Baby Audio Grainferno Review: A $79 Granular Synth That Shouldn’t Exist at This Price
March 13, 2026
C++26 Feature Complete — Static Reflection, Contracts, and std::execution Will Reshape How You Write C++
March 13, 2026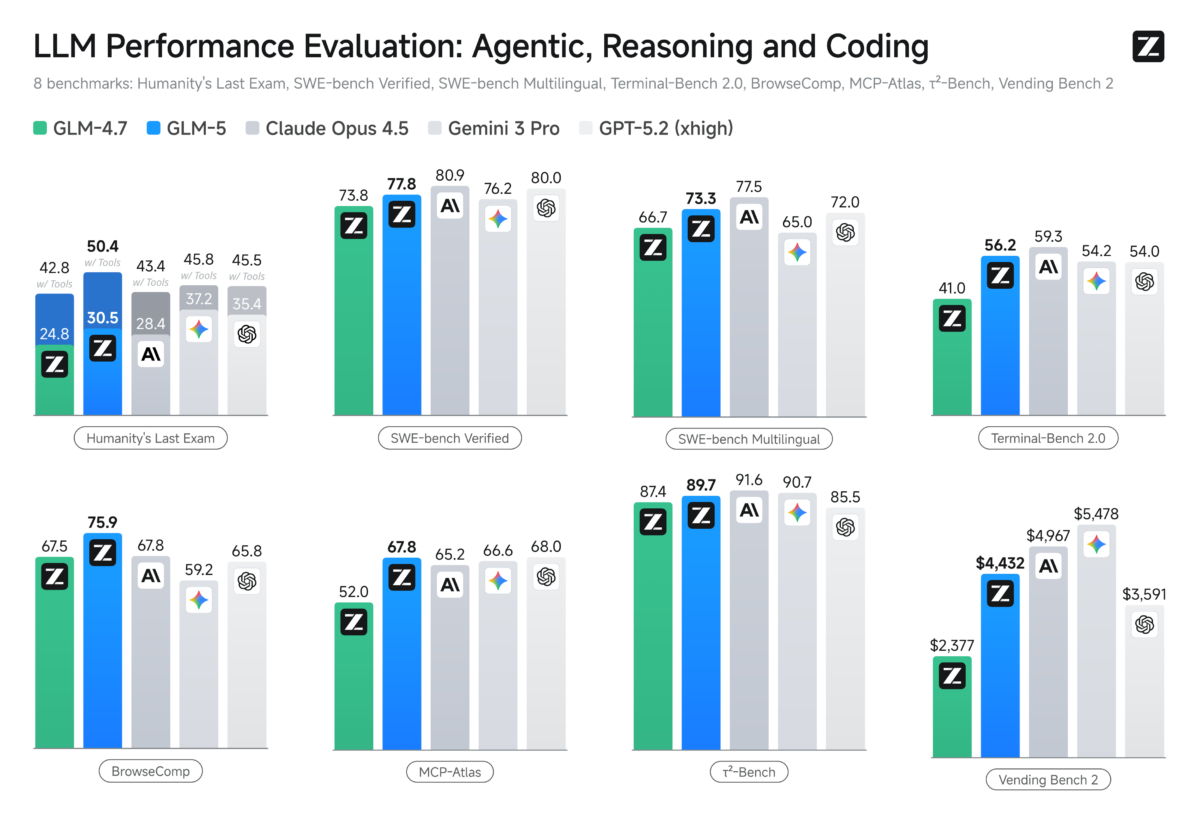
A 744 billion parameter AI model just matched GPT-5.2 on key benchmarks — and it was trained entirely on Huawei chips. No NVIDIA silicon. Not a single A100 or H100 in sight. Zhipu AI’s GLM-5 dropped this week as a fully open-source model under MIT license, and the implications for the global AI landscape are nothing short of seismic. Here is what developers, engineering managers, and tech leaders need to know about GLM-5 Zhipu AI and why it could reshape how we think about AI infrastructure in 2026.
GLM-5 Zhipu AI Architecture: 744B Parameters, 44B Active
GLM-5 is a Mixture of Experts (MoE) model with a total of 744 billion parameters. During inference, only 44 billion parameters are active at any given time — which means you get frontier-level intelligence at a fraction of the compute cost. The model weights are publicly available on Hugging Face under MIT license, making it one of the most permissive frontier-class models ever released.
For those unfamiliar with MoE architecture, the concept is elegant: instead of routing every token through all 744 billion parameters, the model activates only a subset of specialized “expert” sub-networks for each input. This design choice is what allows GLM-5 to deliver performance comparable to dense models many times its effective compute size. It is the same fundamental approach that powers models like Mixtral and Switch Transformer, but scaled to an unprecedented degree.
What makes GLM-5 truly unprecedented is its training infrastructure. Zhipu AI trained this model on 100,000 Huawei Ascend 910B chips using the MindSpore framework. Zero NVIDIA dependency. In the context of ongoing US semiconductor export controls against China, this is a landmark achievement — proof that China’s domestic chip ecosystem can produce world-class AI models without relying on Western hardware supply chains.
The Ascend 910B, Huawei’s flagship AI training chip, has been positioned as a direct alternative to NVIDIA’s A100 since its launch. However, until GLM-5, no organization had publicly demonstrated that Ascend chips could train a frontier-class model at this scale. The fact that Zhipu AI pulled it off with 100,000 of these chips running MindSpore — Huawei’s open-source deep learning framework — validates the entire domestic Chinese AI hardware stack in a way that benchmarks alone never could.
- Total parameters: 744B (Mixture of Experts)
- Active parameters: 44B (during inference)
- Training hardware: Huawei Ascend 910B x 100,000 chips
- Framework: MindSpore
- License: MIT (fully open-source, commercial use permitted)
- Inference cost: 5-6x cheaper than GPT-5.2
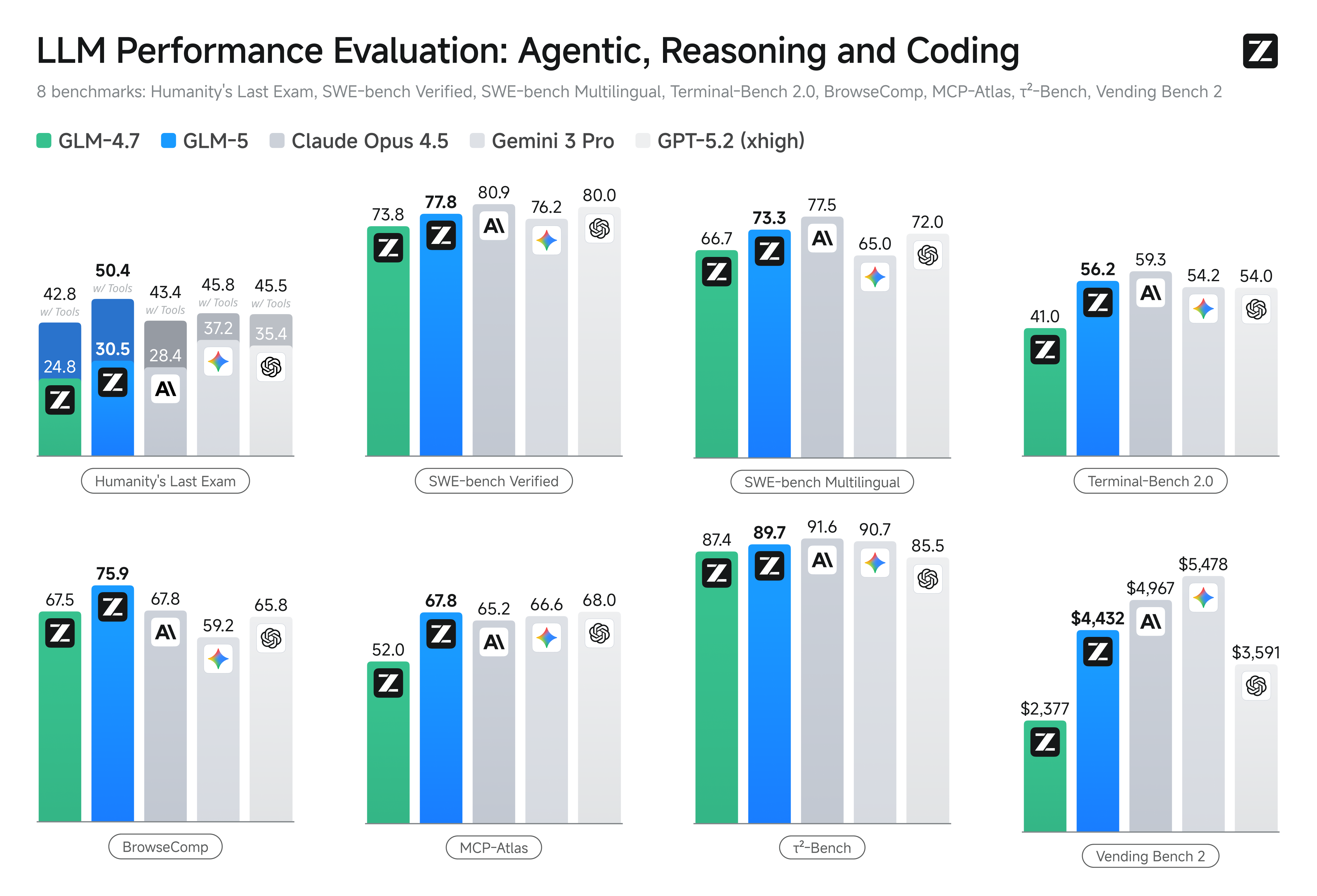
Benchmark Results: SWE-bench 77.8% and Humanity’s Last Exam Scores
The numbers are hard to ignore. GLM-5 Zhipu AI scored 77.8% on SWE-bench, the gold standard for evaluating AI models on real-world software engineering tasks. SWE-bench tests a model’s ability to resolve actual GitHub issues — reading codebases, understanding context, writing patches, and running tests. A score of 77.8% puts GLM-5 in direct competition with GPT-5.2 and other frontier models from OpenAI and Anthropic on the task that matters most to software developers.
On Humanity’s Last Exam — a test designed by top experts across multiple fields to push AI reasoning to its absolute limits — GLM-5 scored 30.5 points baseline and 50.4 points with tool use. To put that in perspective, Humanity’s Last Exam includes problems from advanced mathematics, physics, philosophy, and specialized domains that were specifically crafted to be unsolvable by current AI systems. The fact that GLM-5 can score above 50 with tool augmentation suggests its reasoning capabilities extend well beyond pattern matching into genuine problem-solving territory.
Perhaps the most compelling metric for businesses is cost. GLM-5’s API pricing comes in at 5-6x cheaper than GPT-5.2. When you are running millions of inference calls per day, that cost difference is not marginal — it is transformative. Consider a company spending $50,000 per month on GPT-5.2 API calls for code review automation. Switching to GLM-5 could reduce that bill to under $10,000 while maintaining comparable output quality. For startups and enterprises building AI-powered products, GLM-5 opens up use cases that were previously cost-prohibitive.
It is worth noting that independent benchmark verification is still ongoing. While Zhipu AI’s published results are promising, the AI community has learned to wait for third-party confirmation before making production decisions based on self-reported scores. Early independent tests from several research groups appear to corroborate the headline figures, but comprehensive evaluation across all task categories will take several more weeks.
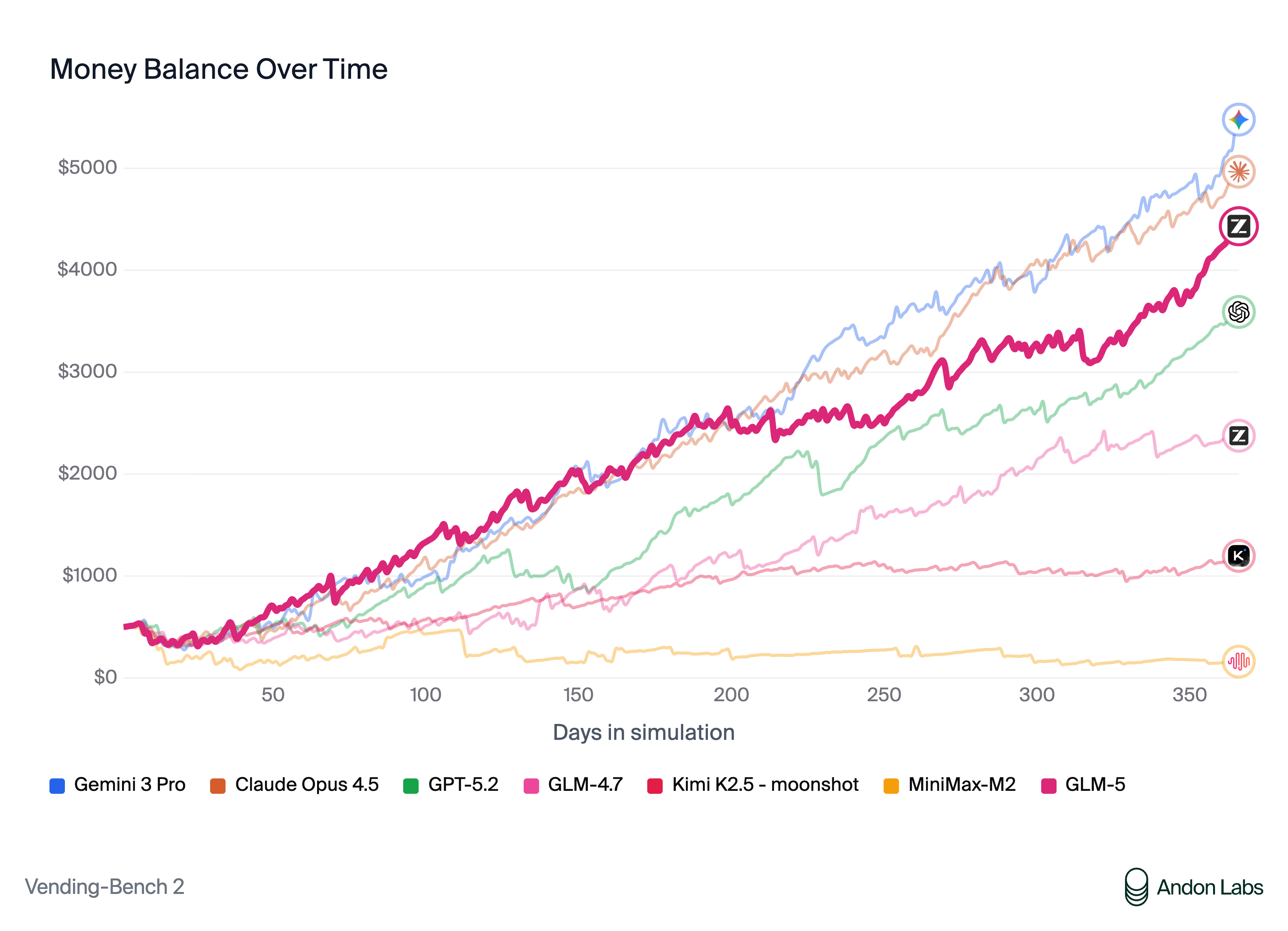
The Geopolitical Dimension: What Zero-NVIDIA Training Means for Global AI
Let us be direct about what GLM-5 represents beyond the benchmarks. The US government has spent the past three years tightening semiconductor export controls to slow China’s AI development. The strategy assumed that cutting off access to NVIDIA’s cutting-edge GPUs would create an insurmountable bottleneck — that without H100s and A100s, Chinese labs simply could not train competitive frontier models.
GLM-5 challenges that assumption head-on. According to the South China Morning Post, Zhipu AI has become the first company to develop a genuine frontier model using exclusively domestic Chinese chips. Coming after DeepSeek R1’s earlier breakthrough, GLM-5 suggests that China’s AI ecosystem is not just surviving the chip restrictions — it is adapting and, in some areas, thriving. The export controls may have slowed China’s progress, but they clearly did not halt it.
This has significant implications for the broader AI industry. If frontier models can be trained on non-NVIDIA hardware at competitive quality levels, it undermines the moat that NVIDIA has built around its CUDA ecosystem. It also raises questions about the long-term effectiveness of hardware-based export controls as a tool for maintaining technological advantage. Other nations and organizations watching this development will likely accelerate their own efforts to build NVIDIA-independent AI training capabilities.
For the global open-source AI community, the MIT license is the real story. Unlike some models that come with restrictive use clauses or unclear commercial terms, GLM-5’s weights can be freely downloaded, fine-tuned, and deployed in commercial applications without restrictions. Combined with Meta’s Llama series and Mistral’s offerings, the open-source frontier is now firmly competitive with proprietary offerings — and the performance gap is shrinking with every major release.
Practical Considerations: Should You Use GLM-5 Today?
GLM-5 excels at coding tasks, mathematical reasoning, and multilingual processing. A 77.8% SWE-bench score means it can handle real software engineering workflows — think automated code review, bug detection, test generation, and large-scale refactoring. At 5-6x lower cost than GPT-5.2, it is particularly attractive for high-volume production pipelines where you need thousands of inference calls per hour.
For enterprise teams evaluating GLM-5 as a potential replacement or supplement to existing model providers, here is a practical roadmap. Start by identifying your highest-volume, lowest-risk AI workloads — things like document summarization, code linting, or internal knowledge retrieval. Run GLM-5 in parallel with your current model for two to four weeks and compare quality scores, latency, and cost. Only after validating on non-critical workloads should you consider migrating customer-facing applications.
That said, there are caveats worth noting. The MoE architecture requires significant memory for local deployment of the full model — you will need a multi-GPU setup with substantial VRAM to run it on-premises. Since training was optimized for Huawei’s Ascend chips and MindSpore framework, inference performance on NVIDIA hardware may vary and needs independent verification. Initial community reports suggest the model runs well on standard NVIDIA setups through Hugging Face Transformers, but optimized inference kernels for CUDA are still being developed.
The open-source community is already building around GLM-5 — expect quantized versions (GPTQ, AWQ, GGUF), LoRA adapters for domain-specific fine-tuning, and specialized distilled variants to appear on Hugging Face within weeks. If you are currently paying premium prices for GPT-5.2 or Claude Opus API calls in production, GLM-5 deserves a serious evaluation as an alternative or supplementary model in your inference stack.
The AI model landscape in 2026 is evolving faster than ever. GLM-5 Zhipu AI represents a convergence of three powerful trends that every technology professional should be tracking: open-source models reaching parity with proprietary offerings, dramatic cost reduction making AI accessible to smaller organizations, and technological independence from NVIDIA’s hardware ecosystem. Whether you are a developer choosing your next foundation model, an engineering manager optimizing your AI budget, or a CTO planning your long-term infrastructure strategy, GLM-5 is a model you cannot afford to overlook.
Need expert guidance on AI model selection, deployment, or pipeline architecture?



{kind=link}
{kind=link}
{kind=link}