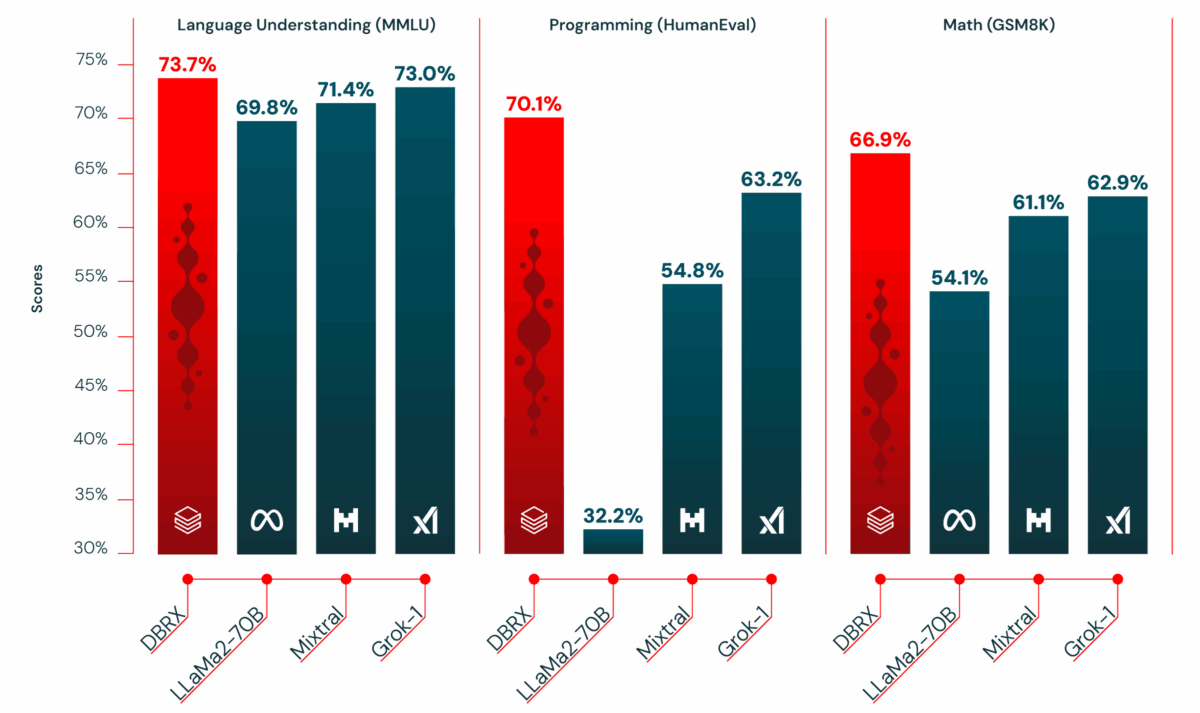
132B 파라미터 모델이 36B만 켜고도 70B 모델을 이긴다면 믿으시겠습니까? Databricks DBRX가 정확히 그 일을 해냈습니다. 2024년 3월 출시 이후 1년이 지난 지금, 이 모델이 엔터프라이즈 AI 시장에 남긴 흔적은 단순한 벤치마크 숫자를 넘어섭니다.
Databricks DBRX의 핵심: 세분화된 MoE 아키텍처란 무엇인가
Databricks DBRX의 가장 핵심적인 기술은 세분화된 혼합 전문가(fine-grained Mixture of Experts, MoE) 아키텍처입니다. 총 132B(1,320억) 개의 파라미터를 보유하지만, 추론 시에는 16개의 전문가 중 4개만 활성화하여 실질적으로 36B(360억) 파라미터만 사용합니다. 이 설계가 왜 혁신적인지 구체적인 수치로 살펴보겠습니다.
전통적인 밀집(dense) 모델은 모든 파라미터가 매번 활성화됩니다. Llama 2 70B는 추론할 때마다 700억 개의 파라미터를 전부 사용합니다. 반면 Databricks DBRX는 입력 토큰에 따라 가장 적합한 전문가 4개만 선택적으로 활성화합니다. 결과적으로 동일한 품질의 응답을 생성하면서 연산량은 절반 이하로 줄어듭니다.
Databricks의 공식 발표에 따르면, DBRX는 16개 전문가에서 4개를 선택하는 방식을 채택했습니다. 이는 Mixtral의 8개 중 2개 선택 방식과 비교하면 전문가 조합 수가 65배 더 많습니다. 더 세밀한 전문가 선택이 가능하기 때문에, 각 토큰에 대해 최적의 지식 경로를 찾아갈 수 있습니다.
” alt=”Databricks DBRX 벤치마크 비교 차트”/>
벤치마크로 증명된 Databricks DBRX의 성능
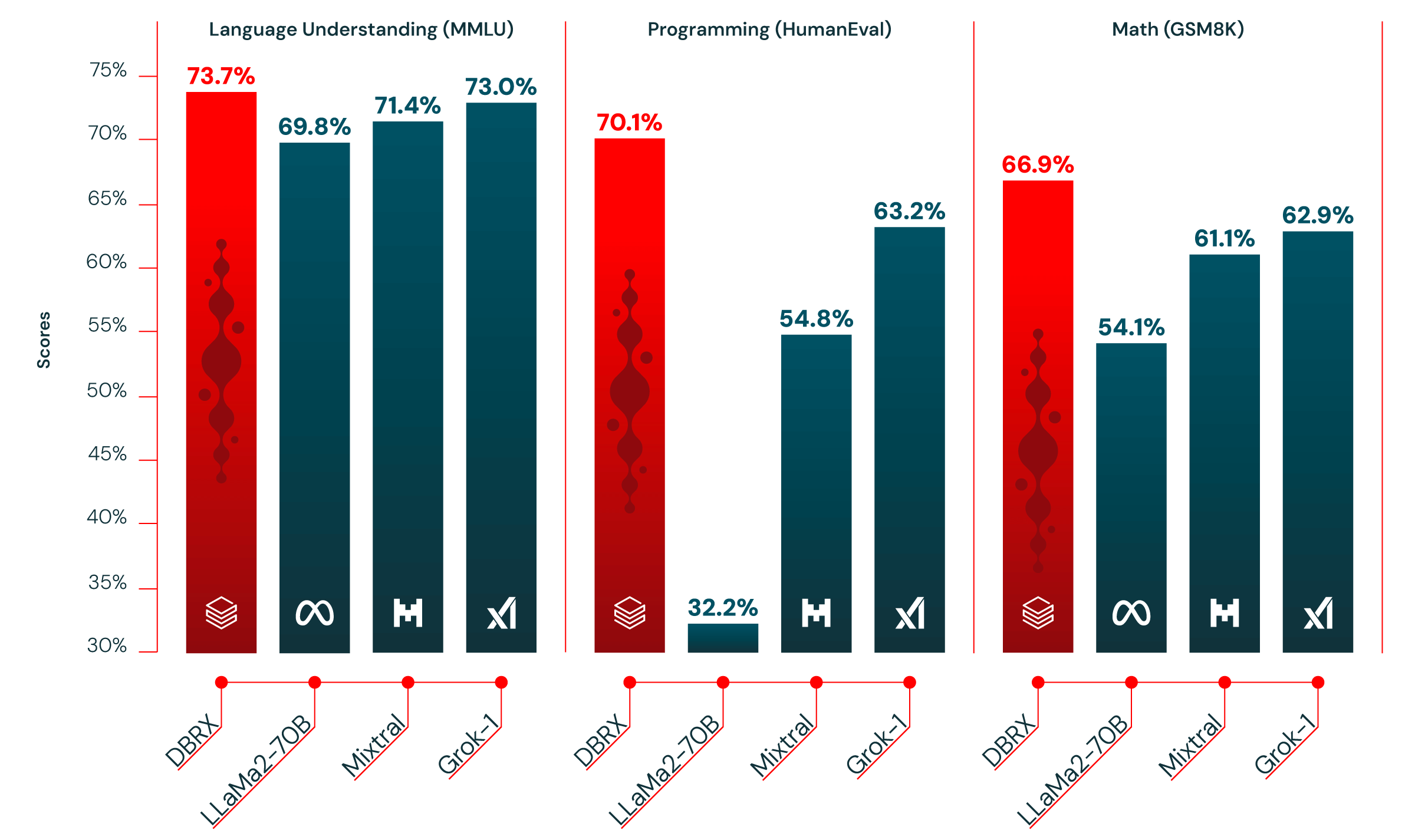
숫자는 거짓말을 하지 않습니다. Databricks DBRX는 주요 벤치마크에서 자신보다 파라미터 수가 2배 가까운 모델들을 일관되게 능가했습니다. MMLU(다분야 언어 이해) 테스트에서 73.7%를 기록하며 GPT-3.5의 70.0%를 넘어섰고, HumanEval(코드 생성) 테스트에서는 70.1%로 GPT-3.5의 48.1%를 크게 앞질렀습니다.
특히 주목할 점은 HellaSwag(상식 추론) 벤치마크입니다. Databricks DBRX는 89.0%를 기록하며, GPT-3.5의 85.5%는 물론 GPT-4의 84.7%까지 능가하는 결과를 보여줬습니다. 오픈소스 모델이 GPT-4를 특정 벤치마크에서 이긴다는 것은 1년 전만 해도 상상하기 어려운 일이었습니다.
수학 추론 능력을 측정하는 GSM8k에서는 66.9%를 달성했습니다. 이 수치들을 종합하면, Databricks DBRX는 36B 활성 파라미터만으로 70B 이상의 밀집 모델과 대등하거나 우월한 성능을 보여주고 있습니다. 이것이 MoE 아키텍처의 효율성을 실질적으로 입증한 것입니다.
추론 속도: Llama 2 70B 대비 2배 빠른 처리량
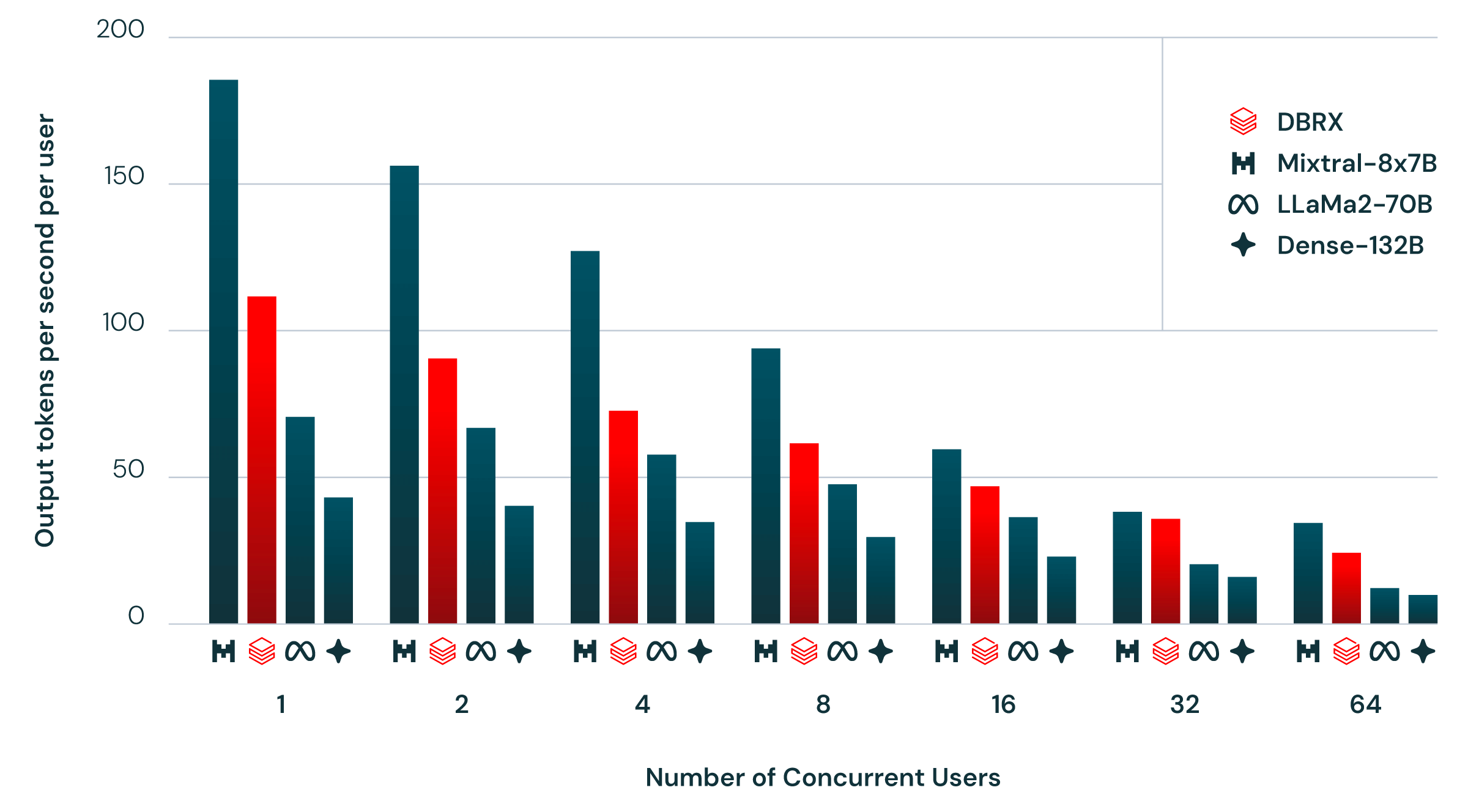
엔터프라이즈 환경에서 모델 성능만큼 중요한 것이 속도와 비용입니다. Databricks DBRX는 최대 150 tok/s의 추론 처리량을 달성하며, 이는 Llama 2 70B 대비 약 2배 빠른 수치입니다. 활성 파라미터가 절반 수준이기 때문에 당연한 결과이지만, 이 속도 차이가 실제 서비스에서 의미하는 바는 큽니다.
NVIDIA의 기술 블로그에 따르면, DBRX는 TensorRT-LLM으로 최적화했을 때 지연 시간과 처리량 모두에서 탁월한 성능을 보여줍니다. NVIDIA NIM 마이크로서비스를 통한 배포도 지원되어, 개발자 접근성이 10~100배 향상된다고 밝혔습니다. 코딩 작업, 텍스트 완성, 소수 턴 상호작용, RAG(검색 증강 생성) 등에서 특히 뛰어난 성능을 발휘합니다.
훈련 효율성도 인상적입니다. MoE 모델은 동일 성능 기준으로 밀집 모델보다 훈련 효율이 약 2배 높고, Databricks의 이전 모델인 MPT 대비로는 4배 더 효율적입니다. 12T(12조) 토큰의 텍스트와 코드 데이터로 사전 학습되었는데, 이는 Llama 2의 2T 토큰과 비교하면 6배에 달하는 데이터량입니다.
오픈소스 전략: 엔터프라이즈 AI 생태계를 바꾸다
Databricks DBRX가 출시 1년이 지난 지금까지 업계에서 회자되는 가장 큰 이유는 오픈소스 전략입니다. DBRX Base와 DBRX Instruct 두 가지 변형이 모두 GitHub과 Hugging Face에 공개되었습니다. Databricks Open Model License 하에 배포되어, 기업들이 자사 데이터로 파인튜닝하여 맞춤형 LLM을 구축할 수 있습니다.
” alt=”Databricks DBRX API 인터페이스 화면”/>
이 전략이 중요한 이유는 명확합니다. GPT-4나 Claude 같은 폐쇄형 모델은 뛰어난 성능을 제공하지만, 기업의 민감한 데이터를 외부 API로 보내야 한다는 근본적인 한계가 있습니다. DBRX는 기업이 자체 인프라에서 운영할 수 있는 고성능 오픈소스 대안을 제시했습니다.
Databricks Foundation Model API를 통해 토큰당 과금(pay-per-token)과 전용 처리량(provisioned throughput) 두 가지 방식으로 사용할 수 있습니다. 자체 배포가 부담스러운 기업은 API로 시작하고, 규모가 커지면 자체 인프라로 전환하는 단계적 접근이 가능합니다.
실전 배포 시 고려할 점: 320GB의 벽
Databricks DBRX를 로컬에 배포하려면 최소 320GB의 메모리가 필요합니다. 이는 결코 가벼운 요구사항이 아닙니다. NVIDIA A100 80GB GPU 4장 이상이 필요하며, 인프라 비용이 상당합니다. MoE 아키텍처 특성상 활성 파라미터는 36B이지만, 전체 132B 파라미터를 메모리에 올려야 하기 때문입니다.
하지만 이 비용을 동일 성능의 밀집 모델과 비교하면 이야기가 달라집니다. 70B 밀집 모델과 비슷한 메모리를 차지하면서 더 나은 성능을 제공하고, 추론 속도까지 2배 빠릅니다. 장기적인 운영 비용을 계산하면 DBRX의 TCO(총소유비용)가 더 유리해질 수 있습니다.
Mosaic AI 팀이 NVIDIA DGX Cloud에서 개발한 만큼, 클라우드 배포 경로가 잘 정비되어 있습니다. 32K 토큰 컨텍스트 윈도우와 GPT-4 토크나이저(tiktoken)를 사용하며, RoPE(회전 위치 인코딩), GLU(게이트 선형 유닛), GQA(그룹화 쿼리 어텐션) 등 최신 아키텍처 혁신을 모두 반영하고 있습니다.
1년 후 평가: DBRX가 증명한 것과 남긴 과제
2025년 5월 현재, Databricks DBRX 출시 이후 약 1년이 흘렀습니다. 이 모델이 증명한 가장 중요한 사실은 MoE 아키텍처가 엔터프라이즈 환경에서 실용적이라는 것입니다. 단순히 연구 논문 속 개념이 아니라, 실제 프로덕션에서 사용 가능한 효율적 모델 설계라는 점을 입증했습니다.
Databricks는 DBRX를 통해 컴퓨팅 자원 효율성이 LLM 경쟁의 핵심 축이 될 것임을 선제적으로 보여줬습니다. 파라미터 수만 늘리는 무한 확장 경쟁 대신, 같은 자원으로 더 나은 결과를 내는 방향으로 경쟁 구도가 이동하고 있습니다. DBRX의 세분화된 MoE 접근법은 이 트렌드의 선두에 있습니다.
물론 과제도 있습니다. 320GB 메모리 요구사항은 소규모 기업에게 여전히 높은 진입장벽이며, Llama 3나 Mistral Large 등 후속 오픈소스 모델들과의 경쟁도 치열해지고 있습니다. 하지만 DBRX가 열어놓은 MoE 기반 엔터프라이즈 AI의 가능성은 앞으로의 모델 개발 방향에 지속적인 영향을 미칠 것입니다.
엔터프라이즈 AI 도입을 고려하는 기업이라면, DBRX의 사례는 중요한 교훈을 줍니다. 가장 큰 모델이 항상 최선이 아니며, 아키텍처 효율성과 배포 유연성이 실제 비즈니스 가치를 결정한다는 것입니다. Databricks DBRX는 그 원칙을 132B 파라미터로 증명해 보였습니다.
엔터프라이즈 AI 모델 선택이나 MoE 기반 시스템 구축에 대해 더 알고 싶으시다면, 기술 컨설팅을 통해 최적의 솔루션을 찾아보세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}