
Black Friday 2025: Best Gaming PC and Component Deals — GPUs, CPUs, SSDs Worth Grabbing
November 6, 2025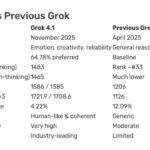
xAI Grok 4.1 — 65% Fewer Hallucinations, #1 on LM Arena, and What It Actually Means
November 10, 2025
November 2025 just broke the AI world wide open. Anthropic dropped Claude Sonnet 4.5 on September 29 and shattered coding benchmarks. OpenAI fired back with GPT-5.1 on November 12. Then Google walked in six days later with Gemini 3 Pro and claimed the highest LMArena Elo score ever recorded. Three frontier models in under 50 days — Gemini 3 vs GPT-5.1 vs Claude Sonnet 4.5 is the AI matchup of the year, and it’s happening right now.
I’ve spent the past weeks putting all three models through their paces — benchmarks, API pricing, real coding tasks, and day-to-day usage. Here’s the complete breakdown to help you decide which model deserves your attention (and your budget) this November.

Gemini 3 vs GPT-5.1 vs Claude Sonnet 4.5: The Benchmark Battle
Let’s start with the numbers. What makes this November’s model wars so fascinating is how close these three models perform across nearly every major benchmark — we’re talking single-digit percentage differences in most categories.
Coding: SWE-bench Verified
The SWE-bench Verified benchmark tests whether AI models can autonomously resolve real GitHub issues — this isn’t toy code generation, it’s production-level software engineering. Here’s where things stand:
- Claude Sonnet 4.5: 77.2% — the highest score ever recorded
- GPT-5.1: 76.3%
- Gemini 3 Pro: 76.2%
A 1% gap might seem trivial on paper, but in practice it translates to roughly 5 additional issues resolved autonomously out of every 500. The real-world validation is even more compelling: Replit reported that Claude Sonnet 4.5 dropped their error rate from 9% to 0%, and third-party testing showed 386 out of 500 GitHub issues resolved without human intervention.
Academic Reasoning: GPQA Diamond
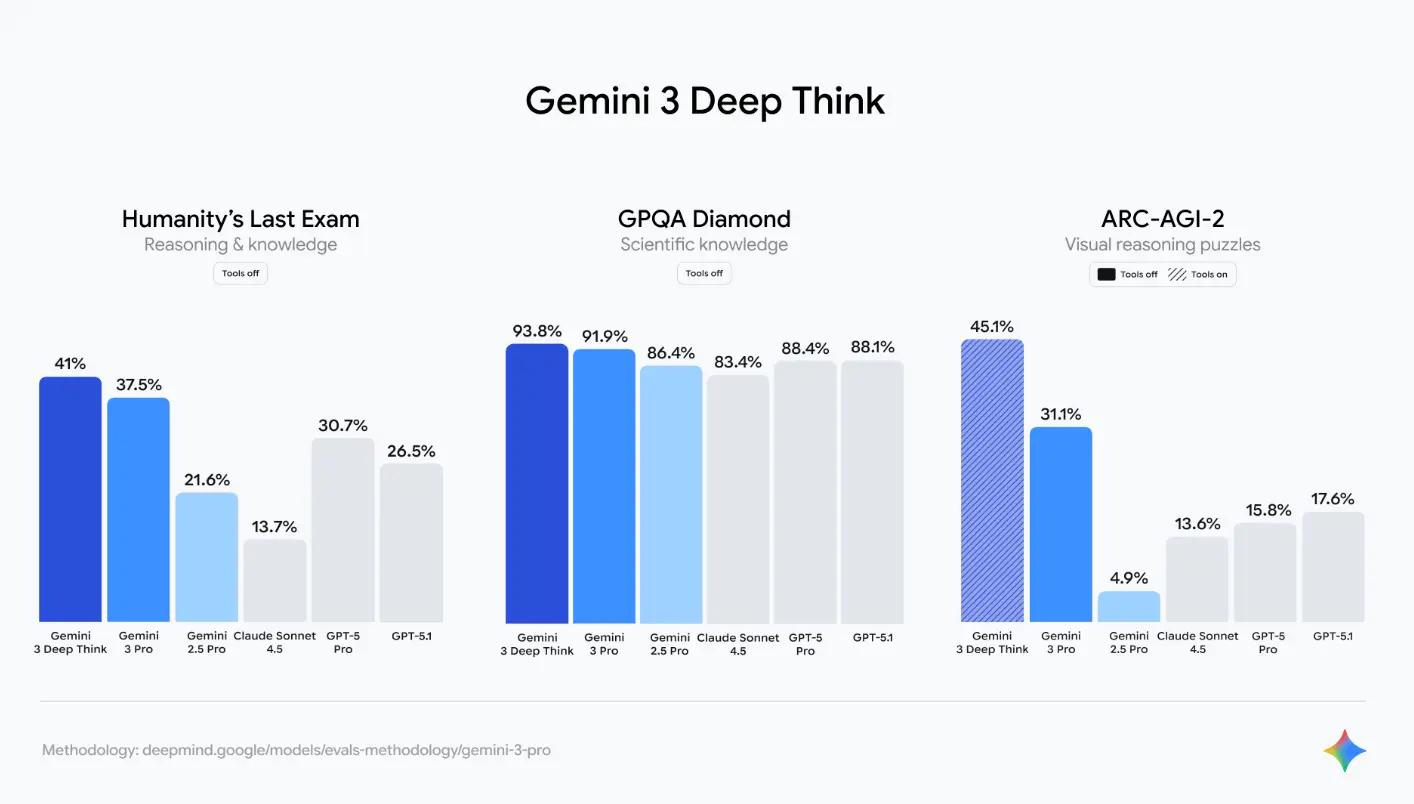
Graduate-level science Q&A tells a very different story. Gemini 3 Pro dominates GPQA Diamond with 91.9%, and its Deep Think mode pushes that to an astonishing 93.8%. For context, GPT-5 scored 85.7% and Claude Sonnet 4.5 came in at 83.4%. That’s an 8+ point lead for Google — not close at all.
The gap extends to MMMLU (multilingual multitask language understanding), where Gemini 3 Pro scores 91.8% versus 89.1% for both GPT-5 and Claude Sonnet 4.5. Google’s advantage in pure academic reasoning is substantial and consistent.
Mathematics: AIME 2025
On the American Invitational Mathematics Examination 2025 problems, both Gemini 3 Pro (100% with tools, 95% without) and Claude Sonnet 4.5 (100% with Python) achieve near-perfect scores. GPT-5.1 hasn’t published standalone AIME results yet, but its general mathematical reasoning is competitive. The math race is essentially a dead heat at the top.
The Frontier Test: Humanity’s Last Exam
Perhaps the most impressive single benchmark result belongs to Gemini 3’s Deep Think mode, which scored 40% on Humanity’s Last Exam (HLE) — a test specifically designed to stump AI models. Current frontier models typically score around 20% on HLE. Gemini 3 doubled that threshold, signaling a genuine leap in complex reasoning capability.
Multimodal and Long-Context: MMMU-Pro and MRCR
Gemini 3 Pro also leads in multimodal understanding, scoring 81.0% on MMMU-Pro (multimodal multi-discipline reasoning). Its long-context retrieval benchmark MRCR v2 at 128K tokens hits 77%, which matters enormously for developers working with large codebases or researchers processing lengthy documents. When you need to feed an entire repository or a 200-page research paper into a single prompt, Gemini 3 Pro’s 1 million token context window is unmatched — and it actually performs well at that scale, not just technically allowing it.
Pricing Comparison: Where Your Dollar Goes Furthest
When benchmark scores are this close, pricing becomes the tiebreaker for many teams. Here’s the API pricing breakdown:
- Gemini 3 Pro: $1.25/M input tokens, $5/M output tokens, 1M token context window
- GPT-5.1: $2.50/M input tokens, $10/M output tokens, 128K token context window
- Claude Sonnet 4.5: $3/M input tokens, $15/M output tokens, 200K token context window
The math is stark. Gemini 3 Pro’s output tokens cost one-third of Claude Sonnet 4.5’s price, and it offers a 1 million token context window — five times larger than Claude’s 200K and nearly eight times GPT-5.1’s 128K. For production workloads with heavy API usage, Gemini 3 Pro can save hundreds or even thousands of dollars per month compared to the alternatives.
But raw price-per-token doesn’t tell the whole story. Claude Sonnet 4.5 often produces correct code on the first attempt, meaning fewer retry loops and lower total token consumption for coding tasks. GPT-5.1’s dual Instant/Thinking modes let you route simple queries to the cheaper fast path and only engage deep reasoning when needed. Effective cost depends heavily on your specific use case.
Real-World Use Cases: Which Model Wins Where
Benchmarks and pricing are useful starting points, but what actually matters is how each model performs in your daily workflow. After extensive testing across multiple domains, here’s where each model shines brightest.
Software Development: Claude Sonnet 4.5 Takes the Crown
SWE-bench 77.2%. OSWorld 61.4% (a staggering 45% improvement over Claude Sonnet 4). Zero percent error rate on Replit. If your primary use case is writing, debugging, or refactoring code, Claude Sonnet 4.5 is the most reliable choice available right now. It excels particularly at complex codebase navigation, large-scale refactoring, and autonomous issue resolution.
The 200K context window is generous enough for most codebases, and the model’s ability to understand project-wide context before making changes sets it apart from models that treat each file in isolation. For development teams considering AI-assisted coding tools, Claude Sonnet 4.5 is the current gold standard.
Research and Academic Work: Gemini 3 Pro Dominates
GPQA Diamond 91.9%. HLE 40% with Deep Think. A 1 million token context window that can swallow entire research papers, textbooks, or codebases in a single prompt. For academic research, scientific analysis, complex mathematical proofs, and data-heavy analytical work, Gemini 3 Pro is in a league of its own.
The Vending-Bench results are particularly noteworthy — Gemini 3 Pro scored 272% higher than GPT-5.1 on agentic tasks, suggesting it’s not just smarter at answering questions but fundamentally better at executing multi-step autonomous workflows. Combined with Google’s new Antigravity coding IDE, Gemini 3 is positioning itself as the go-to model for AI agent development.
Consumer Experience and Daily Use: GPT-5.1 Leads
GPT-5.1 didn’t just upgrade the model — it reimagined how people interact with AI. The Instant mode delivers near-instantaneous responses for simple queries, while Thinking mode engages deeper reasoning when you need it. Add in shopping research capabilities (perfectly timed for Black Friday), multimodal input processing, and customizable AI personalities, and you have the most polished consumer AI experience on the market.
For teams building customer-facing chatbots or AI assistants, GPT-5.1’s conversational fluency and personality customization give it a significant edge. It feels less like talking to a machine and more like collaborating with a knowledgeable colleague.
Agentic Workflows: Gemini 3 Pro’s New Frontier
One area that deserves special attention is autonomous agent performance. On Vending-Bench, which measures a model’s ability to execute complex multi-step tasks without human guidance, Gemini 3 Pro scored 272% higher than GPT-5.1. This isn’t a marginal improvement — it’s a category-defining gap. Google’s new Antigravity coding IDE, launched alongside Gemini 3, is purpose-built for agentic software development where the AI doesn’t just suggest code but manages entire project workflows autonomously.
For teams building AI agents — whether for customer support automation, data pipeline management, or autonomous coding assistants — Gemini 3 Pro’s agentic capabilities combined with its massive context window make it the strongest foundation model available. The ability to hold an entire project’s context in memory while executing multi-step plans is a genuine differentiator that neither GPT-5.1 nor Claude Sonnet 4.5 can match at this scale.
Context Window Deep Dive: Why Size Matters More Than Ever
The context window gap between these three models is perhaps the most practically significant difference for many workflows. Gemini 3 Pro offers 1 million tokens — enough to process roughly 750,000 words or an entire medium-sized codebase in a single prompt. Claude Sonnet 4.5’s 200K tokens handle most individual tasks well but require chunking for larger projects. GPT-5.1’s 128K tokens, while respectable, feels increasingly limiting as codebases and datasets grow.
In practical terms, if you’re analyzing a full-length book, processing a quarter’s worth of financial reports, or asking an AI to understand your entire application architecture before making changes, the context window determines whether you can do it in one shot or need to break the work into pieces. Fragmented context means lost nuance and more errors — which is why Gemini 3 Pro’s 1M window isn’t just a spec sheet number, it’s a workflow transformation.
What November’s AI Wars Really Mean
The most important takeaway from November 2025’s three-way AI showdown isn’t which model “won.” It’s that the era of a single dominant AI model is over. Coding belongs to Claude. Reasoning belongs to Gemini. User experience belongs to GPT. Each model has carved out a clear domain of excellence.
For practitioners, this means the “pick one and stick with it” mentality needs to die. The smart play in late 2025 is a multi-model strategy: Claude Sonnet 4.5 for your development pipeline, Gemini 3 Pro for research and long-context analysis, and GPT-5.1 for customer-facing applications. The cost of using the wrong model for a task now exceeds the complexity of maintaining multiple integrations.
The pricing war is equally significant. Gemini 3 Pro’s aggressive $5/M output pricing puts direct pressure on OpenAI and Anthropic. Expect price drops across the board in Q1 2026. Just like Black Friday deals on consumer goods, the AI model market is entering its own discount season — and developers are the ones who benefit.
The bottom line: all three models are exceptional, each in their own domain. The smartest strategy is to match the model to the task — Claude Sonnet 4.5 for coding automation, Gemini 3 Pro for research and agentic workflows with massive context, and GPT-5.1 for the most natural conversational AI experience. The real winners this November are the developers and teams who stop asking “which is best” and start asking “which is best for this specific job.”
Building an AI pipeline or need help choosing the right model stack for your team? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}