
Amazon Prime Day 2025: 15 Best Tech Deals on Laptops, Monitors, and Gadgets Worth Every Dollar
July 30, 2025
Ableton Push 3 Summer Update: Follow Actions, 16 Pitches, and a Completely Rebuilt Auto Filter
July 31, 2025
On July 10, 2025, xAI dropped a bomb on the AI industry. Grok 4 didn’t just beat benchmarks — it shattered them. A perfect 100% on AIME 2025 (math olympiad). 88.9% on GPQA Diamond (PhD-level science). And suddenly, the comfortable two-horse race between OpenAI and Anthropic became a three-way war.
But here’s the thing about benchmarks: they tell a story, not the whole truth. After spending weeks testing all three models in real production workflows — from code generation to technical writing to data analysis — I can tell you the numbers only scratch the surface. Let’s break down what actually matters when choosing between Grok 4, GPT-4o, and Claude 3.5 Sonnet in July 2025.
The Grok 4 vs GPT-4o vs Claude 3.5 Benchmark Numbers: Raw Performance
First, let’s look at the hard data. These aren’t cherry-picked numbers — they come from Artificial Analysis and independent benchmark verifications.
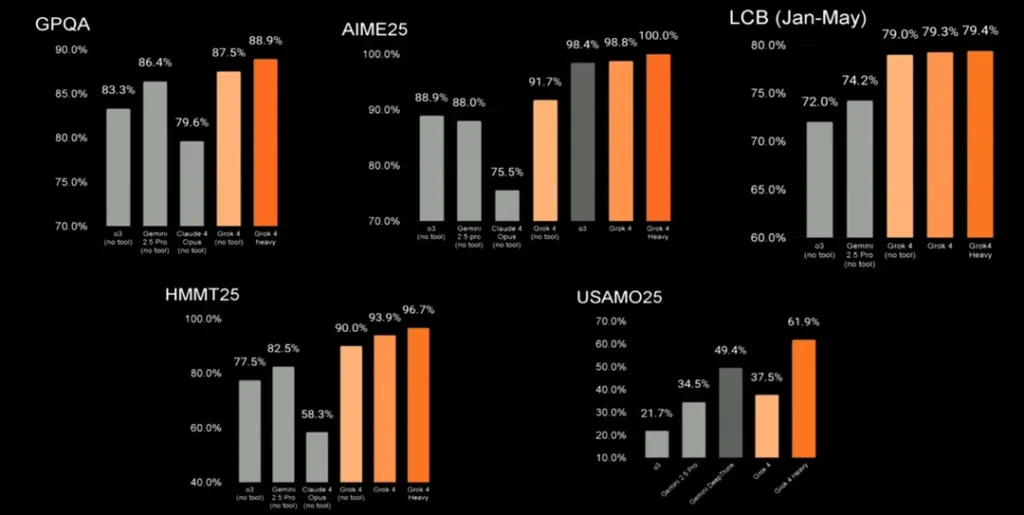
GPQA Diamond (PhD-Level Scientific Reasoning)
This is the benchmark that separates toy models from serious reasoning engines. It tests graduate-level understanding across physics, chemistry, and biology.
- Grok 4 Heavy: 88.9% — New state-of-the-art
- Grok 4 (standard): 87.5%
- GPT-4o: 85.0%
- Gemini 2.5 Pro: 83.3%
- Claude 3.5 Sonnet: 59.4% (0-shot CoT)
The gap here is striking. Grok 4 Heavy leads by nearly 4 points over GPT-4o, while Claude 3.5 Sonnet — despite being excellent at many tasks — falls significantly behind on pure scientific reasoning. Note: Claude 3.5 Sonnet’s score uses zero-shot chain-of-thought prompting, which may differ from the extended thinking approaches used by Grok 4 and GPT-4o’s reasoning modes.
AIME 2025 (Math Olympiad)
The American Invitational Mathematics Examination is brutally hard — designed for the top 2.5% of high school math students. Here’s where Grok 4 truly flexes:
- Grok 4 Heavy: 100.0% — Perfect score
- Grok 4: 98.4%
- GPT-4o: 91.7%
- Gemini 2.5 Pro: 88.9%
A perfect score on AIME 2025. Let that sink in. While GPT-4o’s 91.7% is impressive by any standard, xAI’s latest model solved every single problem. This represents a genuine leap in mathematical reasoning capability.
HMMT 2025 and USAMO 2025 (Advanced Math)
The Harvard-MIT Math Tournament and USA Mathematical Olympiad push reasoning even further:
- HMMT 2025: Grok 4 Heavy 96.7% vs GPT-4o 77.5% vs Gemini 82.5%
- USAMO 2025: Grok 4 Heavy 61.9% vs GPT-4o 21.7% vs Gemini 34.5%
USAMO is where the real separation happens. Grok 4 Heavy nearly triples GPT-4o’s score, demonstrating a qualitative leap in mathematical proof-writing ability. This isn’t just about getting the right answer — it’s about constructing rigorous mathematical arguments.
Beyond Benchmarks: Where Each Model Actually Excels
Numbers on a leaderboard don’t tell you which model to use for your actual work. Here’s what weeks of real-world testing revealed:
Grok 4: The Reasoning Powerhouse
Grok 4 is purpose-built for deep thinking. With a 256K context window and an extended reasoning pipeline (xAI calls it “the big run”), it approaches problems more like a researcher than a chatbot. The SWE-Bench score of 72-75% puts it among the best for real-world software engineering tasks.
Best for: Complex mathematical proofs, scientific research, multi-step coding problems, tasks requiring deep logical chains.
Watch out for: Speed. With a time-to-first-token of 14.15 seconds (vs. GPT-4o’s ~0.5s), Grok 4 thinks before it speaks. Output speed sits at 44.5 tokens/second — adequate but not fast. And at $3/$15 per million tokens (input/output), extended reasoning sessions add up quickly.
GPT-4o: The Balanced Performer
GPT-4o remains the most versatile model on the market. While it doesn’t top the reasoning benchmarks anymore, it delivers consistently strong performance across every category. The 85% GPQA and 91.7% AIME scores are nothing to scoff at — and it does it all at significantly faster speeds.
Best for: General-purpose work, multimodal tasks (vision + text), fast iteration, production APIs that need low latency. GPT-4o’s MATH benchmark score of 76.6% and its MMLU score of 85.7% show it handles diverse knowledge domains reliably.
Watch out for: At $5/$15 per million tokens, it’s the most expensive per input token among the three. And for bleeding-edge reasoning tasks, Grok 4 now has a clear advantage.
Claude 3.5 Sonnet: The Coding and Writing Champion
Claude 3.5 Sonnet’s lower GPQA score (59.4%) might look alarming, but context matters. Where Claude absolutely dominates is in practical coding tasks and long-form content generation. In Anthropic’s internal agentic coding evaluation, Claude 3.5 Sonnet solved 64% of problems — a figure that professional developers consistently validate in real-world use.
Best for: Code generation and debugging, long-document analysis (200K context window — largest of the three), technical writing, instruction-following tasks. Its Multilingual Math score of 91.6% also makes it the best choice for non-English mathematical content.
Watch out for: Pure scientific reasoning isn’t its strongest suit. If you need PhD-level physics or complex mathematical proofs, Grok 4 or GPT-4o will serve you better.
The Pricing Reality Check
Let’s talk money, because the best model means nothing if it bankrupts your API budget:
- Grok 4: $3.00 input / $15.00 output per 1M tokens (but verbose — generates ~88M tokens in extended evals)
- GPT-4o: $5.00 input / $15.00 output per 1M tokens
- Claude 3.5 Sonnet: $3.00 input / $15.00 output per 1M tokens
On paper, Grok 4 and Claude 3.5 Sonnet tie at $3 per million input tokens, with GPT-4o costing 67% more. But Grok 4’s verbosity is a hidden cost — Artificial Analysis noted it ranked #112 out of 123 models for verbosity, meaning it generates significantly more output tokens per query. Your real-world costs with Grok 4 could be substantially higher than the per-token price suggests.
For budget-conscious developers, xAI also offers Grok 4 Fast at just $0.20/$0.50 per million tokens — a dramatic discount if you can tolerate potentially lower quality on complex reasoning tasks.
The Controversy Factor
No honest comparison of Grok 4 can ignore the elephant in the room: benchmark controversy. Some researchers have questioned whether xAI’s self-reported numbers hold up under independent verification. The ARC Prize Foundation did independently verify the ARC-AGI-2 score of 15.9%, which lends some credibility. But Artificial Analysis’s own Intelligence Index places Grok 4 at #29 out of 123 models with a score of 42 — well above average but not the dominant #1 position xAI’s marketing implies.
The takeaway: trust verified benchmarks over marketing claims. Grok 4 is genuinely impressive, but the gap between xAI’s claims and independent analysis suggests the real performance sits somewhere in between.
Which Model Should You Pick? A Practical Decision Framework
After testing all three extensively, here’s my honest recommendation:
- Choose Grok 4 if: You need maximum reasoning depth — math proofs, scientific analysis, complex multi-step problems. You’re willing to wait for quality and pay for verbosity.
- Choose GPT-4o if: You need a reliable all-rounder with fast responses. Production APIs, multimodal tasks, or any workflow where latency matters more than peak reasoning.
- Choose Claude 3.5 Sonnet if: Your primary workload is coding, long-document processing, or content generation. The 200K context window is unmatched, and real-world coding performance is arguably the best of the three.
The reality is that July 2025 marks the point where we stopped having a single “best” AI model. Each of these three has carved out a genuine niche, and the smartest approach is to use all three strategically based on your specific use case. The era of one-model-fits-all is officially over.
Need help building AI-powered automation pipelines or choosing the right model for your workflow? Let’s talk strategy.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}