
Logitech G Pro X 60 Lightspeed Review: 5 Reasons KEYCONTROL Changes Everything (and 3 It Doesn’t)
May 26, 2025
Kemper Profiler MK 2: 20 FX Blocks, USB Audio, and a Lighter Stage — Everything That Changed
May 27, 2025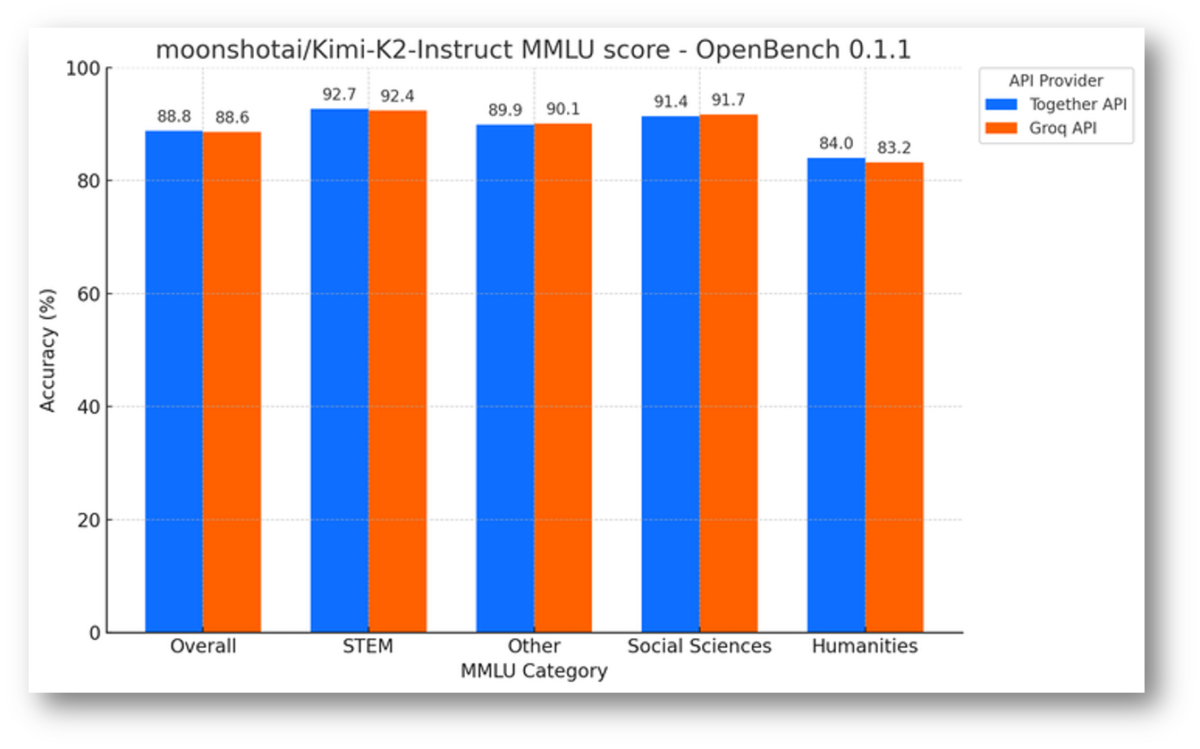
625 tokens per second. That’s not a typo, and it’s not a synthetic benchmark from a lab nobody’s heard of. That’s Groq’s LPU running Meta’s Llama models in production — processing language roughly 10 to 18 times faster than NVIDIA’s best H100 GPU clusters. If you’ve ever waited three, five, or ten seconds for a large language model to finish generating a response, Groq LPU inference is about to make that wait feel like a relic of the dial-up era.
As a tech CEO who builds AI-powered automation pipelines daily, I’ve been watching Groq’s trajectory since their first public benchmark. The speed numbers are impressive, yes — but what actually matters is what this speed enables. Real-time AI conversations. Instant code generation. Voice assistants that respond before you finish blinking. The implications for enterprise applications are enormous, and the industry is starting to pay attention.
What Is Groq LPU Inference and Why Should You Care?
Groq’s LPU — Language Processing Unit — is a fundamentally different approach to AI inference. While NVIDIA GPUs were originally designed for graphics rendering and later adapted for AI workloads, Groq built the LPU from scratch specifically for sequential text generation, the exact operation that powers every chatbot, code assistant, and AI agent you use today.
The architectural difference is significant. GPUs rely on external HBM (High Bandwidth Memory), caches, and branch predictors — all of which introduce variability and latency. The LPU uses deterministic execution with large on-die SRAM memory. Every instruction takes a fixed number of cycles. There’s no guessing, no cache misses, no unpredictable delays. The result is sub-millisecond latency and throughput that makes GPU-based inference look sluggish by comparison.
The Numbers: Groq LPU Inference Benchmarks That Stunned the Industry
When Groq first appeared on the ArtificialAnalysis.ai benchmark in early 2024, the results were jaw-dropping. On Llama 2 70B — a model with 70 billion parameters — Groq’s LPU achieved 241 tokens per second. That was more than double the speed of any other cloud-based inference provider at the time, delivering 3 to 18 times faster throughput across different model sizes.
The numbers have only improved since then. Here’s where things stand as of mid-2025:
- Llama 2 7B: Up to 750 tokens/second
- Llama 3 70B: 300+ tokens/second
- Latest Llama models via Meta partnership: Up to 625 tokens/second
- Time to first token: Significantly lower than any GPU-based alternative
To put this in perspective, most GPU-based inference providers deliver 30 to 60 tokens per second on comparable models. Groq isn’t marginally faster — it’s an order of magnitude faster. And in AI applications, speed isn’t just a nice-to-have; it’s the difference between a usable product and a frustrating one.
Meta Partnership: Why This Validates Everything
On April 29, 2025, Meta made a move that sent a clear signal to the entire AI industry. At LlamaCon, Meta announced that Groq would power the official Llama API. Not AWS. Not Google Cloud. Not NVIDIA’s own inference platform. Groq.
This partnership isn’t just a business deal — it’s a technical endorsement. Meta, the company that builds the Llama models, chose Groq’s LPU infrastructure to deliver the best possible experience for developers using their models. According to Meta and Groq’s joint announcement, developers can migrate to the Llama API with just three lines of code, with no cold starts, no GPU configuration, and no performance tuning required.
As TechRepublic reported, this partnership positions the LPU as “the world’s most efficient inference chip” and signals a broader industry validation of purpose-built inference hardware over general-purpose GPUs. When the largest open-source AI model provider in the world picks your chip over NVIDIA, that’s not a marketing claim — it’s a market shift.
LPU vs GPU: Why Architecture Matters for Groq LPU Inference
The GPU vs LPU debate isn’t about which chip is “better” in absolute terms. It’s about what each chip was designed to do. GPUs are parallel processing powerhouses. They excel at training AI models, where you need to process massive batches of data simultaneously. But inference — generating one token at a time in sequence — is a fundamentally different workload.
Think of it this way: GPUs are like a massive highway with 10,000 lanes. Great for moving a lot of traffic in bulk. But if you need one car to get from point A to point B as fast as possible, all those extra lanes don’t help. The LPU is more like a single, perfectly optimized track — no traffic lights, no intersections, no delays. One car, maximum speed.
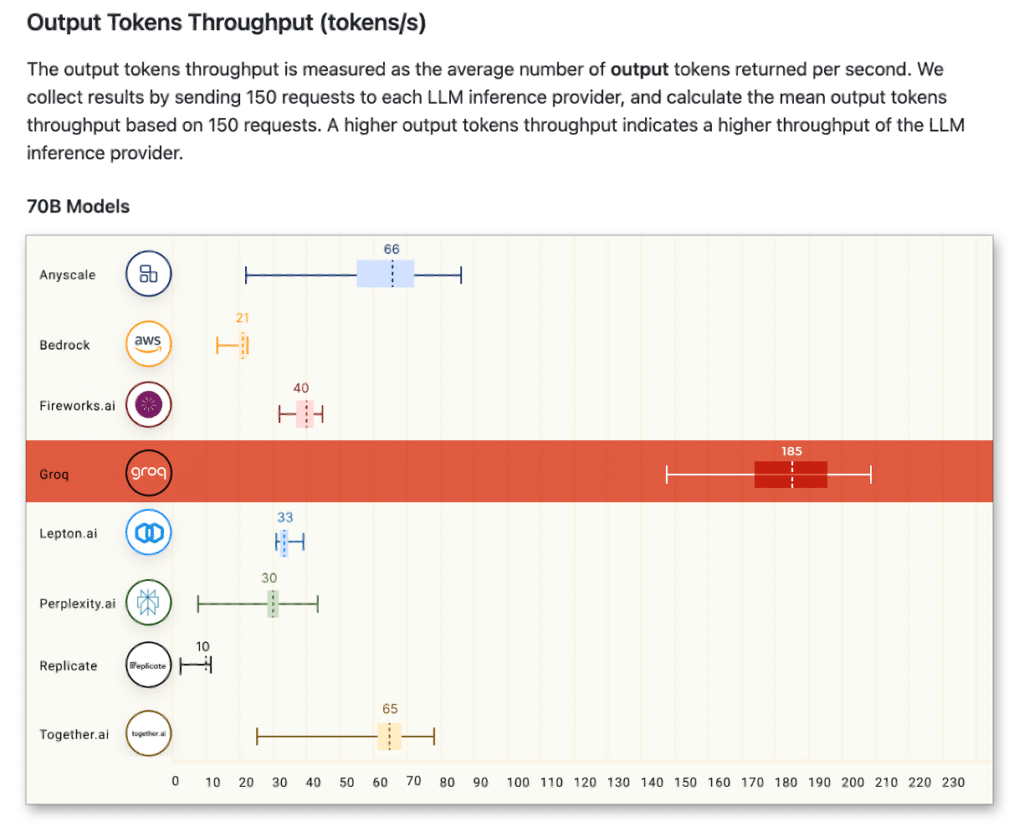
The technical specifics matter here. The LPU eliminates the memory bandwidth bottleneck that plagues GPU inference. By using on-die SRAM instead of external HBM, data doesn’t need to travel across a bus to reach the processing units. Groq claims over 5x better energy efficiency than GPUs for inference workloads — a critical factor when you’re running inference at scale for millions of API calls per day.
GroqCloud and the Developer Ecosystem: 1.9 Million and Counting
Speed means nothing without accessibility. Groq understands this, which is why they built GroqCloud — a developer platform that now serves over 1.9 million developers. The API is OpenAI-compatible, meaning existing applications can switch to Groq infrastructure with minimal code changes. For developers who’ve been locked into GPU-based cloud providers, this is a compelling alternative.
The funding tells the story of demand. In August 2024, Groq raised $640 million in a Series D round at a $2.8 billion valuation, with plans to deploy over 100,000 LPUs in the cloud by early 2025. Enterprise customers already include Dropbox (using Groq for document intelligence), Volkswagen (powering in-car AI assistants), and Riot Games (real-time player support). These aren’t experiments — they’re production deployments where inference speed directly impacts user experience.
And then there’s the Saudi Arabia factor. A reported $1.5 billion investment from Saudi Arabia signals that sovereign AI infrastructure is becoming a global priority, and Groq’s LPU is positioned as the inference backbone for AI deployments that demand both speed and energy efficiency.
The NVIDIA Question: Can Groq Actually Challenge GPU Dominance?
Let’s be honest about the elephant in the server room. NVIDIA controls roughly 80-90% of the AI chip market. Their CUDA ecosystem is deeply entrenched. Thousands of AI companies have built their entire infrastructure around NVIDIA GPUs. Groq isn’t going to replace NVIDIA overnight — or possibly ever.
But that’s not really the point. The AI compute market is splitting into two distinct workloads: training and inference. NVIDIA dominates training, and that’s unlikely to change soon. But inference — the workload that generates revenue for every AI application — is a different game. As AI moves from research labs to production applications, inference compute is growing exponentially faster than training compute. Some analysts estimate inference will account for 70-80% of total AI compute spending within the next two to three years.
This is where Groq’s bet makes strategic sense. You don’t need to defeat NVIDIA across the board. You just need to own the inference layer — and if your chip is 10x faster and 5x more energy-efficient for that specific workload, the economics eventually speak for themselves. The cost question, as analyzed by SemiAnalysis, remains: can Groq’s speed advantage justify the infrastructure investment compared to NVIDIA’s broader ecosystem? The Meta partnership suggests the market is starting to answer yes.
What This Means for Real-Time AI Applications
From my perspective as someone who builds AI automation systems, the most exciting implication of Groq LPU inference isn’t raw speed — it’s what that speed unlocks. At 500+ tokens per second, AI responses feel instantaneous. That changes the entire design paradigm for AI applications.
Consider real-time voice AI. Current GPU-based inference introduces enough latency to create an awkward pause in conversation. At Groq speeds, an AI voice assistant can respond as naturally as a human. Real-time code generation becomes truly interactive — you type a comment, and the code appears before you finish thinking about the next line. Customer support bots that previously felt like talking to a wall can suddenly hold natural, flowing conversations.
For enterprise customers like Volkswagen and Dropbox, this isn’t about bragging rights. It’s about product quality. A car AI assistant that takes three seconds to respond is annoying. One that responds in 200 milliseconds feels like magic. That’s the gap Groq is closing.
The broader industry shift is clear: AI inference is moving from “fast enough” to “real-time,” and purpose-built hardware like Groq’s LPU is leading that transition. Whether NVIDIA responds with their own inference-optimized architecture or Groq continues to carve out this niche, the winner is every developer and every end user who gets faster, more responsive AI applications.
The race for real-time AI inference is no longer theoretical. With Meta’s endorsement, nearly 2 million developers on GroqCloud, and enterprise deployments already in production, Groq’s LPU has moved from “interesting startup” to “legitimate industry force.” The next 12 months will determine whether this is the beginning of a genuine architectural shift — or a speed advantage that gets absorbed into NVIDIA’s ever-expanding roadmap. Either way, AI just got a lot faster.
Interested in how inference speed and AI architecture decisions impact your tech stack? Let’s talk about building faster AI systems.
Get weekly AI, music, and tech trends delivered to your inbox.


{kind=link}
{kind=link}
{kind=link}