
iPhone 17 Pro 리뷰: 카메라 바 디자인, A19 Pro 베이퍼 챔버 냉각, 8배 광학줌 — iPhone X 이후 가장 큰 변화
9월 1, 2025
AES 2025 프리뷰: 올해 전시장을 지배할 스튜디오 모니터, 마이크, 프로세싱 장비 7선
9월 2, 2025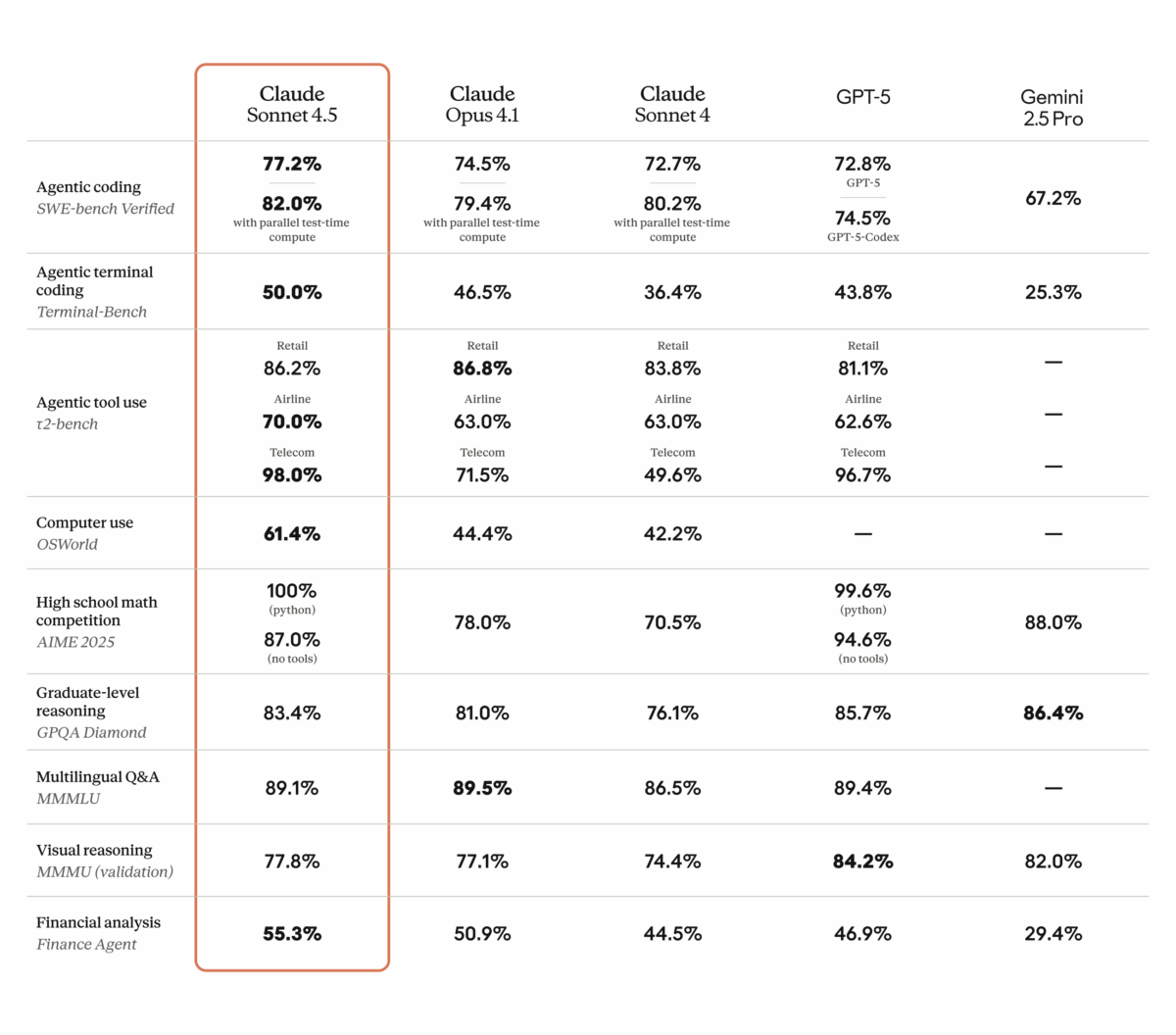
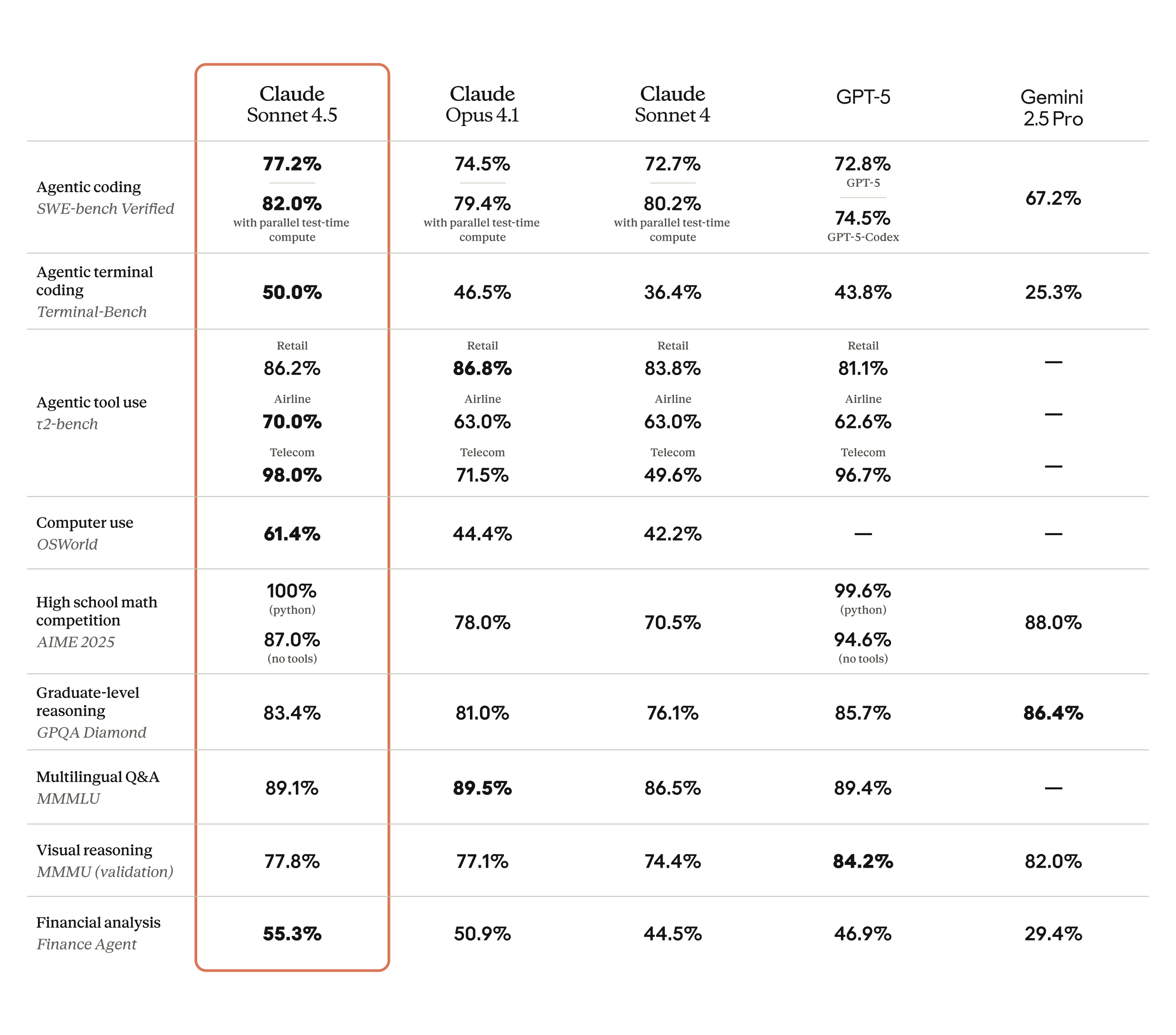
SWE-bench 77.2%. 이 숫자 하나가 2025년 AI 코딩 모델 시장의 판도를 완전히 뒤집었습니다. Anthropic이 내놓은 Claude Sonnet 4.5 벤치마크 결과는 단순한 업그레이드가 아니라, 미드티어 모델이 플래그십을 압도할 수 있다는 것을 증명한 사건입니다. GPT-5 Codex의 71.4%, Gemini 2.5 Pro의 69.8%를 한참 앞서는 이 점수가 어떻게 가능했을까요?
Claude Sonnet 4.5 벤치마크: 숫자가 말해주는 압도적 성능
Anthropic은 2025년 Claude Sonnet 4.5를 공개하면서 업계를 놀라게 했습니다. 가장 눈에 띄는 것은 SWE-bench Verified에서 기록한 77.2%의 정답률입니다. 병렬 처리를 활용하면 82%까지 올라갑니다. 이는 실제 GitHub 이슈를 자동으로 해결하는 테스트로, 인위적인 벤치마크가 아닌 현실 세계의 코딩 능력을 측정합니다.
이전 모델인 Claude Sonnet 4가 64.0%였던 것과 비교하면 13.2%포인트의 도약입니다. 단순 수치가 아닙니다. 이것은 실제 소프트웨어 버그를 찾고, 코드를 수정하고, PR을 만드는 능력이 한 세대 만에 극적으로 향상되었다는 의미입니다.
주요 벤치마크 결과를 정리하면 다음과 같습니다.
- SWE-bench Verified: 77.2% (병렬 82%) — GPT-5 Codex 71.4%, Gemini 2.5 Pro 69.8% 대비 압도적
- OSWorld (컴퓨터 사용): 61.4% — Claude Sonnet 4의 42.2%에서 19.2%p 상승
- GPQA Diamond (대학원 수준 과학): 83.4%
- AIME 2025 (수학): Python 활용 시 100%, 미활용 시 87%
- TAU-bench (에이전트 작업): 소매 86.2%, 항공 70.0%, 통신 98.0%
GPT-5 Codex, Gemini 2.5 Pro와의 Claude Sonnet 4.5 벤치마크 비교
코딩 벤치마크에서 Claude Sonnet 4.5가 경쟁 모델들을 어떻게 압도하는지 구체적으로 살펴보겠습니다. 최근 비교 분석에 따르면, SWE-bench Verified 기준 Claude Sonnet 4.5는 77.2%를 기록한 반면 OpenAI의 GPT-5 Codex는 71.4%, Google의 Gemini 2.5 Pro는 69.8%에 그쳤습니다.
이 차이가 의미하는 바는 명확합니다. Claude Sonnet 4.5는 실제 GitHub 리포지토리에서 발생하는 복잡한 버그를 GPT-5보다 약 8% 더 정확하게 해결합니다. 개발자 입장에서 이 8%는 하루에 수십 번 반복되는 디버깅 작업에서 체감되는 실질적인 생산성 차이입니다.
특히 주목할 점은 코드 편집 오류율입니다. Cirra의 기술 분석에 따르면, Claude Sonnet 4.5는 코드 편집 시 0%의 오류율을 기록했습니다. Next.js 작업에서는 Sonnet 4 대비 17%의 성능 향상을 보였고, 보안 취약점 분류 속도는 44% 빨라졌습니다. 코드를 정확하게 수정하면서도 빠른 속도를 유지한다는 것은 프로덕션 환경에서 결정적인 강점입니다.
30시간 자율 운영: AI 에이전트의 새로운 기준
Claude Sonnet 4.5의 진정한 차별점은 벤치마크 점수만이 아닙니다. 이 모델은 30시간 이상 자율적으로 운영될 수 있도록 설계되었습니다. 200K 토큰의 컨텍스트 윈도우와 64K 토큰의 출력 용량을 갖추고 있어, 대규모 코드베이스를 통째로 이해하고 장시간에 걸친 복잡한 작업을 수행할 수 있습니다.
OSWorld 벤치마크에서 61.4%를 기록한 것도 이 맥락에서 이해해야 합니다. OSWorld는 AI가 실제 컴퓨터 환경에서 마우스 클릭, 키보드 입력, 파일 관리 등을 수행하는 능력을 측정합니다. Sonnet 4의 42.2%에서 61.4%로의 도약은 AI 에이전트가 단순한 코드 생성을 넘어 실제 업무 환경에서 자율적으로 작동할 수 있는 수준에 근접했음을 보여줍니다.
TAU-bench 결과도 인상적입니다. 통신 분야 98.0%, 소매 분야 86.2%, 항공 분야 70.0%의 에이전트 작업 성공률은 고객 서비스, 데이터 처리, 시스템 관리 등 실제 비즈니스 시나리오에서의 활용 가능성을 직접적으로 보여주는 수치입니다.
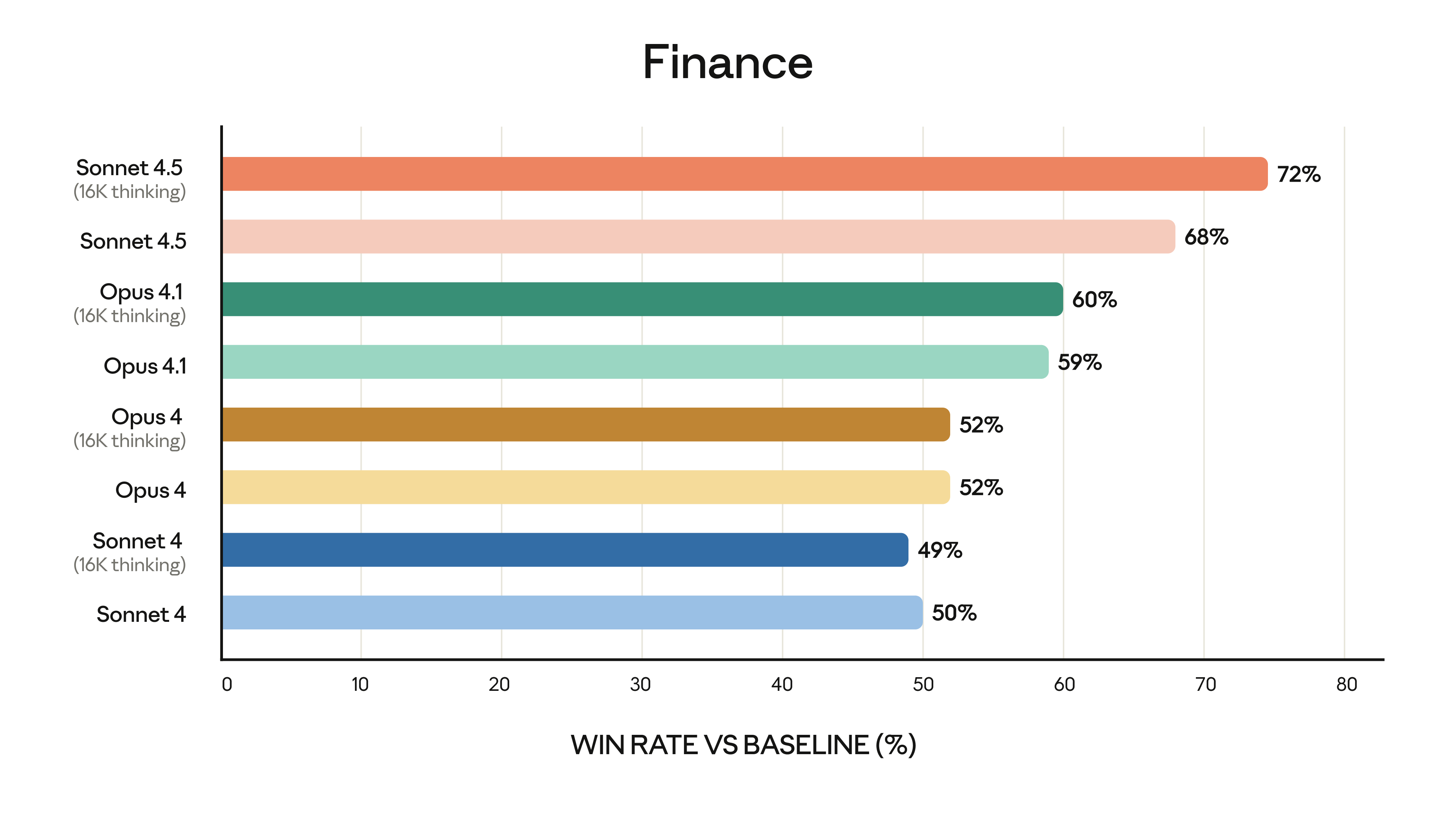
$3/$15 가격 전략: 미드티어의 파괴력
Claude Sonnet 4.5의 가장 놀라운 측면은 가격일 수 있습니다. 입력 토큰 100만 개당 $3, 출력 토큰 100만 개당 $15. 이것은 Anthropic의 최상위 모델인 Opus와 비교하면 훨씬 저렴한 미드티어 가격대입니다.
플래그십 모델보다 저렴하면서도 SWE-bench에서 GPT-5 Codex를 능가하는 성능을 보여준다는 것은 “비싼 모델이 더 좋다”는 공식이 더 이상 통하지 않음을 의미합니다. 스타트업부터 대기업까지, API 비용은 AI 도입의 핵심 변수입니다. Claude Sonnet 4.5는 성능과 비용의 최적점을 새롭게 정의했습니다.
AIME 2025 수학 벤치마크에서 Python 활용 시 만점(100%), 미활용 시에도 87%를 기록한 것은 이 가격대에서는 전례 없는 수준입니다. GPQA Diamond 83.4%와 함께, Sonnet 4.5는 코딩뿐 아니라 추론과 과학 분야에서도 미드티어의 한계를 넘어선 성능을 보여줍니다.
ASL-3 안전 등급과 실전 적용 시 고려사항
Anthropic은 Claude Sonnet 4.5에 ASL-3 안전 등급을 적용했습니다. 이는 Anthropic의 안전 기준 중 높은 수준으로, 기업 환경에서의 도입 시 규제 준수 측면에서 중요한 요소입니다. 30시간 이상 자율 운영되는 모델이라면, 안전 장치는 선택이 아닌 필수입니다.
실전 적용 관점에서 Claude Sonnet 4.5는 몇 가지 분명한 강점을 보여줍니다. 첫째, 대규모 코드베이스 리팩토링이나 마이그레이션 작업에서 200K 컨텍스트 윈도우가 큰 힘을 발휘합니다. 둘째, CI/CD 파이프라인에 통합하여 자동 코드 리뷰와 버그 픽스를 수행할 수 있습니다. 셋째, 64K 출력 용량 덕분에 긴 코드 파일 전체를 한 번에 생성하거나 수정할 수 있습니다.
물론 모든 상황에서 최선은 아닙니다. 단순한 텍스트 생성이나 가벼운 대화에는 더 저렴한 Haiku 모델이 적합할 수 있고, 최고 수준의 추론이 필요한 연구 작업에는 여전히 Opus급 모델이 필요할 수 있습니다. 중요한 것은 Claude Sonnet 4.5가 “코딩 + 에이전트 작업”이라는 가장 수요가 큰 영역에서 가격 대비 최고의 성능을 제공한다는 점입니다.
결론: 2025년 미드티어 AI 모델의 새로운 정의
Claude Sonnet 4.5는 “미드티어”라는 라벨이 무색할 정도의 성능을 보여줍니다. SWE-bench 77.2%로 GPT-5 Codex와 Gemini 2.5 Pro를 넘어선 코딩 능력, 30시간 이상의 자율 운영, 200K/64K의 넉넉한 토큰 용량, 그리고 $3/$15의 합리적인 가격. 이 조합은 2025년 AI 모델 시장에서 가장 매력적인 가성비를 만들어냅니다.
AI 기반 개발 워크플로우를 구축하거나 기존 시스템에 AI 에이전트를 도입하려는 팀이라면, Claude Sonnet 4.5는 현재 시점에서 가장 먼저 검토해야 할 모델입니다. 벤치마크 숫자만으로는 부족하다면, 실제 프로젝트에 적용해보는 것이 가장 확실한 답이 될 것입니다.
AI 에이전트 도입이나 자동화 파이프라인 구축에 대해 더 알고 싶으시다면, Sean Kim에게 문의해 보세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}