OpenClaw NVIDIA Explained: Why Jensen Huang Called This Agentic OS ‘the Most Important Software Release Ever’ at GTC 2026
March 24, 2026
Terafab Chip Factory: Elon Musk’s $25 Billion Bet on 2nm Semiconductor Independence
March 24, 2026
Running neural networks inside GPU shaders — not as a separate compute pass, not through an external ML framework, but inline with your pixel shading code. Two years ago, this was a pipe dream. As of GDC 2026, it’s shipping. Microsoft’s DirectX ML Shader Model 6.9 introduces Cooperative Vectors, a mechanism that lets HLSL shaders execute small neural networks by pooling vector-matrix operations across wave threads. AMD, NVIDIA, Intel, and Qualcomm have all committed support. This isn’t an incremental API update — it’s the beginning of a fundamental shift in how real-time graphics pipelines work.
What DirectX ML Shader Model 6.9 Actually Ships
On February 26, 2026, Microsoft released Shader Model 6.9 in retail form through Agility SDK 1.619, with compiler support via DXC 1.9.2602.16. The feature set divides into three major categories, each addressing a different bottleneck in the neural rendering pipeline.
Long Vectors (up to 1,024 elements). Traditional HLSL caps vector sizes at 4 elements — float4 is as big as it gets. That’s fine for color values and spatial coordinates, but neural network weight matrices and activation vectors routinely require hundreds or thousands of elements. Long Vectors remove this constraint, allowing HLSL to handle the data structures that neural inference actually needs. This is the foundational change that makes everything else possible.
16-bit floating-point special functions. Neural networks increasingly operate in FP16 or mixed precision to maximize throughput. SM 6.9 adds native support for 16-bit special mathematical functions — exponentials, logarithms, trigonometric functions — that neural activation layers depend on. Previously, developers had to upcast to FP32, compute, and downcast back, wasting both precision and cycles.
DXR 1.2 with Opacity Micromaps (OMM) and Shader Execution Reordering (SER). While not directly part of the neural rendering story, these ray tracing improvements complement it perfectly. OMM accelerates alpha-tested geometry by encoding opacity information in compact bitmaps, while SER allows the GPU to reorder shader execution for better coherence during ray tracing. When combined with neural radiance caching (more on that below), these features create a significantly more efficient ray tracing pipeline.
Cooperative Vectors: The Core Innovation Behind Inline Neural Rendering
Cooperative Vectors is where the real paradigm shift lives. According to Microsoft’s technical deep dive on D3D12 Cooperative Vector, the mechanism works by collecting individual vector-matrix multiply requests from threads within a wave and combining them into accelerated matrix-matrix operations. In practical terms, this means tensor cores (or their equivalents across different GPU architectures) can be leveraged cooperatively by multiple shader threads without consuming the entire GPU.
Why does this matter so much? Consider how neural rendering worked before Cooperative Vectors. You’d render your scene traditionally, then kick off a separate ML inference pass — typically through a compute shader or an external framework like DirectML or ONNX Runtime. The results would be written to an intermediate buffer, then read back by your rendering shaders. Every transition between rendering and inference meant context switches, memory copies, and synchronization barriers. For techniques that need per-pixel neural inference (like neural texture decompression), this overhead made real-time performance impossible.
Cooperative Vectors eliminate this roundtrip entirely. The neural network runs inline within your pixel shader, your compute shader, or even your ray generation shader. No context switch, no intermediate buffers, no framework overhead. The GPU’s tensor acceleration hardware is accessed directly through HLSL intrinsics, and the driver handles the low-level scheduling of cooperative operations across wave threads.
Neural Rendering Use Cases: Texture Compression and Radiance Caching
Two neural rendering applications stand out as the most immediately practical, both highlighted extensively during Microsoft’s GDC 2026 session on evolving DirectX for the ML era.
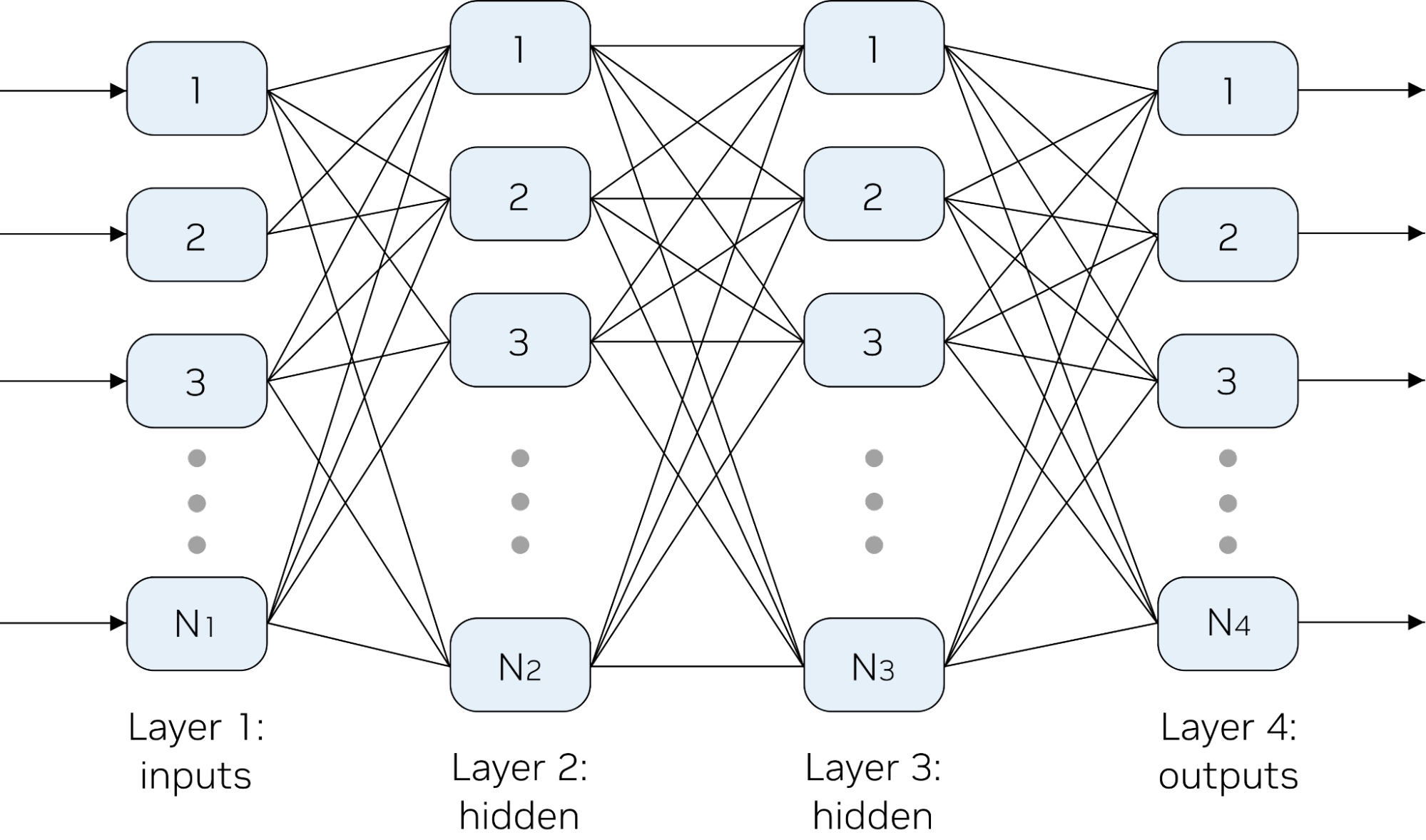
Neural Texture Compression. Traditional block compression formats like BC7 achieve roughly 4:1 compression ratios with acceptable quality for most use cases. But as games push toward 4K and 8K textures, memory bandwidth becomes a critical bottleneck — particularly on consoles and mobile GPUs. Neural texture compression replaces the fixed decompression algorithm with a small neural network (typically 2-3 layers with 8-16 neurons per layer) that decodes texture data at sampling time. The compression ratio can be dramatically higher — some research shows 16:1 or even 32:1 with quality comparable to BC7 at 4:1. With Cooperative Vectors, this neural decompression runs inline during texture sampling, adding minimal latency to the rendering pipeline.
Neural Radiance Caching. Global illumination remains one of the most computationally expensive aspects of realistic rendering. Path tracing produces beautiful results but requires thousands of rays per pixel for noise-free images. Neural radiance caching uses a small neural network to approximate indirect lighting contributions, trained on-the-fly from a sparse set of path-traced samples. Instead of tracing hundreds of secondary rays, the shader queries the neural cache for an approximate radiance value — achieving plausible global illumination at a fraction of the computational cost. This technique was already demonstrated by NVIDIA in their research, but Cooperative Vectors make it accessible through a standardized, cross-vendor API for the first time.

The Bigger Picture: DirectX Linear Algebra and Compute Graph Compiler
Cooperative Vectors in SM 6.9 are just the first step. Microsoft’s roadmap reveals two additional components that will complete the neural rendering stack.
DirectX Linear Algebra (DXLA). As noted in the Shader Model 6.9 future roadmap blog post, Cooperative Vectors is being deprecated in favor of a unified linear algebra design that combines both vector-matrix and matrix-matrix operations under a single, more flexible API. DXLA enters public preview in April 2026 and will ship in a future Shader Model release. The unification means developers won’t need to choose between different operation types — the driver and hardware will automatically select the most efficient execution path based on the specific workload.
DirectX Compute Graph Compiler. While DXLA handles individual linear algebra operations, the Compute Graph Compiler operates at a higher abstraction level. It takes an entire ML model graph — defined in a standard format like ONNX — and compiles it into optimized native GPU code. Think of it as a JIT compiler for neural networks, but one that understands GPU hardware intimately. Scheduled for private preview in summer 2026, this tool will eventually allow game developers to deploy complex neural rendering pipelines without writing low-level shader code for each operation. Define your model, feed it to the compiler, and get GPU-native performance.
The strategic implication is clear: Microsoft is embedding ML inference into the operating system’s graphics API at the lowest possible level. Not through a high-level framework that sits on top of DirectX, but through DirectX itself. This minimizes latency and overhead in ways that third-party solutions simply cannot match. And with all four major GPU vendors committed to supporting these APIs, it’s effectively an industry-wide standardization of neural rendering infrastructure.
Beyond ML: GDC 2026’s Other DirectX Announcements
The ML story was the centerpiece, but GDC 2026 delivered several other significant DirectX updates worth noting. DirectStorage gains Zstandard compression support, further reducing game load times. PIX, Microsoft’s GPU debugging tool, received what the company called its biggest update in 10 years, bringing console-level GPU profiling capabilities to Windows PC development. And perhaps most impactful for everyday gamers, Advanced Shader Delivery introduces a mechanism for distributing precompiled shaders through game storefronts — directly addressing the shader stutter problem that plagues many PC game launches.
According to WCCFTech’s coverage, Microsoft also teased DXR 2.0, though details remain scarce. Given the trajectory of Cooperative Vectors and DXLA, it’s reasonable to expect that DXR 2.0 will natively integrate neural rendering capabilities into the ray tracing pipeline — making techniques like neural radiance caching first-class citizens rather than bolt-on additions.
The AMD partnership deserves mention as well. AMD’s collaboration through GPUOpen confirms cross-vendor commitment to DirectX ML and DirectX Linear Algebra. This isn’t an NVIDIA tensor core exclusive — AMD’s AI accelerators, Intel’s XMX engines, and Qualcomm’s NPUs will all expose Cooperative Vector capabilities through the same standardized API. For developers, this means writing neural rendering code once and having it run efficiently across all major GPU architectures.
What Developers Should Do Right Now
It’s too early to ship production code on SM 6.9’s neural rendering features, but the roadmap is clear enough to start preparing. SM 6.9 retail is live now via Agility SDK 1.619. DXLA public preview arrives in April 2026. Compute Graph Compiler enters private preview in summer 2026. By late 2027, major game engines will likely integrate these capabilities as standard features.
The immediate action items: install the Agility SDK, experiment with Long Vectors and 16-bit float special functions, and prototype a neural texture compression pipeline. Start with something small — a two-layer neural network with 16 neurons per layer, running inline in a pixel shader via Cooperative Vectors. This will give you hands-on experience with both the capabilities and the current limitations of the API. Pay attention to how the DXC compiler handles Long Vector code generation, and profile the actual tensor core utilization on your target hardware.
The bottom line: DirectX ML Shader Model 6.9 and Cooperative Vectors represent the first concrete, shipping implementation of inline neural rendering in a standardized graphics API. Neural texture compression, neural radiance caching, and techniques we haven’t imagined yet will run natively inside GPU shaders. With DirectX Linear Algebra and Compute Graph Compiler completing the stack over the next 12-18 months, real-time graphics is entering its third major paradigm — after rasterization and ray tracing, the age of neural rendering has officially begun.
Building GPU-accelerated pipelines or exploring neural rendering integration for your project? Sean Kim can help with technical consulting and automation architecture.
Get weekly AI, music, and tech trends delivered to your inbox.